상태는 Running, 그런데 데이터는 없다
평범한 토요일 오전, 갑자기 옆 팀 스노우 플레이크 담당자 분이 연락을 받게 됩니다.
"어제자 새벽부터 스노우 플레이크에 저번 주 추가한 북미 쪽 데이터가 들어오지 않아요"
지난주 신규 서비스가 런칭되면서 평균 8만 명의 유저가 초당 약 3MB/s 수준의 데이터를 쏟아내고 있었고, 이와 관련된 모든 로그는 Kafka 클러스터로 유입되는 구조였습니다. 로그의 파이프라인은 MySQL 기반의 로그 DB에 적재된 후, Debezium CDC를 통해 Kafka로 전송되고, 이후 Snowflake로 전달되는 구조로 그리 어렵지 않은 구조의 파이프라인이였습니다.
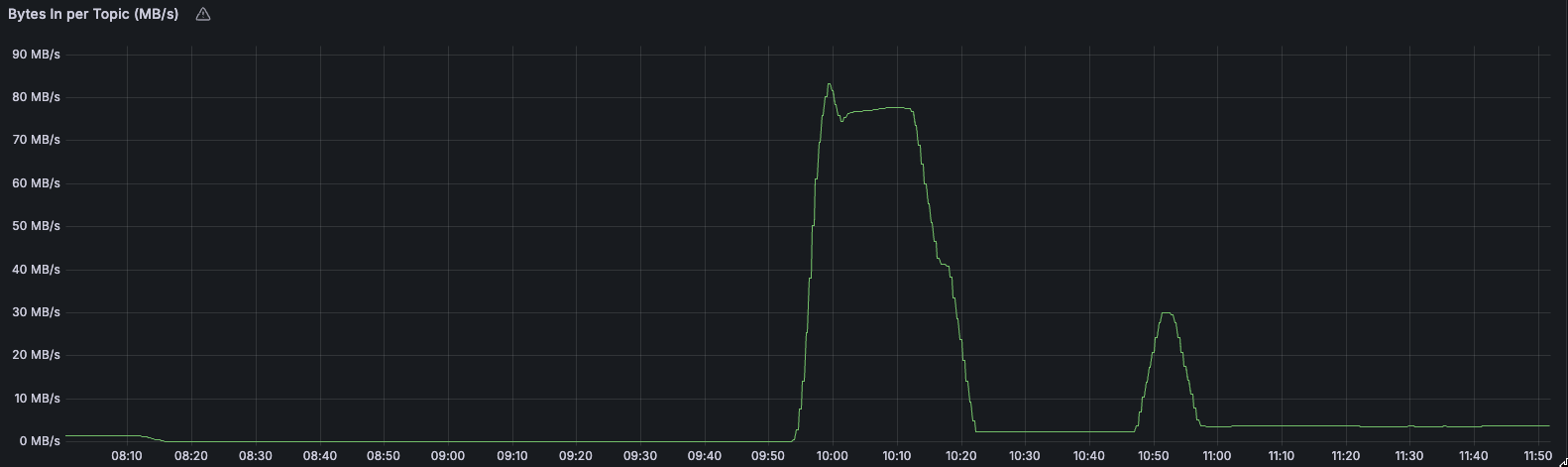
다시 문제로 돌아가 보면, 핵심은 결국 CDC 커넥터가 정상적으로 데이터를 가져오지 못했다는 점입니다. 토픽별 메시지 생산량을 확인해보니, 문제가 발생했던 새벽 시간부터 Debezium CDC가 데이터를 전혀 생산하지 않고 있었고, Kafka 토픽에 데이터가 쌓이지 않다 보니 Snowflake Sink 쪽에서도 더 이상 처리할 데이터가 없는 상태였습니다.
다소 이상했던 점은 무언가 문제가 있음은 분명했으나 Connector 상태를 확인해보면 Running, 개별 Task의 상태를 확인했을 때에도 마찬가지로 Running이였다는 점이였습니다. 빠르게 문제를 인지하지 못했던 이유도 여기 있었는데요. 당초 모니터링을 추가할 때 Connector 쪽 모니터링은 Task의 상태 변화를 중심으로 구성이 되어 있었기에, Running이면서 데이터가 전송되지 못하는 해당 케이스 같은 경우는 감지하지 못했던 문제가 있었습니다 (해당 케이스 이후로는 반드시 들어와야 하는 토픽에 데이터가 일정 시간 들어오지 못하는 케이스를 모니터링에 추가하게 되었습니다).
로그(connect.log와 브로커 쪽 server.log)도 살펴보았으나, 딱히 뚜렷한 문제점을 찾지 못했습니다. 굳이 언급하자면 해당 시점 이후로 관련된 로그들이 싹 사라졌다는 점 정도를 꼽을 수 있었겠네요. (뒤에 언급하겠지만, 이 부분을 주목했다면 문제를 조금 더 빨리 찾아낼 수 있었을 거 같습니다)
우선 문제를 해결하기 위해 바로 노트북을 열고, 최우선적으로 커넥터 restart를 시도하였습니다. 이름을 변경하여 새로운 커넥터를 띄우는 것도 고려사항에 있었으나 이름을 변경하는 순간 아예 새로운 connector로 인식하게 되기 때문에 debezium 메타데이터 (스키마, 오프셋 등)이 초기화되어 그간의 데이터가 통으로 유실되기에 정말 최후의 수단으로만 남겨두었고, 재시작을 시도하며 앞으로 착한일 많이 하고 살테니 정상 상태로 돌아와만 달라고 기도했습니다 (ㅠㅠ)
다행히 3번 정도 재시도를 시도한 이후에야 정상적으로 데이터가 흐르는데 성공하였고, 데이터가 흐르기 시작하자 최대 5 mb/s를 넘지 않았던 메세지 생산량이 순간 100 mb/s 가까이 치솟기도 하였습니다.
재시작을 하게 되면 다소 특이한 점은 기존 연결이 끊어지지 않고, 앞선 연결이 계속 유지가 된다는 점이였습니다. 그렇다면 데이터 전송이 두번되어서 중복을 발생시키느냐라고 한다면 ... 그것도 아닌게 계속 대기만 합니다. 마치 binlog의 변경 사항을 적절하게 캡쳐하지 못하는 식으로요.
아래는 실제 DB 내 information_schema.processlist를 통해 조회한 예시입니다. 재시작을 하게되면 동일한 역할을 수행하는 CDC 유저가 하나 더 붙게 되어 (time_sec이 26) 멈춰있던 데이터 생성을 재개하지만, 기존에 멈춰있던 CDC 유저 또한 제거되지 않고 계속 대기 상태에 머무릅니다.
| user | host | command | time_sec | state |
| cdc 유저명 | xxxx | Binlog Dump | 65198 | Source has sent all binlog to replica; waiting for more updates |
| cdc 유저명 | xxxx | Binlog Dump | 26 | Sending binlog event to replica |
당장 없애지 않는다고 문제는 발생하지 않는 것으로 보였으나, 지저분한 연결은 수동으로 kill 해주는 식으로 정리를 수행했습니다.
단순 재시작만으로도 이슈는 일시적으로 해소되었다고 안심했지만 ... 이때부터였습니다. 평일/주말, 밤낮 가리지 않고 문제가 시작되었던 것은 ...
카프카 설정 값을 튜닝하면 해결할 수 있지 않을까?
로그 상에 명확한 원인이 드러나지는 않았지만, DB는 북미에 위치하고 카프카 클러스터는 한국에 있는 구조였기 때문에, 물리적 거리로 인한 네트워크 지연이 문제가 되었을 가능성을 가장 먼저 의심하였습니다. 실제로 동일한 서비스를 한국 내에서 운영할 때는, 오히려 더 많은 양의 로그를 카프카로 전송하고 있음에도 불구하고 이와 같은 문제는 발생하지 않았습니다. 또한 과거에 싱가포르와 일본 지역에서 비슷한 증상이 아주 간혹 발생한 사례가 있었고, 그때마다 CDC 커넥터 재시작을 통해 문제를 일시적으로 해결한 경험이 있습니다. 다 합쳐 리전 당 1 ~ 2회 정도 정말 가끔 발생하였기에 대수롭지 않게 넘겨왔었는데, 이번 사례의 경우, 이전 지역들보다 훨씬 자주 동일한 현상이 반복되었고 문제가 발생한 서비스가 북미 리전에 위치해 있었고, 물리적 거리가 멀어질수록 해당 문제가 더 빈번하게 발생하는 경향이 있다는 판단에 무게를 두게 되었습니다.
그간 다양한 설정들을 조정해보았고, 일부 개선이 있는 것도 있었으나 옵션 조정을 통해 근본적으로 문제를 해결할 수는 없었습니다.
대표적으로 아래와 같은 파라미터를 튜닝해보았습니다.
Producer 설정 관련
| 설정 항목 | 기본값 → 조정값 | 의도한 개선 포인트 |
| producer.buffer.memory | 32MB → 64MB | 전송 대기 중인 메시지를 더 많이 담아 버퍼 부족에 의한 블로킹 방지 |
| producer.max.block.ms | 60초 → 120초 | 버퍼가 가득 찼을 때 프로듀서가 기다릴 수 있는 시간을 늘려 일시적 병목 완화 |
| producer.delivery.timeout.ms | 2분 → 4분 | 브로커 응답 지연이나 재시도 등으로 인한 메시지 전송 실패 방지 |
| producer.request.timeout.ms | 30초 → 60초 | 네트워크 지연 환경에서 브로커 응답을 기다릴 수 있는 시간 확보 |
내부 Queue 설정 관련
| 설정 항목 | 기본값 → 조정값 | 의도한 개선 포인트 |
| max.queue.size | Connector 내부 큐의 최대 이벤트 수 | 기본 2048 → 8192 |
| max.batch.size | Kafka로 보낼 최대 이벤트 수 | 기본 2048 → 작게 조정 (1024) |
| poll.interval.ms | DB에서 변경 이벤트를 폴링하는 주기 | 기본 500ms → 1000ms |
위와 같이 설정을 조정하면서 지연 환경에서의 타임아웃 방지, 버퍼 과부하 해소, 메시지 손실 최소화 등을 기대했으며, 일부 설정은 단기적으로 효과를 보이기도 하였습니다만 ...
그리 오래지나지 않아 또 다시 밤낮을 가리지 않고 동일한 문제가 발생하였습니다.
이슈가 쉽게 해결되지 않자, 우선적인 대응책으로 알림이 감지되면 커넥터를 자동으로 재시작하는 작업을 백그라운드에서 실행하도록 구성했습니다.
재시작 로직은 다음과 같이 동작합니다:
1. 알림(Alert)이 들어오면, 백그라운드에서 최대 3회까지 커넥터 재시작을 시도합니다.
2. 이 과정에서 중간에 메시지가 정상적으로 수신되면, 재시작 시도를 즉시 중단합니다.
이렇게 구성함으로써 우선 문제 해결까지의 시간을 벌고, 주말과 새벽 시간에도 수동 개입 없이도 일정 수준의 자동 복구가 가능하도록 만들었습니다.
결국은 또 버그였다 ...
앞서 재시작 시 연결이 지저분하게 남는다고 언급을 드렸는데요. 관련해서 CDC 쪽 설정 값에 문제가 있는지 살펴보던 참이였습니다. 근데 이상한 건 동일한 커넥터를 약 1년 가까이 일본과 싱가폴 리전에서 운영하였으나 문제가 없었는데 카프카 버전을 올린 후부터 문제가 발생하였다는 점이였습니다.
처음에는 카프카 버전과 CDC 커넥터 버전을 올린게 생각나, 버전 문제인지를 의심하였고 CDC 설정 쪽이 버전이 올라감에 따라 변경된 부분이 워낙 많기에 이를 중점적으로 살펴보고 있던 참이였습니다.

이번 CDC 연결 이슈를 추적해보면서 흥미로운 공통점을 발견할 수 있었습니다.
문제가 발생한 대부분의 환경이 Aurora MySQL 3 (MySQL 8.x 기반) 을 사용하고 있었고, 클라이언트 측에서는 Java 17 이상 버전이 함께 사용되고 있다는 점이었습니다.
Aurora 3는 기본적으로 TLS/SSL을 통한 인증 연결을 강제하고 있으며, 특정 Java 버전(특히 Java 17+ 이상)에서는 TLS 처리 방식이 달라지면서, socker.close()를 호출해도 연결이 정리되지 않거나(graceful하게), Binlog 스트림이 끊기지 않는 현상이 간헐적으로 발생하는 것으로 보입니다. 즉 일종의 특정 버전의 자바에서 소켓을 적절하게 종료하지 못하는 버그인 것이죠.
실제로 이와 유사한 문제가 Debezium 내부에서 사용하는 mysql-binlog-connector-java 라이브러리의 GitHub 이슈에 보고된 바 있음을 확인하였습니다.
아래와 같이 Connector 측에서 별도 설정을 하지 않는다면, 연결은 TLS/SSL로 구성됨을 확인하였습니다.
SELECT
sbt.variable_value AS tls_version,
t2.variable_value AS cipher,
t.processlist_user AS user,
t.processlist_host AS host,
t.processlist_command AS command,
t.processlist_time AS time_sec,
t.processlist_state AS state
FROM
performance_schema.status_by_thread AS sbt
JOIN
performance_schema.threads AS t
ON t.thread_id = sbt.thread_id
JOIN
performance_schema.status_by_thread AS t2
ON t2.thread_id = t.thread_id
WHERE
sbt.variable_name = 'Ssl_version'
AND t2.variable_name = 'Ssl_cipher'
AND t.processlist_user = 'cdc 유저명'
ORDER BY
time_sec DESC;| tls_version | cipher | user | host | command | time_sec | state |
| TLSv1.3 | TLS_AES_256_GCM_SHA384 | cdc 유저명 | xxxx | Binlog Dump | 966814 | Source has sent all binlog to replica; waiting for more updates |
| TLSv1.3 | TLS_AES_256_GCM_SHA384 | cdc 유저명 | xxxx | Binlog Dump | 1 | Sending binlog event to replica |
이처럼 Aurora 3 환경에서는 별도 설정이 없다면 tls 연결을 사용하고 있음을 확인할 수 있습니다.
이를 해결하기 위한 방법 중 하나로는, Debezium 커넥터 설정에서 use.nongraceful.disconnect=true 옵션을 적용하는 것이 있습니다. 이 설정은 내부적으로 Socket.setSoLinger(true, 0)를 적용하여, 연결 종료 시 TCP FIN 대신 RST 패킷을 보내며 소켓을 즉시 끊도록 구성합니다. 이러한 방식은 지연 환경에서의 무한 대기나 소켓 종료 실패를 방지할 수 있는 핵심 대응책이 됩니다.
물론, 또 다른 해결 방안으로는 Java 버전을 문제가 생기지 않는 상위 마이너 버전으로 조정하여 TLS 핸들링 방식을 우회하는 것도 생각해볼 수 있겠지만, 운영 환경에서 JVM 버전을 조정하는 것은 현실적으로 적용하기 어렵고 부작용 가능성도 높아 선택지에서 제외하였습니다.
결국 저는 가장 단순하면서도 확실하게 TLS/SSL을 사용하지 않도록 변경하는 형태로 문제를 해결하였습니다. 사실 내부망 내에서 이뤄지는 통신이기에 굳이 TLS/SSL 통신이 굳이 필요한 것은 아니였거든요.
HTTP로 연결을 바꾸는 방법은 아래 설정으로만 변경해주면 됩니다.
"database.ssl.mode": "disabled"
워낙에 검색해도 안나오는 문제인지라 문제 파악에만 시간을 다 써버린 다소 김 빠지는 이야기지만, 혹 비슷한 이슈를 겪으실 다른 분들을 위해서 글을 작성합니다.Aurora 3 환경에서 지연이 높은 서비스를 운영하시는 분들도 같은 이슈를 마주한다면 혹시 https 연결을 사용하고 계시진 않은지 한번쯤 확인해보셔도 좋을거 같습니다.