2022. 10. 26. 03:44ㆍArchieve/Data Engineering
해당 글에서는 S3에 위치한 데이터를 Glue 크롤러를 통해 S3에 위치한 CSV 파일을 Data Catalog Database로 이동시키는 것을 목표로 한다.
본격적인 글 작성에 앞서서 Glue의 Job을 생성하거나 이후 Athena를 통해 데이터 추출 작업을 용이하게 수행하기 위해서는 Glue의 Data Catalog Database를 해당 데이터의 스키마와 함께 저장해야할 필요가 있다. 물론 S3를 통해서 바로 작업이 가능한 경우도 많지만, 작업이 그리 복잡하지 않으므로 필요하다면 Data Catalog를 활용하는 것이 좋아보인다.
데이터 소개

1786373 개의 row와 34 개의 Column 값을 가지고 있으며, 약 483 MB의 크기를 가진 CSV 파일이다. 내부 데이터는 한글과 숫자, 영어가 모두 들어가 있으며 UTF-8로 인코딩이 되어 있다. 데이터의 크기가 어느정도 크기 때문에 엑셀로는 파일이 열리지 않으며, Athena를 통해 SQL 쿼리를 통해 데이터를 확인해야 한다.
Glue 소개
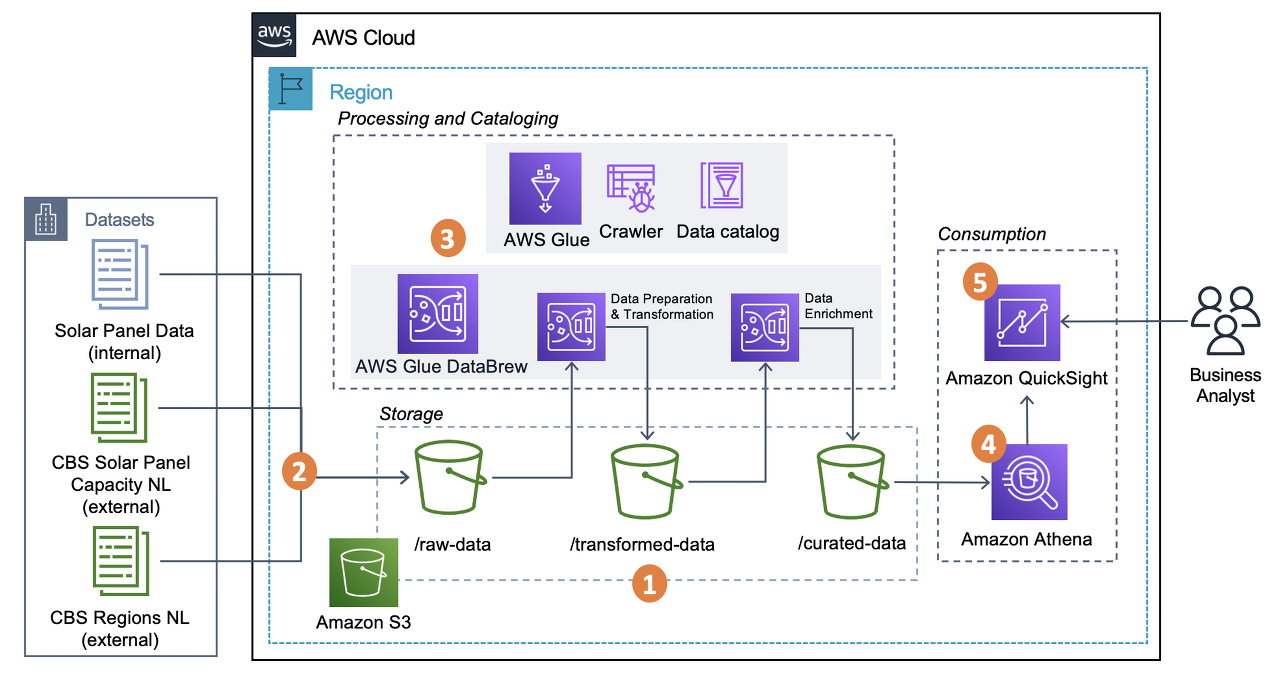
AWS 글루(Glue)는 자동 추출, 변환 및 로드(ETL) 프로세스를 통해 분석 데이터를 준비하는 서버리스 데이터 서비스이다. S3, RDS, Glue data catalog와 같은 다양한 소스로부터 원천 데이터를 받아와 해당 데이터의 변환 작업을 진행한 후, 결과물을 Load하는 식으로 프로세스가 진행된다.
Glue Data Catalog 소개
Data Catalog를 활용한다면 다양한 원천 데이터를 하나의 중앙 집중식 데이터 카탈로그로부터 관리할 수 있게 된다. 주로 Database로 관리가 이뤄지며, Crawler를 통해 해당 데이터의 메타데이터 추론과 함께 S3와 같은 다양한 원천으로부터 데이터를 추출할 수 있다.
이제 본격적으로 작업을 진행해보자.
Step 1. Data Catalog DB 생성
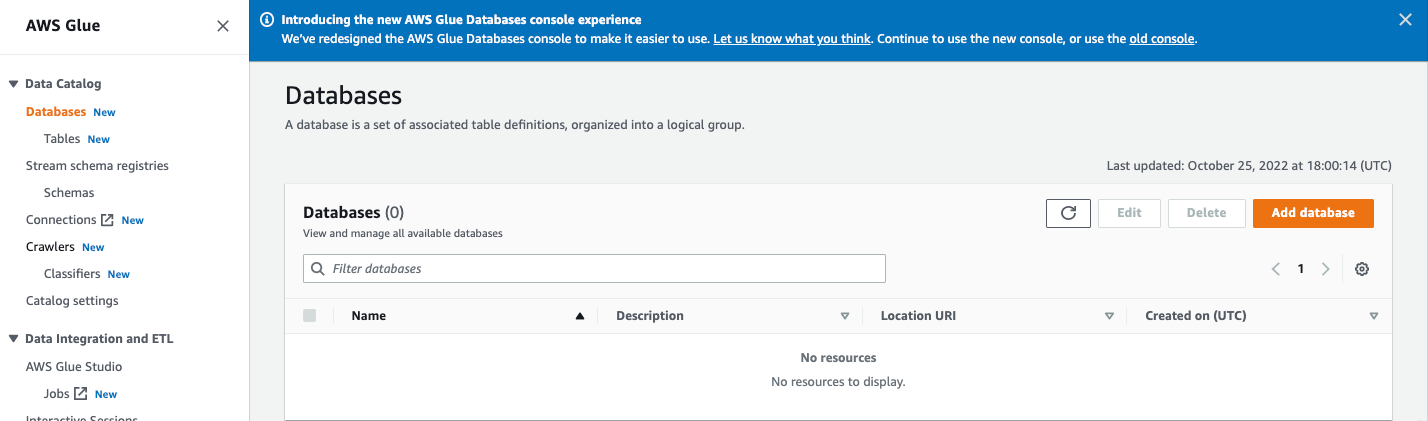
AWS 검색창에 Glue로 들어가, Data Catalog 하단의 Database로 들어간다. Add database 를 선택한다.

Name만 지정해주고, 그 외의 Location과 Desciption은 필요에 따라 작성해준다.
Step 2. Data Catalog Crawler를 사용하기 위한 권한 준비

IAM을 검색해 들어가 역할로 들어간 후 역할 만들기 선택

신뢰할 수 있는 엔터티 유형 중 AWS 서비스 선택한다. 사용 사례란에는 다른 AWS 서비스 사용 사례 중 Glue 검색 후 선택하면 된다.

이후 AdministratorAccess를 선택하여 Glue에서 모든 조작을 할 수 있는 권한을 부여한다.
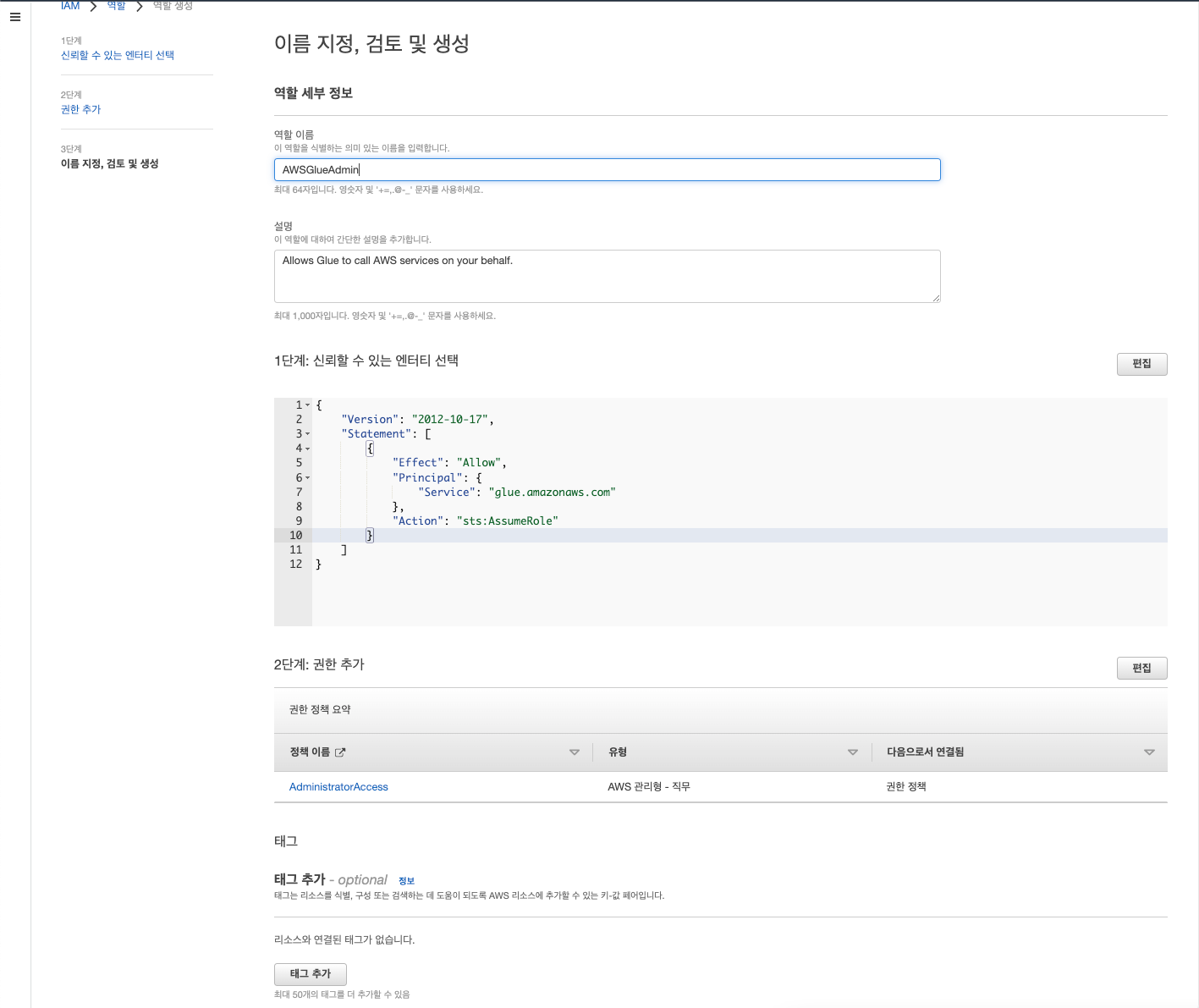
이후 이름을 작성해주며 역할을 생성한다.
정책을 새롭게 작성하며 POLP를 준수하면 베스트이겠으나 해당 글에서는 권한에 대해서는 자세히 다루지 않겠다.
Glue Data Crawler 생성
역할이 정상적으로 생성되었음을 확인했다면 다시 Glue로 돌아가 Crawlers로 들어간다.

Create Crawler를 선택하고 크롤러의 이름을 먼저 작성한다.

Step 2에서는 다양한 원천 데이터를 선택할 수 있다. 현재 목표는 하나의 원천 데이터만이 존재하므로 단순히 해당 데이터만을 추가한다.
먼저 아직 작성된 Glue Data Catalog 테이블이 존재하지 않으므로, Not yet을 선택해준다.
Data Sources의 Add a data source를 선택할 경우, Data Source, Network connection, S3 Path 등을 지정해줄 수 있다.

먼저 가져오고자 하는 데이터의 소스를 지정해준다. 앞서 소개한 데이터는 S3에 위치하고 있으므로 이를 선택해주었다.
Network connection 같은 경우에는 당장은 필요가 없으나, 필요한 경우에는 기존 VPC로부터 엔드포인트를 추가해준 다음, 새로운 connection을 생성 후 등록하는 방식으로 사용할 수 있다.
S3 Path에는 목표로 하는 데이터의 상위 폴더를 지정해준다. 해당 파일만을 지정해주는 경우 크롤러의 실행은 정상적이였으나 테이블이 생성이 되지 않음을 확인했다. 현재 목표로 하는 데이터의 S3 URL은 ecomm_fc_transformed/ecomm_fc_transformed.csv이다.
아래 크롤링 정책은 현재 달성하고자 하는 목표와 부합하므로 유지한다.

앞서 생성해주었던 역할을 부여한다. (이름이 조금 다르지만, 앞서 생성한 역할과 동일하다.)

마지막으로 맨 처음에 생성했던 Database를 선택해준다. 생성이 되지 않았다면 Add database를 통해서도 생성이 가능하다. (현재 데이터베이스에는 아무런 스키마 정보가 주어져있지 않으며 이름만 부여되어 있는 상태이다.)
이후 리뷰 후 크롤러 생성을 마무리한다.
Step 3. 크롤러 실행
크롤러가 정상적으로 생성되었다면, crawlers 초기 페이지로 다시 돌아가면, 앞서 생성한 크롤러를 확인할 수 있다. 그럼 이제 해당 크롤러를 선택하고 Run을 눌러 실행해보자.
약 3분 이상의 시간이 걸린 후, 다음과 같은 Success 메세지를 확인하면 크롤러가 정상적으로 실행되었음을 확인할 수 있다.

이후 Database의 Table에 들어가 정상적으로 크롤링 결과가 반영되었는지 확인한다.

다음과 같이 테이블이 생성이 되었다면 성공적으로 해당 작업이 마무리되었음을 알 수 있다.
'Archieve > Data Engineering' 카테고리의 다른 글
| Zookeeper의 znode (0) | 2023.05.18 |
|---|---|
| Coursera 데이터 엔지니어링 강의 목록 (0) | 2022.12.08 |
| Spark (0) | 2022.11.20 |
| 로그 데이터 수집 (0) | 2022.11.18 |
| [에러 노트] AWS Data Crawler로 생성된 DB의 스키마가 업데이트 되지 않는 경우 (0) | 2022.10.26 |