
스파크 소개
스파크는 통합 컴퓨팅 엔진으로서 클러스터 환경에서 데이터를 병렬적으로 처리하는 라이브러리 집합입니다. 스파크는 파이썬, 자바, 스칼라, R을 지원하며 단일 노트북 환경에서 수천 대의 서버로 구성된 클러스터에 이르기까지 다양한 환경에서 실행할 수 있습니다. 이러한 특성을 활용하여 스칼라를 통해 빅데이터를 용이하게 처리하는 동시에 엄청난 규모의 클러스터로 확장시켜 나갈 수 있습니다.
스파크는 원래 UCLA, Berkeley에서 개발되었으며 이후 Apache Software Foundation에 기부되었습니다. 또한 2014년 2월에 최상위 Apache 프로젝트가 되었고, 지금까지 수천 명의 엔지니어가 Spark에 기여하여 현재는 빅데이터 플랫폼을 구성하는 주요한 오픈소스로 자리잡았습니다.
Apache Spark는 Scala, Python, R 및 Java를 지원하는 프레임워크라고 할 수 있습니다. 이때 스파크는 언어에 따라 다양한 구현이 있습니다.
- Spark - Scala 및 Java용 기본 인터페이스
- PySpark - Spark용 Python 인터페이스
- SparklyR - Spark용 R 인터페이스
스파크 특징
- 인-메모리 연산
- 병렬화를 통한 분산 처리
- 다양한 클러스터 관리자 (Spark, Yarn, Mesos) 지원
- 내결함성
- 불변성 (RDD)
- Lazy Evalution을 통해 계산 효율성 증대
- Cache와 Persistence를 통한 효율적인 데이터 가공
- ANSI SQL을 지원
스파크 장점
- Spark는 범용 오픈소스로서 인메모리 연산, 내결함성 등의 특징과 함께 분산 프로세싱 엔진을 통해 데이터를 효율적으로 처리한다.
- Spark 내부에서 실행되는 애플리케이션은 전통적인 방식의 애플리케이션보다 약 100배 빠르다.
- Data Ingestion pipeline 구성 시에 Spark를 활용한다면 많은 장점을 얻을 수 있다.
- HDFS, AWS S3, Databricks DBFS, Azure Blob Storage 등과 같은 다양한 소스로부터 들어온 데이터를 처리할 수 있다.
- Kafka 등을 활용한 실시간 데이터 처리 프로세스에서도 활용이 가능하다.
- Spark Streaming을 통해서 파일 시스템으로부터 파일 stream을 구성할 수도 있고, 소켓으로부터도 stream을 구성할 수 있다.
- Spark는 자체적으로 ML과 그래프 관련 라이브러리들을 내장한다.
💡 Spark의 내결함성(Fault Tolerance)을 가능하게 하는 강력한 기능으로 RDD가 있습니다. 이는 이후 RDD를 다루며 다시 소개하도록 하겠습니다. https://hevodata.com/learn/spark-fault-tolerance/#t2
💡 내결함성: 구성 요소 중 일부가 실패하거나 그 안에 하나 이상의 결함이 있는 경우에도 시스템이 계속 제대로 작동하는 기능
스파크의 철학
스파크는 빅데이터 애플리케이션 개발에 필요한 통합 플랫폼을 제공하자라는 핵심 목표를 가지고 있습니다. 여기서 말하는 통합이란 간단한 데이터처리에서 SQL 처리, 머신러닝 그리고 스트리밍 데이터 처리에 이르기까지 다양한 데이터 분석 작업을 Spark라는 단일 엔진과 이를 통해 제공되는 API로 수행할 수 있도록 하는 것을 의미합니다.
때문에 스파크를 활용하게 되면 일관성있는 조합형 API를 제공하게 되므로 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있습니다. 조합형 API 만으로 문제를 해결할 수 없다면, 직접 스파크 기반의 라이브러리를 통해 문제를 해결할 수도 있습니다.
스파크의 API는 서로 다른 라이브러리의 기능을 조합하여 기존 라이브러리를 사용하는 것보다 더 나은 성능을 제공하게 됩니다. 예를 들어 SQL 쿼리로 데이터를 읽고 ML 라이브러리로 머신러닝 모델을 평가해야 하는 경우, 스파크 엔진은 이 두 단계를 하나로 병합하여 데이터를 한 번 조회하는 것만으로도 작업을 완료할 수 있습니다.
스파크가 있기 전에는 개발자가 직접 다양한 API와 시스템을 조합하여 애플리케이션을 작성해야 했습니다. 그러나 스파크가 발표된 이후 스파크의 통합 엔진을 통해 개발자의 번거로움이 상당부분 해소되었고, 시간이 지남에 따라 더 많은 처리 유형을 지원하기 위해 API가 지금도 늘어나고 있습니다.
컴퓨팅 엔진
스파크는 통합이라는 철학 아래에 기능의 범위를 컴퓨팅 엔진으로 제한해왔습니다. 때문에 스파크는 저장소 시스템의 데이터를 연산하는 역할을 수행할 뿐 영구 저장소의 역할을 수행하지 않습니다. 앞서 언급하였듯 다양한 저장소(Azure blob storage / S3 / Hadoop 등)를 지원합니다. 이는 스파크의 장점 중 하나로 설명할 수 있습니다. 스파크는 특정 저장소에 종속되지 않기 때문에 어떠한 저장소를 사용하더라도 문제가 되지 않습니다. 실제 비즈니스 레벨의 데이터 파이프라인의 경우 다양한 소스로부터 데이터를 처리할 수 있어야 합니다. 이 경우 스파크를 활용한다면 손쉽게 문제를 해결할 수 있습니다.
실제 사용자 API 또한 이를 고려하여 서로 다른 저장소 시스템을 구분하지 않고 유사하다고 인식하게 되며, 따라서 애플리케이션은 데이터가 저장된 위치를 고려하지 않아도 됩니다.
저장소로부터 데이터를 받은 이후 스파크에서는 연산을 빠르게 수행하기 위해 In-memory 연산을 수행합니다. 때문에 스파크 내에서는 데이터가 오래 머물지 않으며 데이터의 저장 위치에 상관 없이 온전히 처리에 집중할 수 있게 되었습니다.
이는 기존의 아파치 하둡과 같은 빅데이터 플랫폼과의 차별화 포인트가 됩니다. 하둡은 범용 서버 클러스터 환경에서 저비용 저장 장치를 사용하도록 설계된 HDFS와 mapReduce를 가지고 있으며 두 시스템은 밀접한 관계를 가지고 있습니다. 이때 하둡과 같은 구조에서는 둘 중 하나의 시스템 만을 단독으로 사용하기가 어렵습니다. 특히 하둡만을 사용한다면 다른 저장소에 위치한 데이터에 접근하는 애플리케이션을 개발하는 것이 어려워집니다. 스파크는 HDFS와도 잘 호환되며, 하둡을 사용할 수 없는 다양한 환경에서도 사용이 가능합니다.
스파크의 등장 배경
역사적으로 컴퓨터는 프로세서의 성능 향상에 따라 매년 빨라졌습니다. 그 결과 코드 수정 없이도 애플리케이션의 성능도 자연스럽게 올라가게 되었습니다. 대규모 애플리케이션은 이런 경향성과 함께 개발되어 왔으며 과거 대부분의 시스템은 단일 프로세서에서만 실행되도록 설계되었습니다.
그러나 하드웨어의 성능 향상은 2005년 경에 멈추게 되었으며(물리적인 방열 한계로 인해), 단일 프로세서의 성능을 증가시키기 보다 모든 코어가 같은 속도로 동작하는 병렬 CPU 코어를 더 많이 추가하는 방향으로 선회했습니다. 이는 곧 애플리케이션의 성능 향상을 위해서는 앞으로 병렬 처리가 필요하며 스파크와 같은 새로운 프로그래밍 모델의 세상이 도래할 것임을 암시하게 됩니다.
프로세서의 성능이 개선되진 않았으나 데이터 저장과 수집 기술은 계속 발전해왔기에 눈에 띄게 느려지지 않았으며 1TB 가량의 데이터를 저장하는데 대략 14개월마다 비용이 절반으로 줄고 있었으며, 때문에 조직 규모와 관계없이 대규모의 데이터를 저렴하게 저장할 수 있었습니다.
결과적으로 데이터의 수집 비용은 극히 저렴해졌으나 데이터는 클러스터를 거쳐야만 처리할 수 있을 정도로 거대해졌으며, 과거 프로세서의 성능 향상으로 인해 애플리케이션이 코드 한줄 변화 없이도 성능이 향상되었던 것과 달리 이제는 소프트웨어 측면에서 다양한 개선이 요구되게
스파크 구조
Apache Spark는 마스터 노드를 Driver라고 하고 슬레이브 노드를 Worker라고 합니다. 스파크 클러스터는 앞선 두 요소로 이뤄진 마스터-슬레이브 아키텍쳐에서 작동합니다. Spark 애플리케이션을 실행할 때 Spark Driver는 애플리케이션에 대한 진입점인 컨텍스트를 생성하고 실제 모든 작업은 작업자 노드에서 실행됩니다.

이때 Driver 노드에서 실행된 Driver 프로세스는 Worker 노드에 위치한 Executor 프로세스에 작업을 할당 및 지시하게 됩니다. Executor 프로세스 내부에는 처리해야하는 여러 작업이 있으며, 작업을 좀 더 빠르게 수행하기 위한 캐시를 가지게 됩니다.
클러스터 관리자에서는 실제 사용 가능한 자원을 파악하며, 하드웨어 자원을 관리하게 됩니다.
이어지는 이미지를 통해 스파크에서 제공하는 전체 컴포넌트와 라이브러리 구조를 확인할 수 있습니다.
클러스터 관리자 유형
앞서 특징에서 언급하였듯 스파크는 다양한 클러스터 관리자를 지원합니다. 아래는 그 목록입니다.
- Standalone - Spark에 포함된 간단한 클러스터 관리자를 통해 클러스터를 간단하게 설정할 수 있습니다.
- Apache Mesos - Hadoop MapReduce 및 Spark 애플리케이션도 실행할 수 있는 클러스터 관리자입니다.
- Hadoop YARN - Hadoop 2의 리소스 관리자입니다. 빅데이터 플랫폼을 구성할 경우 HDFS를 사용한다는 전제 하에 가장 자주 사용되는 클러스터 관리자입니다.
- Kubernetes - 컨테이너화된 애플리케이션의 배포, 확장 및 관리를 자동화하기 위한 오픈 소스 시스템입니다.
- Local - 주로 실습 환경에서 사용되는 로컬 클러스터입니다. 옵션을 통해 코어 수를 조절할 수 있습니다.
Spark shell
스파크를 설치하게 되면 spark-shell을 통해 대화형으로 작업을 수행할 수 있습니다. 쉘을 시작하려면 SPARK_HOME/bin 디렉토리로 이동하여 spark-shell2를 입력합니다. 해당 명령은 Spark를 로드하고 사용 중인 Spark 버전을 표시합니다.
기본적으로 spark-shell은 사용할 spark(SparkSession) 및 sc(SparkContext)와 같은 기본 명령어를 제공합니다.
이와 동시에 spark-shell은 Spark 컨텍스트 웹 UI를 생성하며 http://localhost:4041에서 접근 가능합니다.
Spark submit
spark-submit 명령은 옵션 및 구성 사항을 지정하여 클러스터에 Spark 또는 PySpark 애플리케이션 프로그램(또는 작업)을 실행하거나 제출하는 유틸리티입니다. 이때 제출하는 애플리케이션은 Scala, Java, Python(PySpark)와 같은 코드로 작성할 수 있습니다. 해당 유틸리티를 사용하여 다음을 수행할 수 있습니다.
- Yarn, Kubernetes, Mesos 및 Stand-alone과 같은 다양한 클러스터 관리자에 Spark 애플리케이션을 submit
- 클라이언트 또는 클라이언트 배포 모드에서 Spark 애플리케이션 submit
아래는 submit을 구성하는 예시입니다.
./bin/spark-submit \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key<=<value> \
--driver-memory <value>g \
--executor-memory <value>g \
--executor-cores <number of cores> \
--jars <comma separated dependencies>
--class <main-class> \
<application-jar> \
[application-arguments]Spark Web UI
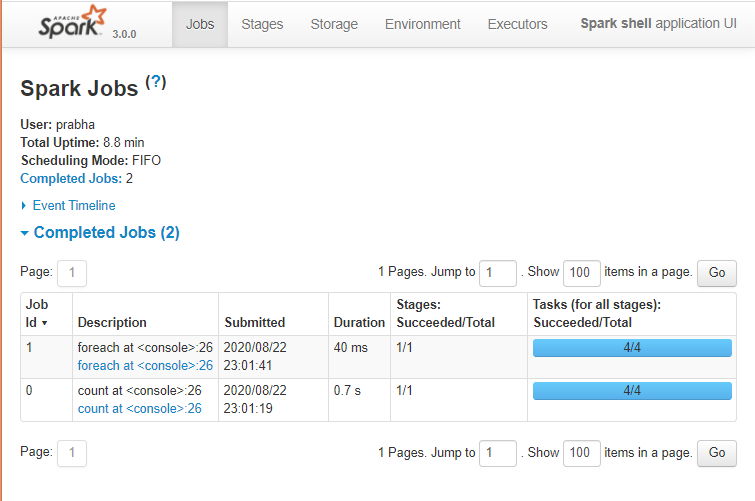
Apache Spark는 Spark 애플리케이션의 상태, Spark 클러스터의 리소스 소비 및 Spark 구성을 모니터링하기 위한 웹 UI 모음(작업, 스테이지, 테스크, 스토리지, 환경, 실행자 및 SQL)을 제공합니다. Spark Web UI를 통해 작업이 실행되는 방식을 확인할 수 있습니다. 기본적으로 http://localhost:4041에서 접근 가능합니다.
Spark History Server
Spark History Server는 spark-submit 또는 spark-shell 등을 거쳐 완료된 모든 응용 프로그램의 로그를 유지합니다. 이를 시작하기 위해서는 spark-defaults.conf에서 먼저 다음의 설정을 완료해야 합니다.
spark.eventLog.enabled true
spark.history.fs.logDirectory file:///c:/logs/path이제 다음 명령어를 실행하여 Linux 또는 Mac에서 Spark History 서버를 시작합니다. (Linux / MAC)
$SPARK_HOME/sbin/start-history-server.shWindows의 경우에는 다음 명령을 시작하여 히스토리 서버를 시작할 수 있습니다.
$SPARK_HOME/bin/spark-class.cmd org.apache.spark.deploy.history.HistoryServer기본적으로 히스토리 서버는 18080 포트에서 수신 대기 상태에 놓이며, http://localhost:18080/를 사용하여 브라우저에서 엑세스할 수 있습니다.
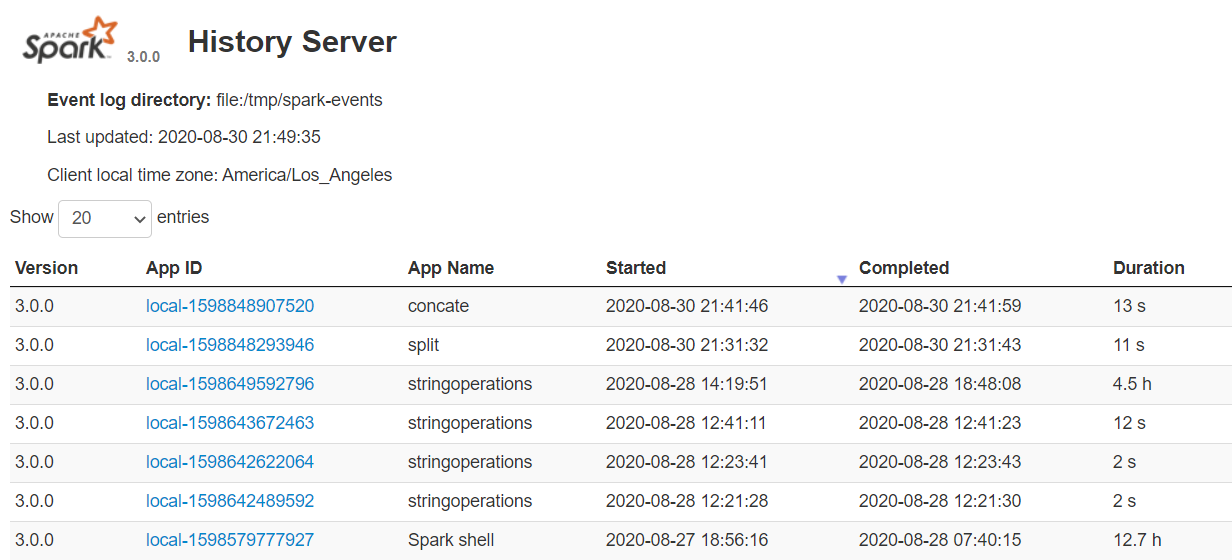
이때 각각의 App ID를 클릭하면 Spark Web UI에서 해당 애플리케이션의 세부 정보를 얻을 수 있습니다.
History Server는 이전 애플리케이션의 실행과 현재 진행 중인 실행을 교차 확인할 수 있어 Spark 성능 조정을 수행할 때 매우 유용합니다.
Spark Library(Module)
Spark는 엔진에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 서드파티 패키지 형태로 제공하는 다양한 외부 라이브러리를 지원합니다. 이때 Spark 표준 라이브러리는 사실 여러 오픈소스 프로젝트의 집합체라고 생각할 수 있습니다.
스파크가 각광을 받게 된 배경에는 스파크가 제공하는 라이브러리도 많은 영향을 끼쳤습니다. 스파크는 분산 처리 프레임 위에 Spark Streaming, SparkQL, MLlib, GraphX와 같은 라이브러리을 제공하여 실시간 수집부터 데이터 추출/전처리, 머신러닝 및 그래프 분석까지 하나의 흐름에 모든 것이 가능할 수 있도록 개발되었습니다.
여러 라이브러리 중 가장 유명한 몇 가지를 소개하자면 다음과 같습니다.
- Spark SQL: Spark Wrapper 함수에 SQL 쿼리를 넣어 추출/전처리/분석이 쉽게 가능하도록 지원
- MLlib: 머신러닝 알고리즘 제공
- Spark Streaming: 실시간 데이터 처리
- GraphX: 그래프 분석 라이브러리

다음 링크를 통해 다양한 외부 라이브러리 목록을 확인할 수 있습니다.
Spark Core
Spark Core는 분산 작업 디스패치, 스케쥴링, 기본 I/O 등의 추상화를 제공하는 Spark의 기본 라이브러리입니다.
SparkSession
버전 2.0에 도입된 SparkSession은 Spark RDD, DataFrame 및 Dataset을 프로그래밍 방식으로 사용하기 위한 Spark의 진입점이라고 생각할 수 있습니다. 즉, SparkSession 인스턴스를 생성하는 것은 RDD, DataFrame 및 Dataset을 사용하여 프로그램에 작성하게 되는 첫 번째 명령문이며, SparkSession은 아래 코드에서 볼 수 있 듯 SparkSession.builder() 패턴을 사용하여 생성됩니다.
import org.apache.spark.sql.SparkSession
val spark:SparkSession = SparkSession.builder()
.master("local[1]")
.appName("SparkByExamples.com")
.getOrCreate()SparkContext
SparkContext는 Spark 1.x (Java 용 JavaSparkContext)부터 사용할 수 있으며, 2.0에서 SparkSession을 도입하기 이전에 Spark 및 PySpark에 대한 진입점으로 사용되었습니다. SparkContext의 생성은 RDD로 프로그램을 만들고 Spark Cluster에 프로그램을 연결하는 첫 번째 단계였습니다. 앞서 spark-shell에서 sc 명령어를 통해 확인할 수 있었던 객체가 바로 SparkContext입니다.
Spark 2.x 버전 부터는 SparkSession을 통해 진입점을 생성하기 시작하면서 SparkSession을 생성하면 SparkContext 객체가 기본적으로 생성되었습니다.
💡 JVM 1개 당 SparkContext를 1개만 생성할 수 있는 것과 달리, SparkSession은 여러개의 객체를 생성할 수 있다는 점이 주요한 차이점입니다.
Spark Session과 스파크 언어 API와의 관계
스파크의 언어 API를 활용하면 다양한 프로그래밍 언어로 스파크 코드를 실행할 수 있습니다. 스파크는 모든 언어에 맞는 몇몇 핵심 개념을 제공하며 이러한 핵심 개념은 클러스터 머신에서 실행되는 스파크 코드로 변환됩니다. 구조적 API만으로 작성된 코드는 언어에 상관없이 유사한 성능을 발휘합니다. 다음 목록은 언어별 요약 정보입니다.
- 스칼라: 스파크는 스칼라로 개발되어 있으며 스칼라가 스파크의 기본 언어입니다.
- 자바: 스파크가 스칼라로 개발되어 있지만, 스파크 창시자들은 자바를 이용해서 스파크 코드를 작성할 수 있도록 심혈을 기울였습니다.
- 파이썬: 파이썬은 스칼라가 지원하는 거의 모든 구조를 지원합니다.
- SQL: 스파크는 ANSI SQL:2003 표준 중 일부를 제공합니다. 분석가나 비프로그래머도 SQL을 활용하여 스파크의 강력한 빅데이터 처리 기능을 쉽게 확인할 수 있습니다.
- R: 스파크에는 일반적으로 사용하는 두 개의 R 라이브러리가 있습니다. 하나는 스파크 코어에 포함된 SparkR이고 다른 하나는 R 커뮤니티에서 파생된 sparklyr입니다.

각 언어 API는 앞서 설명한 핵심 개념을 유지하고 있습니다. 사용자는 스파크 코드를 실행하기 위해 SparkSession 객체를 진입점으로 사용할 수 있습니다. 이때 주목할만한 점은 우리가 Python이나 R로 스파크를 사용할 때 JVM 코드를 작성하지 않는다는 점입니다. 스파크는 사용자를 대신하여 파이썬이나 R로 작성한 코드를 익스큐터의 JVM에서 실행할 수 있는 코드로 변환합니다.
이는 스칼라가 저수준의 비구조적(unstructured, RDD) API와 고수준의 구조적(structured, Data Frame) API를 가지고 있기 때문입니다. 이는 이후에 다시 중점적으로 다뤄보도록 하겠습니다.
'Data Engineering' 카테고리의 다른 글
| Zookeeper의 znode (0) | 2023.05.18 |
|---|---|
| Coursera 데이터 엔지니어링 강의 목록 (0) | 2022.12.08 |
| 로그 데이터 수집 (0) | 2022.11.18 |
| [에러 노트] AWS Data Crawler로 생성된 DB의 스키마가 업데이트 되지 않는 경우 (0) | 2022.10.26 |
| [AWS Glue] Crawler를 통해 S3에서 Data Catalog로 데이터 추출 (1) | 2022.10.26 |