



Application Layer, L7
먼저 Application Layer라고도 불리는 L7은 유저와 네트워크 간의 인터페이스 역할을 수행하는 계층이다. 해당 계층에서는 애플리케이션 및 사용자 간의 통신과 데이터 전송 방식을 다양한 방식으로 정의하게 되는데, 이를 프로토콜이라고 부르게 된다. L7 내에는 매우 다양한 프로토콜이 존재한다. 가장 대표적으로는 웹 애플리케이션의 통신을 가능하게 하는 HTTP와 HTTPS부터, 파일 전송에 활용되는 FTP, 이메일 메세지를 전송하는 SMTP, 이메일 수신에 사용되는 IMAP/POP3, google.com을 해석하게 해주는 DNS, 초기 주소 할당시에 사용되는 DHCP, 터미널 접속 시 사용되는 SSH 등 굵직한 프로토콜들이 L7 프로토콜로 분류된다.
모든 프로토콜을 전부 다뤄볼 수는 없을 것 같고 오늘은 이 중 HTTP를 집중적으로 살펴보고자 한다.
HTTP (HyperText Transfer Protocol)
웹에서 데이터를 전송하는데 사용되는 프로토콜이다. 주로 HTML 문서나 이미지와 같은 웹 리소스의 전송에 사용되지만, 다양한 종류의 데이터를 전송하는데 활용될 수도 있다. 다음은 HTTP의 주요한 특징이다.
- Stateless: HTTP는 별도의 세션 연결을 사용하지 않는다. 즉, 각 요청은 독립적이며 서버 측에서는 클라이언트와의 이전 정보를 기억하지 않는다. 때문에 서버에서는 사용자의 상태를 유지하기 위해 쿠키나 세션과 같은 테크닉을 사용하게 되었다.
- Request/Response 모델: HTTP는 클라이언트와 서버 간의 요청과 응답을 기반으로 수행된다. 클라이언트(e.g. 웹 브라우저)는 서버에 특정 리소스를 요청하고 서버는 해당 리소스를 찾아 응답으로 반환한다.
- Method: HTTP는 다양한 메서드(or "Verb")를 제공한다. 주요 메서드로는 GET, POST, PUT, DELETE가 있다.
- Versioning: HTTP는 시간이 지남에 따라 여러 버전이 개발되었다. (e.g. HTTP/1.0, HTTP/1.1, HTTP/2, HTTP/3)
- Header: HTTP 요청과 응답에는 '헤더'가 포함되어 있다. 헤더는 요청 및 응답에 대한 메타데이터를 포함하며, 캐싱, 인코딩, 인증 등의 다양한 목적으로 사용된다.
- Non-securable: 기본 HTTP는 암호화되지 않은 텍스트로 데이터를 전송하기 때문에 중간에서 데이터를 가로채는 공격에 취약하다(Man in the Middle Attack). 이를 해결하기 위해 HTTPS(SSL/TLS를 사용하는 HTTP)가 도입되었다.
- Port: 기본적으로 80 포트를 사용한다.
각각의 특성들을 조금 더 자세히 이해해보자.
Stateless
Stateless라는 단어의 의미는 다르게 말해서 각각의 요청이 서로 독립적이며, 서버가 클라이언트의 이전 요청에 대한 정보를 저장하지 않는다는 것을 의미한다. 즉, 한 번의 클라이언트 요청과 이에 대한 서버의 응답이 전송되면 서버는 그 연결에 대한 모든 정보를 잊어버린다. 이렇게 설계된 이유는 원래 웹이 정적인 문서를 공유하기 위해 만들어진 시스템이기 때문이다. 클라이언트가 서버에 문서를 요청하면, 서버는 해당 문서를 찾아 응답으로 보내고 그 연결을 종료한다. 이러한 시나리오에서는 굳이 클라이언트의 이전 상태를 기억할 필요가 없다.
그러나 웹이 발전하면서 사용자들은 로그인, 장바구니, 그 외의 다양한 개인화된 페이지 등 상태를 유지해야 하는 다양한 기능들을 웹 환경에서 사용할 수 있게 되었고, 이에 대한 기술적 요구사항을 만족시키기 위해서 쿠키와 세션이라는 기술들이 도입되었다.
쿠키(Cookies)는 클라이언트 측에서 정보를 저장하는 작은 텍스트 파일이다. 쿠키는 먼저 웹사이트에 의해서 클라이언트(웹 브라우저)에 전송된다. 그 후 웹 브라우저는 쿠키를 통해 자신의 정보들을 웹 사이트에 보내는 형태로 웹사이트에게 자신의 상태를 전달한다. 즉 쿠키를 통해 서버는 Stateless한 패킷을 처리하기에 부담이 경감되지만, 클라이언트 쪽의 자원을 소모하여 Stateful한 것처럼 클라이언트 정보를 관리할 수 있게 된다.
다만 쿠키의 경우에는 클라이언트 측에 저장되기 때문에 보안 상 문제가 발생할 수 밖에 없다. 당장 유저만 하더라도 웹 브라우저의 개발자 도구를 통해서도 쿠키의 내용을 살펴보거나 수정할 수 있다. 이와 관련한 주요한 보안 문제로는 XSS(크로스 사이트 스크립팅), CSRF(크로스 사이트 요청 위조)가 있다.
세션(Session)은 서버 측에서 사용자 정보를 저장하는데 사용한다. 앞서 설명한 쿠키에 세션 ID를 첨부하여 전달하는 형태로 특정 사용자의 세션을 추적할 수 있게 된다. 이후 클라이언트의 모든 요청에는 서버로부터 전달받은 세션 ID가 포함된다. 서버는 이 세션 ID를 통해 사용자를 인식하고 상태를 유지할 수 있게 된다.
HTTP는 분명 Stateless한 프로토콜이지만 앞서 설명한 쿠키을 통한 세션 관리를 통해 마치 Stateful한 시나리오도 처리할 수 있게 되었다.
참고. XSS & CSRF
먼저, XSS는 대략 Stored XSS, Reflected XSS, DOM-based XSS 3종류로 나뉜다.
Stored XSS는 공격자가 악의적인 스크립트를 웹 애플리케이션의 DB에 삽입하는 것으로 이뤄진다. 예를 들어 댓글 기능이 있는 웹 사이트에서 사용자가 악성 스크립트를 포함한 글을 작성하게 되는 경우 다른 사용자가 그 댓글을 확인할 때마다 악성 스크립트를 실행하는 형태로 전개될 수 있다.
Reflected XSS는 사용자에게 악의적인 URL을 클릭하도록 유도하는 것으로 이뤄진다. 이때 말하는 URL에는 악의적인 스크립트가 내장되어 있으며 해당 URL을 클릭하면 웹 애플리케이션은 해당 스크립트를 실행시키는 형태로 공격이 전개된다. 주로 피싱 공격에 사용되는 것으로 알려져있다.
DOM-based XSS는 웹 애플리케이션의 클라이언트 측 스크립트가 DOM(Document Object Mode)의 구조나 속성을 변경하는 경우 발생한다. 공격자는 악의적인 입력을 통해 DOM을 수정하여, 수정된 스크립트가 실행되게 하는 것으로 공격을 전개한다.
이에 대한 가장 기본적인 방어 방법은 결국, 서버 측에서 들어오는 사용자 입력에 대해 신뢰를 하지 않는 것이다. 모든 입력에 대해 의심하고 검증하며 출력 시에는 특수 문자를 적절하게 인코딩해야 한다. 또한 콘텐츠 보안 정책(CSP)를 적절하게 설정하는 것으로도 어느 정도의 방어가 가능하다. CSP를 통해 웹 브라우저에게 특정 소스에서만 콘텐츠를 로드하도록 지시한다면, 어느정도는 공격자가 악의적인 스크립트를 삽입하는 것을 막을 수 있다.
마지막으로, XSS를 방어하는 대표적인 방법으로 알려진 HttpOnly 플래그 설정이 있다. 특히 쿠키를 사용하여 공격을 전개하는 경우 효과적인데, HttpOnly 플래그가 설정된 쿠키의 경우 JavaScipt에서 접근을 막아버린다. 때문에 해당 스크립트가 동적으로 실행될 여지를 막는다는 점에서 XSS 공격을 통한 쿠키 도용을 방지한다.
이어서 CSRF는 사용자가 로그인 상태에서 악의적인 웹 사이트를 방문하게 되면, 그 사이트가 사용자 몰래 다른 사이트에 요청을 보내도록 하는 공격이다. 예를 들어 사용자가 은행 웹 사이트에 로그인한 상태에서 CSRF 공격이 포함된 악의적인 웹 페이지를 방문하면 그 페이지는 사용자의 은행 계좌에서 돈을 전송하는 요청을 은행 웹 페이지에 보낼 수 있다. 이는 SameSite 플래그를 설정하는 것으로 어느정도 방지가 가능하다.
예를 들어 mybank.com이라는 정상적인 은행 사이트가 있고, 악의적인 malicious.com이라는 사이트가 있다고 하자.
- 사용자는 은행 웹 사이트에 로그인하여 사용자의 브라우저에 로그인 상태를 나타내는 쿠키를 전송한다.
- 이후 사용자가 악의적인 웹사이트 (malicious.com)에 방문한다.
- malicious.com에서는 사용자의 브라우저를 이용하여 mybank.com에 악의적인 요청을 보내려고 시도한다.
- 이때 사용자의 브라우저가 이전에 설정된 mybank.com의 로그린 쿠키를 함께 전송하려고 시도한다.
- 만약 은행 웹 사이트 쿠키에 SameSite 플래그가 설정되어 있지 않다면 쿠키는 요청과 함께 전송된다. 은행의 웹사이트는 마치 악의적인 사이트에게서 발생한 요청이 사용자에게서 온 것처럼 착각하게 되며, 이는 CSRF 공격으로 이어진다.
이때 SameSite 플래그가 쿠키에 설정되어 있다면 mybank.com에서 발생한 쿠키는 오로지 mybank.com에 대한 요청에만 사용될 수 있다. malicious.com에서는 사용자가 은행과의 연결에 사용된 쿠키를 확인하고 싶어하지만, SameSite 플래그가 설정되어 있다면 해당 쿠키는 오로지 mybank.com 도메인과의 연결에서만 첨부되기에 malicious.com과의 요청에서는 해당 쿠키가 활용되지 않는다.
Request/Response 모델
간단하게 설명하면, 클라이언트가 원하는 정보나 서비스를 요청하면 서버는 그에 따른 적절한 응답을 반환하는 방식을 의미한다.
Request (요청)
클라이언트(웹 브라우저)가 웹 서버에 특정 정보나 서비스를 요청하는 것을 의미한다.
요청 메서드: HTTP에는 여러 요청 메서드가 정의되어 있으며, 대표적인 메서드로는 GET, POST, PUT, DELETE 등이 있다.
- GET
- 정보를 조회하기 위한 요청이다.
- 웹 페이지의 내용이나 이미지 등의 리소스를 요청하는 경우 주로 사용된다.
- 데이터를 변경하는데 사용되어서는 안된다.
- e.g. 웹 브라우저 주소창에 URL을 입력하고 페이지를 로드하는 경우, 검색 엔진이 웹 페이지를 크롤링하는 경우
- 정보를 조회하기 위한 요청이다.
- POST
- 정보를 서버에 전송하기 위한 요청이다.
- 새로운 리소스를 생성하거나 기존 리소스에 데이터를 추가할 때 사용된다.
- 다만, 서버의 데이터나 상태가 변경되는 상황에 주의해야 한다.
- e.g. 회원가입, 로그인, 댓글 작성, 파일 업로드 등의 동작
- 정보를 서버에 전송하기 위한 요청이다.
- PUT
- 특정 리소스를 수정하거나 대체할 때 사용된다.
- PUT 요청을 사용하여 리소스를 업데이트할 경우, 해당 리소스는 기존 데이터에서 완전 새로운 데이터로 대체된다.
- 때문에 부분적인 업데이트를 원하는 경우, PUT은 권장되지 않는다.
(e.g. 사용자 정보 중 '주소'만 변경하고 싶은 경우, '이름'과 '전화번호' 등의 기존 정보도 사라질 수 있다.) - e.g. 사용자 프로필 수정, 게시물 내용 수정
- 특정 리소스를 수정하거나 대체할 때 사용된다.
- PATCH
- 특정 리소스의 일부만 수정하는 경우 사용된다.
- PUT 요청과 달리 리소스의 전체 내용을 대체하는 것이 아니라, 특정 부분만 변경한다.
- e.g. 사용자 정보 중 '주소'만 변경하고 싶은 경우
- 특정 리소스의 일부만 수정하는 경우 사용된다.
- HEAD
- 헤더만을 가져오고 싶은 경우 사용된다.
- 리소스를 가져오는 GET 요청과 유사하지만, 본문(Body)를 제거한다는 특징이 있다.
- e.g. 리소스의 변경 변경 여부 확인, 리소스의 크기 확인, 지원하는 HTTP 메서드 확인하고 싶은 경우
- 헤더만을 가져오고 싶은 경우 사용된다.
- OPTIONS
- 특정 URL에 대해 어떤 HTTP 메서드가 허용되는지를 알아보기 위해 사용된다.
- e.g. CORS(Cross-Origin Resource Sharing) 설정 검사 등에서 사용된다.
- 특정 URL에 대해 어떤 HTTP 메서드가 허용되는지를 알아보기 위해 사용된다.
Response(응답)
서버가 클라이언트의 요청에 대한 결과를 반환하는 것을 의미한다. 요청의 처리 결과에 대한 상태코드, 응답 헤더, 응답 본문으로 구성된다.
상태 코드: 서버가 클라이언트의 요청을 어떻게 처리했는지 나타내는 코드
- e.g. 200 OK는 성공적인 응답, 404 Not Found는 요청한 리소스를 찾을 수 없는 경우를 나타낸다.
헤더: 응답에 대한 메타데이터를 담고 있다. 콘텐츠의 유형(MIME), Set 쿠키, 서버 정보등의 내용을 포함할 수 있다.
본문: 요청한 리소스의 내용. HTML 페이지, 이미지, 동영상 등의 데이터를 포함할 수 있다.
이때 헤더 정보는 요청 메세지와 응답 메세지 모두에 들어가는 내용으로 해당 메세지의 메타데이터를 담는다.
HTTP 헤더
HTTP 헤더를 5가지 종류로 분류할 수 있다. 각 종류와 해당 헤더에는 어떤 종류들이 들어갈 수 있는지 알아보자
- General Headers: 요청과 응답 양쪽에서 모두 사용될 수 있는 헤더이다.
- Cache-Control: 캐싱 동작을 제어한다.
- Date: 메시지가 생성된 날짜와 시간을 나타낸다.
- Connection: 네트워크 연결에 대한 제어를 위한 지시를 의미한다.
- Cache-Control: 캐싱 동작을 제어한다.
- Request Headers: 클라이언트에서 서버로의 요청에 사용되는 헤더이다.
- Accept: 클라이언트가 이해할 수 있는 컨텐츠의 유형을 명시한다.
- Host: 요청 대상의 도메인 이름을 명시한다.
- User-Agent: 요청을 생성하는 클라이언트의 정보를 나타낸다. (e.g. 브라우저, 버전 등)
- Accept: 클라이언트가 이해할 수 있는 컨텐츠의 유형을 명시한다.
- Response Headers: 서버에서 클라이언트로의 응답에서만 사용된다.
- Server: 응답을 생성하는 웹 서버의 정보이다.
- Location: 3xx 응답의 경우, 클라이언트가 이동해야할 URL이다.
- WWW-authenticate: 401 Unauthorized 응답에 사용되며, 클라이언트에게 어떤 인증 방식을 사용해야 하는지 알린다.
- Server: 응답을 생성하는 웹 서버의 정보이다.
- Entity Headers: 요청이나 응답의 본문에 대한 정보를 포함한다.
- Content-Type: 본문의 미디어 유형 (e.g. 'text/html', 'application/json' 등)
- Content-Length: 본문의 길이 (Byte 단위)
- Content-Encoding: 본문이 어떻게 인코딩되는지 (e.g. gzip)
- Content-Type: 본문의 미디어 유형 (e.g. 'text/html', 'application/json' 등)
- Custom Headers: 표준화된 헤더 외에 개발자는 필요에 따라 사용자 정의 헤더를 추가할 수 있다.
- 일반적으로 'X-' 접두사를 사용한다. (e.g. X-Requested-With)
- 현대의 애플리케이션의 경우 굳이 접두사를 붙이지 않고 사용자 정의를 생성하지 않기도 한다.
- 일반적으로 'X-' 접두사를 사용한다. (e.g. X-Requested-With)
HTTP 요청을 보내는 경우 필요에 따라 여러 헤더들을 모두 포함하여 보낼 수 있다.
예를 들어 POST 요청을 통해 JSON 데이터를 서버에 보낼 때 User-Agen와 Host와 같은 요청 헤더와 함께 'Content-Type: application/json', 'Content-Length'와 같은 엔티티 헤더를 동시에 포함하여 보낼 수 있다.
HTTP의 역사 (버전 별 변화 내용)
HTTP의 경우 1996년의 초기 버전 HTTP/1.0에서부터 2019년 이후 초안이 등장한 HTTP/3에 이르기까지 꾸준히 새로운 버전을 업그레이드하며 기존의 한계와 문제점을 개선하고 있다.
해당 챕터에서는 각각의 HTTP 버전을 이해하고, 서로 비교하는 데에 초점을 둔다.
먼저 기본적으로 HTTP/1.0 방식의 커뮤니케이션에서는 각 요청에 대해 새로운 TCP 연결을 생성되며 요청이 완료되는 경우 생성된 TCP 연결이 바로 닫히는 형태로 구현되었다. 이는 Stateless라는 HTTP의 설계 원칙에는 부합하였으나, 만약 여러 요청이 있을 때 매번 TCP의 Handshake 과정을 수반하기에 연결을 설정하고 해제하는 과정에서 오버헤드를 야기했다. 뿐만 아니라 HTTP/1.0을 설계할 당시에는 효율적이였던 솔루션들보다 더욱 효율적으로 연결을 수행할 수 있는 방법들이 생성되었다. 1997년에 정의된 HTTP/1.1은 이러한 내용에 대한 개선을 담고 있다.
HTTP/1.1이 HTTP/1.0에 비해 어떤 장점을 갖는지, 하나하나 따져보자
HTTP/1.0 vs HTTP/1.1
지속적인 연결 (Persistent Connection)
- 여러 요청을 하나의 TCP 연결에서 처리할 수 있게 되었다.
- General Header에 'Connection: Keep-alive' 헤더를 사용하여 연결을 열린 상태로 유지할 수 있게 되었다.
파이프라이닝 (Pipelining)
- 지속적인 연결을 통해 클라이언트가 이전 요청의 응답을 기다리지 않고도, 연속적으로 여러 요청을 보낼 수 있게 되었다.
- 그러나 응답은 순서대로 받아야한다는 점에는 변화가 없다.
캐싱 메커니즘 개선
ETag, If-Modified-Since, If-Unmodified-Since, If-None-Match 등의 헤더를 도입하여 캐싱 기능이 크게 향상되었다. 이러한 헤더들은 웹 브라우저나 중간의 캐시 저장소(e.g. proxy caches)에 최신 버전의 웹 컨텐츠가 있는지, 굳이 새로운 버전을 가져올 필요가 있는지 등을 판단하는데 도움이 된다. 이를 통해 네트워크 대역폭을 절약하고, 불필요한 데이터 전송을 줄여 웹의 전체적인 퍼포먼스를 개선할 수 있었다.
아래는 앞서 소개한 HTTP/1.1의 추가된 헤더의 목록들이다.
- Etag(Entitiy Tag): 리소스의 버전을 식별하는 고유한 문자열
- 서버는 리소스가 변경된다면 해당 값을 업데이트해야 한다.
- 클라이언트가 마지막으로 받은 버전과 현재 서버의 버전 간에 차이가 있는지 비교하는데 활용된다.
- ETag를 활용하면 리소스의 내용이 실제로 변경이 이뤄졌는지 여부를 확인할 수 있으므로, 불필요한 데이터 전송을 피할 수 있다.
- If-Modified-Since: 마지막으로 리소스를 받은 이후의 날짜/시간을 지정한다.
- 서버는 이 날짜 이후에 리소스가 수정되었는지를 확인한다.
- 만약 수정이 없었다면, 304 Not Modified 응답을 반환하여, Body는 보내지 않는다.
- If-Unmodified-Since: 직전과 반대로 특정 날짜 이후 리소스가 수정되지 않은 경우만 요청을 수락하도록 서버에 지시한다.
- 리소스가 해당 날짜 이후에 수정되었다면 서버는 412 Precondition Failed 응답을 반환한다.
- 리소스가 해당 날짜 이후에 수정되었다면 서버는 412 Precondition Failed 응답을 반환한다.
- If-None-Match: 요청 헤더에서 ETag 값과 함께 사용되며, 클라이언트가 가진 리소스의 ETag 값과 서버의 리소스 Etag 값이 일치하지 않을때만 리소스를 전송하도록 서버에 요청한다.
- ETag 값 간에 불일치가 발생한다면, 서버는 304 Not Modified 응답을 반환하여 불필요한 데이터 전송을 피한다.
호스트 헤더(Host Header)의 등장
HTTP/1.1에는 호스트 헤더('Host')가 추가 되었다. 호스트 헤더는 각 HTTP 요청이 어떤 웹사이트를 타겟으로 하는지를 명시한다.
예를 들어 A라는 사람이 동시에 운영하는 example.com과 another-example.com이라는 사이트가 있다고 하자. HTTP/1.1에는 호스트 헤더가 추가되어, 헤더에 'Host: example.com' 혹은 'Host: another-site.com'이라는 정보를 담는다. 이를 통해 해당 요청이 어떤 사이트를 대상으로 수행되는지를 알 수 있다.
그럼 왜 호스트 헤더라는 개념이 추가되어야 했을까? 바로 가상 호스팅이라는 개념을 도입할 수 있기 때문이다.
가상 호스팅은 하나의 IP 주소에 여러 도메인을 연결하는 기술이다. HTTP/1.0에서는 하나의 DNS 주소에는 하나의 IP 주소가 매핑되어야 했다. 때문에 A가 2개의 사이트를 운영하기 위해서는 2개의 IP가 필요했다.
HTTP/1.1에서는 굳이 2개의 IP 주소 없이도 2개의 DNS 주소를 사용할 수 있다. 요청 헤더에 목표로 하는 DNS 호스트 이름을 명시하게 되면 굳이 IP 주소를 통해 목표를 식별할 필요없이 호스트 헤더를 통해 식별이 가능해진다.
앞의 예시에서 A는 123.123.123.13이라는 가상의 IP 주소를 사용한다고 가정하자. 해당 주소는 example.com과 another-site.com라는 두 사이트 모두를 호스팅한다. 대신 사용자가 요청을 보낼때, 123.123.123.13이라는 주소에 'host:example.com'이라는 호스트 헤더를 포함한 요청을 보낸다. 서버는 호스트 헤더를 활용하여 해당 요청이 어떤 사이트를 대상으로 하는지를 알 수 있다. 이를 가상 호스팅이라고 부른다.
가상 호스팅은 결국 IP 주소의 경감으로 이어진다. 또한 굳이 각 웹사이트마다 별도의 서버나 IP 주소를 사용할 필요가 없기에 호스팅 비용을 절감할 수 있다.
1997년 첫 HTTP/1.1 버전이 정의된 이래로 HTTP/1.1은 위의 개선 사항들을 포함하는 변화들을 이어왔다. 그러다 2015년 경 중요한 변경점들과 함께 HTTP/1.1 대신 HTTP/2.0이라는 새로운 이름을 갖게 되었다.
HTTP/1.1 vs HTTP/2.0
바이너리 기반 데이터 교환
먼저, HTTP/1.1까지의 데이터 교환은 텍스트 기반이였다. 개발자는 굳이 별도의 도구 없이도 디버깅 도구를 통해 메세지를 읽을 수 있는 것이 당연하다고 여겨왔다. HTTP/2.0의 메세지는 바이너리 기반이다. 인코딩이라는 추가적인 작업을 요구하지만, 바이너리를 통한 데이터 교환은 더욱 빠르고, 굳이 텍스트 형식을 유지하기 위한 내용을이 필요없기에 효율적으로 동작했다.
한 번의 연결에서 동시에 여러 요청외에도 여러 응답까지 교환할 수 있게 되었다. HTTP/1.1의 파이프라이닝의 경우 클라이언트는 여러 요청을 연속적으로 보낼 수 있게 되었다. 그러나 파이프라이닝에서는 여러 요청을 연속적으로 보내도, 서버는 순차적인 응답을 보장해야 한다. 즉, 첫 번째 요청의 응답이 완료되기 전에는 두 번째 요청의 응답을 시작할 수 없다. 이런 구조는 첫 번째 요청이 특히 오래 걸릴 경우 나머지 요청도 블락되는 문제인 HOL(Head-of-Line) 블로킹 문제를 야기한다.
멀티플랙싱
HTTP/2.0의 멀티플랙싱(Multiplexing)은 HOL 문제를 해결한다. HTTP/2.0에서는 단일 연결 위에 여러 개의 동시 스트림을 구축하는데, 이 각각의 스트림이 독립적인 요청과 응답을 처리할 수 있다. 각 스트림은 독립적으로 요청과 응답을 처리하며, 이로 인해 여러 요청의 응답은 독립적으로 도착하게 된다. 그 결과 특정 요청에 대한 응답이 지연되더라도 다른 요청에 대한 응답은 계속해서 도착할 수 있게 되어, HOL 블로킹 문제가 해결되었다.
스트림에 대해서 궁금증이 생겨서 더 찾아보니, 스트림을 관리하는 주체는 클라이언트와 서버 양쪽이라는 정보를 얻을 수 있었다. 클라언트와 서버는 1) 스트림 생성, 2) 스트림의 우선 순위 조정, 3) 플로우 제어(데이터 전송 속도 제어), 4) 스트림 종료, 5) 에러 처리 의 순서대로 각 주체는 스트림을 관리한다. 개인적으로 플로우 제어가 상당히 중요한 개념이라고 느꼈는데, "특정 스트림이 너무 많은 데이터를 전송하여 다른 스트림의 전송을 방해하는 것을 막기 위해 클라이언트나 서버는 각 스트림에 대한 데이터 전송 속도를 제어하는 기술" 정도로 이해할 수 있었다.
헤더의 압축
HTTP/2.0은 헤더를 HPACK 알고리즘을 통해 압축하여 헤더의 크기를 줄인다. 줄여진 헤더의 크기는 형태로 네트워크 오버헤드를 감소를 의미한다. 내용을 담고 싶었으나 설명이 다소 복잡하여 추후에 다시 이해해보는 걸로 넘어가고자 한다. 일단은 HPACK이라는 존재를 아는 것만으로도 충분해보인다. 대신 RFC 공식 문서를 첨부한다.
https://httpwg.org/specs/rfc7541.html
RFC7541
HPACK: Header Compression for HTTP/2
httpwg.org
마지막으로 HTTP/2.0과 HTTP/3.0의 차이를 비교하며 글을 마무리하려 한다.
HTTP/2.0 vs HTTP/3.0
HTTP/3.0의 가장 주요한 특징은 QUIC(Quick UDP Internet Connections)라는 새로운 전송 프로토콜을 사용한다는 점이다. HTTP/2.0까지의 전송은 당연하게도 TCP를 기반으로 한다. 신뢰성 있는 데이터 전송이라는 목적을 달성하기 위해 TCP의 사용은 필수적이였고, TCP의 3-way 핸드쉐이크 과정에서 발생하는 오버헤드는 당연했다.
이름에서 알 수 있듯, QUIC은 UDP를 기반으로 한다. UDP의 주요한 특징은 연결 지향적이지 않다는 것이다. 이는 곧 TCP에 비해서 별도의 연결 과정이 없기 때문에 속도가 빠르다는 장점으로 이어진다. 다만, 단점은 확실하다. 중간에 패킷이 손실되는 경우 UDP는 이를 재전송하는 매캐니즘이 없다. 또한 네트워크 지연 등으로 특정 패킷 간에 순서가 뒤바뀐다고 해도, UDP 통신으로는 해당 패킷들의 순서를 알 수 없다. 이는 모두 TCP의 특징이자 장점으로 작용한다.
QUIC은 UDP를 기반으로 하지만 연결지향적인 특징을 갖는다. 그럼에도 속도 측면에서 TCP보다 훨씬 빠른 속도를 보장한다. 이는 최초 연결이 이뤄진 이후의 연결에서 QUIC이 연결 정보를 캐시하여, 한번 연결이 된 클라이언트와 서버에 대해서는 연결 과정이 생략되기에 가능하다. 다만, 최초 연결 과정에서는 QUIC과 TCP의 핸드 쉐이킹은 상당히 유사하다. QUIC은 UDP 위에서 구현된다는 특징을 가지지만, 사실 UDP 위에 교묘하게 TCP의 기능을 섞은 매커니즘에 가깝다. QUIC은 UDP를 활용한 전송 매커니즘이다. 때문에 빠르다는 특성을 갖는다. 여기서 그럼 어떻게 전송하는 데이터의 신뢰성을 보장할 수 있는지가 핵심이다.
QUIC은 데이터 전송의 신뢰성과 순서를 유지하기 위해 TCP에서 활용되는 몇몇 개념을 차용하지만 그 구현 방식이 조금 다르다. 우선 TCP는 연속적인 바이트 스트림으로 데이터를 보낸다면, QUIC은 메세지를 기반으로 데이터를 전송한다. 이는 각각의 메세지가 독립적으로 전송되고 심지어 다른 순서로 도착해도 문제가 없다는 것을 의미한다. 즉, 경계가 모호한 바이트 기반의 데이터 대신, 명확한 경계의 메세지 기반 데이터를 통해 다른 메세지들과의 독립성이 보장된다. 이때, QUIC은 HTTP/2.0의 멀티플랙싱과 마찬가지로 여러 스트림을 활용하는데, 경계가 모호한 메세지이기에 다양한 메세지가 독립적인 구조로 동작하여 다른 스트림에서 처리한 메세지의 의도치 않은 손실이나 다른 스트림의 병목에 대해서 영향을 받지 않는다.
그러나 QUIC의 최초 연결과 TCP 핸드쉐이킹은 암호화 연결을 어떻게 수행하는지에서 큰 차이를 갖는다.. TCP의 핸드쉐이크는 두 시스템 간의 연결을 초기화하고 서로가 데이터 전송을 위해 준비하는 과정을 의미한다. TCP는 별도의 암호화 과정이 없기에 TLS 프로토콜을 추가적으로 활용하는데, TLS를 통한 암호화 연결을 위해서는 추가적인 TLS 핸드쉐이킹이 필요하다. QUIC 또한 TLS 1.3을 활용한다. 다만 QUIC에서는 별도의 핸드쉐이크 과정을 필요로 하는 대신 통합된 형태로 TLS 1.3을 사용한다. 클라이언트는 암호화 정보와 함께 초기 연결 요청을 보내고 서버는 해당 정보를 기반으로 응답한다. 즉, TLS를 사용하되 이를 위한 핸드쉐이킹 과정을 생략함으로서 연결을 효율적으로 처리한다.
QUICK의 최초 연결 과정에 대한 순서이다.
- Client Initial(0.5 RTT): 최초 연결 시 클라이언트는 서버에 연결 설정을 위한 초기 메세지를 보낸다. 이 메세지에는 연결 ID, 버전 정보, 암호화 정보 등이 담겨있다.
- Server Response(0.5 RTT): 클라이언트의 메세지에 대해 서버는 이를 받아들여 자신의 연결 ID와 함께 클라이언트에 응답한다.
- Client Response: 클라이언트는 서버의 키를 사용하여 암호화된 메시지를 전송하고, 이를 통해 양쪽 모두 상대방의 키를 올바르게 받았음을 확인한다.
그림에서 살펴보듯, TCP에 비해 그 절차가 훨씬 간소화되었으며, TCP + TLS가 붙는 경우 2-RTT까지 증가하는 초기 연결 비용을 1-RTT로 끌어내린다.
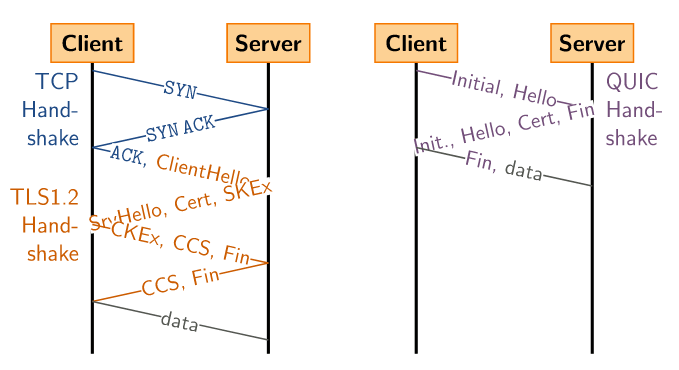
또한 QUIC은 한번 연결이 설정되는 경우, 이를 캐싱하여 이후 두 호스트 간에 연결이 발생하는 경우 굳이 1-RTT의 연결을 사용하지 않고도 0-RTT를 통해서 연결이 이뤄진다. 0-RTT의 핵심 아이디어는 클라이언트가 서버와의 연결에서 얻은 정보(세션 티켓과 키)를 재사용하여 다음 연결 시에 왕복 없이 바로 데이터 전송을 시작한다는 것이다.
예를 들어 웹 브라우징 시에 사용자가 웹 페이지를 방문한 이후 다시 해당 웹페이지를 방문하려고 할때 0-RTT를 활용하면 연결 설정 시간이 크게 줄어든다.
그러나 0-RTT에는 2가지 문제가 존재한다.
먼저, 네트워크가 지연되거나 기타 이유로 0-RTT 요청 패킷이 소실되는 경우 해당 세션의 초기 설정 상태에 문제가 발생한다. 초기 0-RTT 요청 패킷이 도달하지 않으면 서버는 클라이언트가 캐싱한 세션 정보를 사용하여 연결을 시도하고 있음을 인지하지 못하며, 이러한 상황 속에서 클라이언트가 추가적인 데이터 패킷을 보내더라도 서버는 해당 패킷들을 적절한 연결 컨텍스트 내에서 해석할 수 없게 된다. 때문에 0-RTT의 요청 패킷이 문제가 된다면 이후의 데이터들도 정상적으로 전달되지 못한다. 물론 요청이 제대로 도달하지 않았을 경우를 추적하는 여러 매커니즘이 있다. 먼저 서버 측 관점에서는 Packet Numbering 방식을 통해 각 패킷에 고유한 번호를 할당하고 패킷의 순서를 보장할 수 있다. 만약 초기 연결 설정에 대한 패킷이 누락된다면, 서버는 해당 패킷이 손실되었다는 것을 인지하고 클라이언트에게 재전송을 요청할 것이다. 만약 이를 서버 측에서 처리해내지 못한다고 해도 클라이언트 측에서는 타임아웃을 활용하여 일정 시간이 지나도 돌아오지 않는 응답에 대해서, 다시 요청을 보낸다.
두 번째 잘 알려진 문제로는 Replay Attack의 위험성이 크다는 것이다. 만약 악의적인 공격자가 네트워크 상에서 0-RTT를 가로챈 후 이를 변조하여 다시 전송한다면 이는 크나큰 보안 위협으로 작용한다. 이러한 이유로 0-RTT 데이터는 일회성의 요청, 즉 "GET" 요청과 같은 것에만 권장된다.
이어서 QUIC은 연결을 마이그레이션하는 경우이라는 큰 장점을 갖는다. 사용자가 네트워크 환경을 전환할 때 (LTE에서 Wifi) QUIC 연결은 기존의 연결을 유지하면서 빠르게 새로운 IP 주소로 마이그레이션할 수 있다. 이로 인해 연결을 재설정한다거나 새로운 핸드쉐이크 없이도 네트워크를 전환할 수 있다.
여기까지 HTTP를 살펴보았다. 사실 추가적으로 더 넣고 싶었던 내용도 있었고 편집 과정에서 너무 과하다고 생각되는 내용들도 있었다. 특히 HTTPS를 설명하지 못한게 아쉽다. HTTPS의 경우 사실 TLS와 SSL에 대한 설명이 주가 되기 때문에 네트워크에 대한 글보다는 보안이론에 대한 설명이 주가 될 거 같다. 어쩌다보니 꼬박 하루 동안 글을 쓰고 있는데, 얻어가는게 많아 시간이 아깝지는 않았던 것 같다.
'CS' 카테고리의 다른 글
| IPv4에서 IPv6로의 전환 매커니즘 (0) | 2023.08.06 |
|---|---|
| 정적 라이브러리 (0) | 2022.12.05 |
| 실행가능한 목적파일 (0) | 2022.12.03 |
| Linking(링킹) 소개 (0) | 2022.12.02 |
| 시간 지역성을 위한 캐시 재배치 (0) | 2022.12.01 |
몇 일전 면접에서 받았던 질문이다.
"그럼 IPv4에서 IPv6로의 전환은 어떻게 가능할까요? IoT 솔루션의 경우에는 많은 경우에서 IPv6를 사용하는 걸로 알고 있는데 혹시 이 부분에 대해서 답변 주실 수 있나요?"
워딩은 정확하진 않지만, 대략적으로 이런 워딩의 질문을 받았던 것으로 기억한다. 생각지도 못한 질문이였고, 솔직히 말해서 그게 가능하겠구나라는 생각도 면접장에서 처음 했었다. 사실 너무나 당연하게도 IPv4 주소체계를 사용하는 머신이 있고 IPv6 주소체계를 사용하는 머신이 있다면, 어떤 프로토콜을 사용하고 DHCP에서 어떻게 주소를 받아왔는지만 다르지 두 머신의 연결이 불가능할 이유는 당연히 없다. 질문 자체도 생각할 여지가 많았지만 그리 잘 답변하지는 못했던 것 같다. 그럼에도 이 질문이 계속해서 뇌리에 남는 것은, 질문의 난이도도 난이도이지만 내가 뭔가 공부를 잘못하고 있었을 수도 있겠다는 충격을 줬던 질문이였기 때문인 것 같다.
지금까지의 나 자신을 돌아보면 '신입이니까', '학부생이니까' 등의 선입견과 함께 지식을 배우거나 받아들일 때에도 스스로 무의식적인 필터링을 걸어왔던 것 같다. 조금만 사고의 틀이 넓어지면, 나의 내면에서부터 지식을 받아들이는 것을 거부해왔던 걸지도 모르겠다는 생각이 든다. 오늘의 주제도 사실 당연히 고민을 한번쯤은 해볼 수 있는 주제들인데도 '왜 이런 생각을 그동안 한번도 해보지 못했을까'라는 생각이 계속해서 머리 속에 맴돈다. 그 간의 공부는 아무래도 조금은 수정의 여지가 있어보인다.
주제와 동떨어진 얘기는 여기까지 마무리하고, 오늘의 주제를 관통하는 IP가 무엇인지부터 이해해보며 글을 시작해보고자 한다.
인터넷 프로토콜
그 이름부터 친숙한 IP는 Internet Protocol의 약자로서, 네트워크 프로토콜 중의 하나로서 드넓은 네트워크 세계에서 주소를 지정하고 라우팅하는 방식을 지정한다. 즉, 상호 연결된 네트워크 상에서 패킷을 라우팅하기 위한 프로토콜이다.
여기서, "상호 연결된 네트워크"라는 말은 말 그대로 서로 통신이 가능하다라는 것 의미한다. 인터넷을 생각해보자. 내 컴퓨터가 인터넷에 연결되어 있다면, 우리는 자유롭게 인터넷에 연결된 다른 컴퓨터로 연결을 전송할 수 있다. 반대로 인터넷에 연결하지 않고, 내 노트북과 학교 컴퓨터를 연결하려고 하면 당연히 연결이 안된다. IP는 상호 연결된 네트워크에서 작용한다.
그 다음 '패킷'이라는 용어는 네트워크 상에서 데이터를 전송할 때 사용하는 기본 단위 정도로 이해할 수 있다. 특히 L3의 네트워크 계층에서는 그 의미가 조금 더 확장되어 IP를 거친 데이터 단위를 의미한다. 만약 우리가 1GB 정도의 데이터를 전송하는 상황을 예로 들어보자. 1GB의 크기는 상당히 큰 크기이다. 컴퓨터가 1GB를 그대로 뚝 떼어다가 옮기고자 하는 컴퓨터에 전선을 따라서 뚝 떼어주면 좋겠지만 현실은 그렇게 동작하지 않는다. 우선 우리의 컴퓨터는 네트워크를 통해 전송을 시작하기 이전에 일정 크기 이상의 데이터를 작게 쪼개서 전송한다. 이때 쪼개지는 단위 하나하나가 패킷이다. 쪼개진 패킷은 목적지에서 다시 합쳐지는데 이를 통해 물리적으로 전송하기엔 너무 거대한 데이터 뭉치를 여러 패킷으로 나눠서 전송할 수 있게 되었다.
IP 패킷은 크게 '헤더(Header)'와 '페이로드(Payload)'라는 두 부분으로 이뤄지는데, 헤더 부분에는 패킷이 전송되는데 필요한 메타데이터가 들어오고, 페이로드 부분에는 전송 계층에서 쌓여져 내려온 데이터가 들어오게 된다.
본격적으로 헤더 이야기를 하기 전에 페이로드에 대해서 잠깐만 이야기를 더 해보고자 한다. 우리가 네트워크 상에 데이터를 전송하게 되면 가장 먼저 Application Layer(L7)를 거치게 된다. 예를 들어 웹 브라우저를 통해 웹페이지에 접속하거나 이메일을 보낸다면 HTTP/HTTPS 기반의 L7 관련 프로토콜을 통해 해당 요청이 처리되기 시작한다. 이때 우리가 전송하고자 하는 정보는 Header라는 메타데이터를 품고 있는 정보와 합쳐진다. 합쳐진 정보는 그렇게 다음 Layer로 전송된다.
그 후, L4에 해당하는 Transport Layer에서는 생성된 데이터를 세그먼트 형태로 분할하고 각 패킷에 헤더를 추가한다. 헤더에는 출발지 포트, 목적지 포트, 순서 정보(Seq), 오류 검출 코드 등의 정보가 포함된다. 위에서와 마찬가지로, 전달된 데이터에 추가적으로 Header가 합쳐진 다음 다음 Layer로 전송된다. 결국 L3의 IP에서 마주하는 정보는 순수한 데이터가 아니다. 위에서부터 내려오면서 헤더가 여러번 붙여진 정보를 처리해야 한다. 마찬가지로 IP 또한 이러저러한 메타 데이터를 헤더를 통해 추가한다. 그렇게 IP 또한 IP 헤더 정보와 위에서부터 여러 헤더로 감싸진 페이로드를 더하여 그 다음 L2로 넘겨주게 된다.
이런 IP에는 IPv4와 IPv6라는 두가지 버전이 존재한다. 인터넷이 등장하고 수많은 PC가 도입됨에 따라 IPv4만으로 모든 컴퓨터를 표현하기에는 곧 한계에 다다를 것이라는 의견들이 발생했다. IPv6는 그러한 문제를 해결하기 위한 해결책이다. IPv4의 경우 약 42억개의 주소를 표현할 수 있다. IPv6가 표현가능한 주소의 개수는 2^128로 이를 숫자로 표현하면 마치 무한대에 가까운 주소를 표현할 수 있음을 알 수 있다.
(총 가능한 주소의 수: "340,282,366,920,938,463,463,374,607,431,768,211,456")
그러나 두 버전의 차이는 여기에서 그치지 않는다. 헤더의 필드에서도 두 구조 간에는 주요한 차이가 있다.
먼저 IPv4의 헤더 대한 설명이다.
IPv4의 헤더 구조
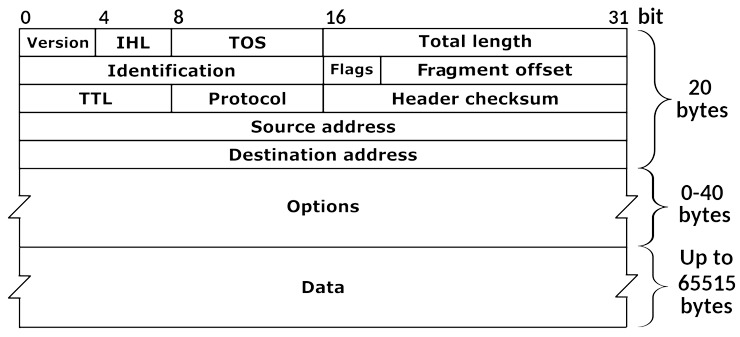
Header는 패킷의 전송에 필요한 메타데이터를 품는다. 도대체 어떤 정보들이 필요하길래 Data를 보내는데 저렇게 많은 필드가 필요할까? 각각의 필드를 이해해보자.
Version: IP 프로토콜의 버전을 나타낸다. IPv4의 경우이기에 4가 들어간다.
Header Length(IHL): IPv4의 헤더의 길이를 담는 필드로, 기본 길이는 20 Bytes로 시작하여 추가적인 옵션이 붙는 경우 60 Bytes까지도 늘어난다.
- 여담으로 IPv6의 경우 헤더의 길이가 40 Bytes으로 고정이며, 추가적으로 확장 헤더라는 개념을 사용한다. 이는 아래에서 IPv6 구조도를 설명하며 다시 설명한다.
- 4비트의 크기로 표현되는데, 헤더의 길이는 해당 비트로 표현된 이진수에 4배를 곱한 값이다.
ToS(Type of Service): 원래 QoS 정보를 담기 위해 도입된 필드였으나, 시간이 지나면서 DiffServ 및 ECN을 위한 용도로 활용된다고 한다. DiffServ가 6 MSB, ECN이 2 LSB로 표현된다. 용어가 다소 생소한데, 하단에 설명을 자세하게 적어두었으니 참고하시길 바란다.
Total Length: 전체 IP 페킷의 바이트 길이(Header + Payload)가 들어간다. 최대 65,535 바이트까지 표현가능하다 (2^16).
Identification: 16 비트로 구성되어 있으며 원본 데이터그램(Datagram)이 파편화(Fragmentation)되었을 때, 각 파편(Fragment)을 구별하기 위해 사용된다.
- 출발지 호스트에서 MTU의 제약 때문에 여러 패킷으로 쪼개진 세그먼트는 목적지 비트에서 Identification을 기준으로 다시 합쳐져서 하나의 세그먼트로 Layer 4에 전달된다.
Flags: 3비트로 구성되어 있으며 (LSB 2개만 사용), 패킷의 Fragmentation 동작을 제어하는데 활용된다.
- DF(Don't Fragment), MF(More Fragment) 비트가 존재하며, 기본값은 000이다.
- DF: 중간 라우터에 의해서 Fragmentation되지 않을 것을 표현, 001
- MF: 계속해서 추가적인 패킷들이 따라온다는 것을 표현한다. 마지막 패킷에서는 표시되지 않는다. 010
- DF와 MF는 동시에 사용될 수 있으며 (011), 패킷이 쪼개지지 말아야하며, 이후 쪼개진 값이 아직 들어오지 않았음을 의미한다.
Fragment Offset: 쪼개진 파편들의 Offset이다. 만약 패킷의 순서가 뒤죽박죽으로 들어왔다고 해도 Offset을 통해 올바른 순서로의 조립을 보장하는 필드이다.
TTL(Time to Live): 당초 패킷이 네트워크 내에서 살아있을 수 있는 시간을 의미했으나, 지금은 얼마나 많은 라우터를 거칠 수 있는지를 표시한다. 라우터를 거칠 때마다 TTL 값은 1씩 감소하며, 값이 0이 된다면 패킷은 삭제된다.
Protocol: Layer 4, 전송계층의 프로토콜명을 담는다. TCP의 경우 6, UDP의 경우 17라는 값이 담기게 된다.
Header Checksum: 헤더의 손상 여부를 가리는데 활용된다. 만약 출발지에서 계산되어 Checksum에 담긴 값과 목적지에서 계산한 Checksum 값이 다르다면 해당 패킷은 손상된 것으로 간주하여 폐기한다. 주의할 점은 IP 헤더에 대한 무결성을 검증할 뿐, TCP, UDP 세그먼트 값에 대한 무결성까지는 검사하지 않는다. 즉 헤더를 제외한 페이로드에 대해서는 무결성이 보장되지 않는다.
Chceksum의 계산 과정은 다음과 같다
- Header Checksum 필드를 0으로 설정
- IP 헤더의 모든 필드를 16 비트 단위로 쪼갬 (32 비트로 표현된 한 줄 -> 16 + 16)
- 분할된 모든 16 비트의 값을 더함. 만약 덧셈 중 오버플로우가 발생한다면 이는 LSB에 더한다.
- 더해진 값의 보수 값을 계산한다.
- 최종적으로 보수 값이 Header Checksum 필드에 저장된다.
- 목적지에 패킷을 수신할 때, 위의 계산 과정은 다시한번 반복되면, 계산된 값이 헤더에 위치한 체크섬과 일치하는지 확인한다.
Source Address & Destination Address:
- IPv4의 주소를 표현하는 필드로 각각 32 비트로 표현된다.
Options: 다양한 추가적인 기능에 대한 값들이 들어간다.
Padding: IP 헤더의 길이를 32비트의 배수로 맞추기 위해 사용되는 값이다. 특별한 의미 없이 포맷을 맞추기 위해 사용되며 필요한만큼 추가된다.
아래는 위에서 설명하지 못한 개별적인 용어에 대한 설명이다.
QoS(Quality of Service): 네트워크에서 여러 유형의 트래픽(e.g. 음성, 비디오, 데이터)이 전송되는 경우, QoS는 각 트래픽 유형에 대해서 서로 다른 우선 순위를 지정하여 네트워크 자원을 최대한 효율적으로 사용하도록 돕는다. 예를 들어 실시간 음성 통화의 경우에는 데이터 다운로드의 경우보다 높은 우선 순위를 보장받을 수 있다. 중요한 패킷이 더욱 빨리 처리된다고 생각할 수 있겠다.
DiffServ(Differential Services): 트래픽을 여러 클래스로 분류하여 각 클래스 간에 다른 처리 수준을 제공하는 기술이다. 그러나 DiffServ의 우선순위를 매핑해둔 DSCP값들을 어떻게 처리할 것인지에 대해서는 별도의 규약이 없기 때문에 강제성은 없다. 때문에 네트워크 장비를 관리하는 운영 정책에 따라 네트워크 관리자의 판단 하에, 일반적으로 우선 순위가 높다고 알려진 DSCP를 후순위로 미루는 것도 충분히 가능하다.
DiffServ의 PHB, 다음과 같은 종류의 클래스를 가지고 있다. 어디까지나 요약 정도의 느낌으로 봐주시면 좋겠다. 실제 정의는 훨씬 복잡하다.
- Default Forwarding (DF) - PHB (Per-Hop Behavior) Class: 기본 클래스로 별도의 QoS 구성 없이 전달되는 트래픽에 사용된다. (PHB: 패킷이 네트워크 장비에서 어떻게 처리될 것인지를 지정하는 '프로파일'의 일종이다. 예를 들어 PHB의 우선 순위가 높은 경우 동일한 라우터에서 패킷의 우선 순위가 다르게 처리된다.)
- Expedited Forwarding (EF) - PHB Class: 주로 낮은 지연, 패킷 손실을 요구하는 실시간 애플리케이션 (e.g. VoIP <- 음성 통화)에 사용되는 클래스이다. 가장 높은 우선 순위를 가지는 PHB이다.
- Class Selector (CS) - PHB Class: 레거시 ToS와의 호환성을 위해 도입되었으며, CS0부터 CS7까지 총 8개의 클래스를 가지고 있다. 숫자가 커질 수록 높은 우선 순위를 나타낸다.
- Assured Forwarding (AF) - PHB Class: 여러 우선 순위의 트래픽을 나타낼 수 있는 4개의 클래스로 구성되며, 각 클래스는 다시 3개의 drop precedence로 나뉜다(e.g. AF11, AF12, AF13, ... , AF43). 이때 클래스의 크기는 커질 수록, drop precedence는 낮을 수록 우선순위가 커진다. (drop precedence는 번역이 마땅치 않아 그대로 기재한다. 내림차순의 우선 순위 정도로 이해해도 좋을 것 같다.)
- Scavenger Class: 중요하지 않은 서비스들에 대해서 남은 네트워크 대역폭(bandwidth)를 할당하고 관리하기 위한 목적으로 생성. 필수적이지 않은 애플리케이션이나 시간에 민감하지 않은 서비스에서 메세지를 대량전송하고 싶은 경우 사용할 수 있다. 남은 대역폭을 사용하다보니, 중요한 프로그램의 성능을 최대한 건드리지 않으면서 추가적으로 가능한 만큼에 대해서만 자원을 사용하고 싶은 서비스에 적합하다고 한다.
ECN(Explicit Congestion Notification): 패킷의 손실을 줄이기 위해 네트워크의 혼잡을 조기에 감지하고 대응하는데 활용된다. 혼잡이 감지된다면, ECN은 트래픽을 조절하기 위해 송신자에게 별도의 알림을 전송하는 것을 통해 트래픽의 손실을 방지하거나 최소화할 수 있다.
Fragmentation(파편화): 처리가능한 단일 패킷 크기보다 크다면, 패킷을 쪼갠다.
- Datagram: 전송 계층(Transport Layer, Layer 4)에서 네트워크 계층(Layer 3)으로 전달되는 정보 단위
- 데이터 링크 계층(Data Link, Layer 2)에서 데이터를 보내기 위해서는 최대 보낼 수 있는 프레임의 수를 넘어서는 안된다. 이때 최대 보낼 수 있는 프레임의 크기를 MTU(Maximum Transmission Unit)라고 부른다.
- 만약 전송하고자 하는 패킷의 크기가 MTU를 넘는다면, 이를 파편화, 즉 쪼개야 한다.
(e.g. 4000 바이트를 보낼 예정, MTU가 1500 -> 총 3개의 Fragment 생성 ) - Layer 3, 네트워크 계층에서 수행된다. (TCP/UDP의 전송 계층을 지나온 세그먼트가 IP에 의해 여러 개의 작은 IP 패킷으로 쪼개짐)
- 출발지 호스트 혹은 라우터에서 쪼개진다. 라우터의 경우 다음 홉이 처리할 수 있는 MTU보다 크다면 이를 쪼갠다.
- IPv6의 경우에는 출발지 호스트에서만 쪼개는 것이 가능하다. 이는 Fragmentation에 의한 복잡성과 그에 따른 오버헤드를 줄이기 위함이라고 한다. 때문에 IPv6의 Layer 3에서는 경로 MTU 탐색 기술을 활용하여 최적의 MTU를 결정하여 패킷의 크기를 설정하는 과정이 추가적으로 요구된다.
IPv6의 구조도
그렇다면 IPv6는 어떨까? 버전이 늘어났으니까 필드에 대한 복잡성도 늘어나지 않았을까? 예상과 달리 IPv6의 헤더는 IPv4의 헤더보다 훨씬 간단하다. 다만, 헤더의 크기만큼은 대부분의 IPv6 패킷이 IPv4의 패킷보다 크다. 어떻게 헤더의 구조를 간략화시키면서 IPv4의 기능을 확장시켰을까? 결론부터 얘기하자면 이는 확장 헤더라는 개념을 통해 가능하다. 아래 필드 목록을 이해해보며 보다 자세하게 이해해보자.
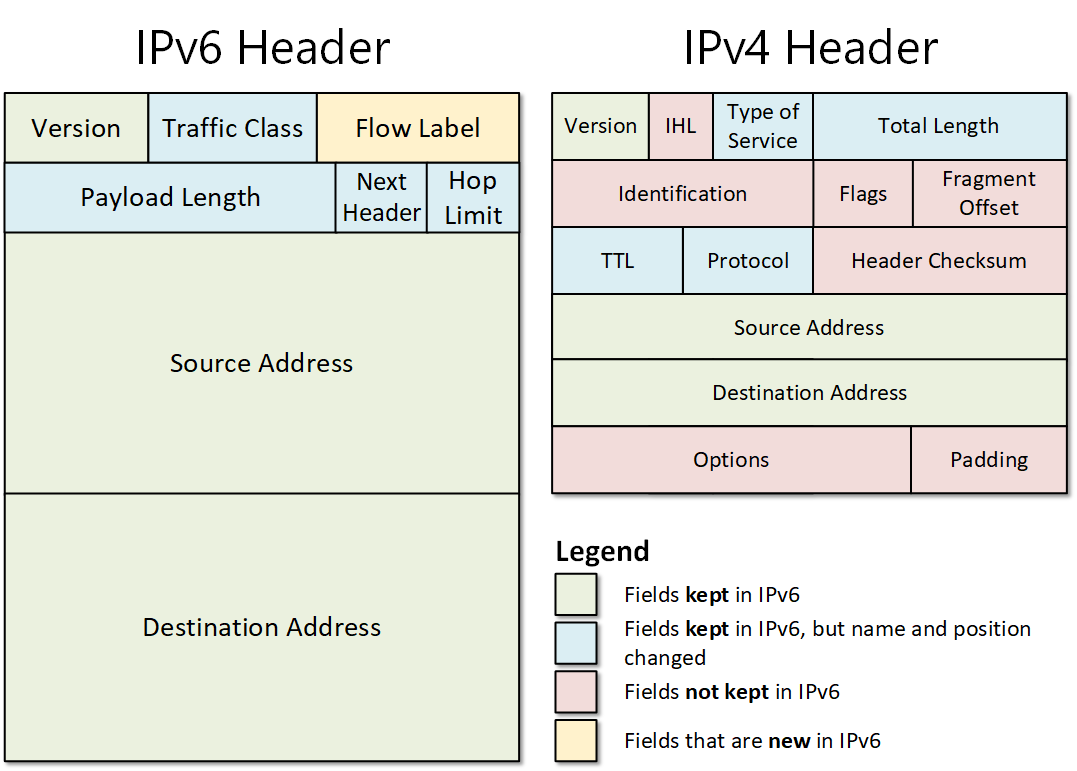
- Version: 4 Bits, IPv4의 경우와 동일하다. IPv6의 경우 6이 들어간다.
- Traffic Class: 8 Bits, IPv4의 ToS에 해당한다. 정확하게는 QoS 방식이 아닌 DiffServ 아키텍처의 ToS 필드와 일치한다.
- Tos와 동일하게 6 MSB는 DSCP를 표현하는데 활용되고, 나머지 2비트는 ESN을 표현하는데 활용된다. (위의 용어 설명 참고)
- Tos와 동일하게 6 MSB는 DSCP를 표현하는데 활용되고, 나머지 2비트는 ESN을 표현하는데 활용된다. (위의 용어 설명 참고)
- Flow Label: 20 Bits, 동일한 "흐름(Flow)", "세션(Session)"에 속하는 패킷들을 식별하는데 활용한다.
- 간단하게 말해서 흐름이라는 것은 패킷을 구분짓는 단위로서, 어떤 특정 세션, 연결 혹은 동일한 응용프로그램의 일부로 동작하는 것을 나타내는 용어이다.
- 해당 흐름에 대해서 한번 경로가 결정되면, 그 흐름에 속하는 모든 패킷들은 동일한 패킷으로 전송된다. 이는 특정 응용 프로그램 패킷들의 일관된 지연시간을 보장한다.
- 이때, 흐름 단위를 결정하는 요소로는 1) 출발지 주소:포트, 2) 목적지 주소:포트, 3) (Layer 4, 전송 계층의) 프로토콜 타입, 4) Flow Label 등이 있다.
- 예를 들어 VoIP(Voice over IP, 음성 통화)의 경우, 패킷을 일관되게 처리하는 것이 중요하다. Flow Label을 통해 VoIP 트래픽을 선별해낼 수 있다면 네트워크 장비로 하여금, VoIP 흐름에 속하는 패킷들에 대해서 우선 순위를 부여하거나 특정 경로를 선택하도록 도움을 줄 수 있다.
- 마지막으로 Flow Label의 생성은 오직 Source에서만 이뤄진다. 패킷의 전송 과정 중에 변경되는 것은 허용되지 않는 행동이다.
- 간단하게 말해서 흐름이라는 것은 패킷을 구분짓는 단위로서, 어떤 특정 세션, 연결 혹은 동일한 응용프로그램의 일부로 동작하는 것을 나타내는 용어이다.
Payload Length: 20 Bits, 페이로드의 길이를 나타낸다.
- IPv4와 달리 IPv6의 경우 헤더의 길이가 40 Bytes로 고정이다. 때문에 기존의 Total Length 필드가 Payload Length만 기록하는 것으로 변경되었다.
Next Header: 16 Bits, 다음 확장 헤더의 위치를 나타낸다.
- IPv6의 헤더의 필드들을 간소화시키는 핵심 필드이다. IPv6의 헤더는 크기가 고정적이다. 다만 이것이 표현해야할 헤더의 양이 줄어들었다는 것은 아니다. 오히려 다양한 기술의 도입으로 헤더는 더욱 무거워졌다. IPv6에서는 이를 확장 헤더를 통해 해결한다.
- 확장 헤더의 개념 자체는 어렵진 않다. Next Header 필드의 경우 다음에 오는 확장 헤더를 표시한다.
- Next Header 필드에 TCP나 UDP와 같은 전송 계층의 프로토콜 값이 들어가는 경우, 해당 확장 헤더가 마지막이라는 것을 의미한다.
- 대략적인 구조: | 기본 IPv6 헤더 (40바이트) | 확장 헤더 1 | 확장 헤더 2 | ... | 상위 계층에서 온 페이로드 |
- 예를 들어 다음의 헤더들이 존재한다.
- Hop-by-Hop Header: 패킷 경로 상의 모든 노드가 확인해야 하는 정보, e.g. 우선순위
- Authentication Header: 패킷의 인증 정보, 주로 IPsec에서 활용
- ESP(Encapsulating Security Payload) Header: 보안이 설정된 페이로드 데이터
- Fragment Header: Fragmentation된 패킷들에 대한 정보
- Routing Header: 패킷의 중간 경로에 대한 정보, 특정 라우터를 거치도록 강제할 수 있다.
- Destination Header: 최종 목적지에만 전달되는 정보, e.g. 모바일 환경에서 Source Destination에 대한 정보가 별도로 필요한 경우, 해당 헤더에 포함시킬 수 있다.
- Hop-by-Hop Header: 패킷 경로 상의 모든 노드가 확인해야 하는 정보, e.g. 우선순위
- 헤더 목록들을 살펴보면 대부분은 IPv4에서도 도입된 개념들이 대부분이다. 헤더 정보에 대한 표현 방식의 차이 정도로 이해할 수 있을 것 같다.
- 추가적인 예시를 들어보자.
- e.g. 송신자 A가 수신자 B에게 IPv6 패킷을 전송하려고 한다. 이 패킷은 라우팅 확장 헤더를 포함하고 있고, 그 다음에 TCP 세그먼트를 담고 있다. 패킷은 다음과 같이 구성된다.
- 먼저, IPv6의 기본 헤더가 온다. Next Header 값은 43(라우팅 확장 헤더)이다.
- 그 다음은 명시한 대로 라우팅 확장 헤더가 온다. Next Header 값은 6(TCP)이다.
- Next Header 값이 상위 계층의 프로토콜을 나타내므로 확장 헤더는 끝이다. 대신 IP 패킷의 페이로드, 즉 TCP의 세그먼트가 오게된다.
- e.g. 송신자 A가 수신자 B에게 IPv6 패킷을 전송하려고 한다. 이 패킷은 라우팅 확장 헤더를 포함하고 있고, 그 다음에 TCP 세그먼트를 담고 있다. 패킷은 다음과 같이 구성된다.
Hop Limit: 8 Bits, IPv4의 TTL 필드에 해당한다.
- 중간에 노드를 만날때마다 Hop Limit을 하나씩 줄인다.
- 만약 0이 된다면, 해당 패킷은 폐기한다.
Source Address & Destination Address: 128 Bits, IPv4와 동일하되 필드의 길이가 늘어났다. 아래는 IPv6 주소 체계에 대한 짧은 요약이다.
- IPv6의 주소는 16비트의 8개 그룹으로 나뉜다.
- 각 그룹은 4자리의 16 진수로 표현되며 각 그룹 간에는 콜론(:)을 통해 구분된다. (IPv4의 경우에는 8비트의 4개 그룹이다)
- IPv6에서는 연속된 0으로 표현된 그룹의 경우 ::로 축약이 가능하다.
- e.g. 2001:0db8:85a3:0000:0000:8a2e:0370:7334
-> 2001:0db8:85a3:0:0:8a2e:0370:7334
-> 2001:0db8:85a3::8a2e:0370:7334
- e.g. 2001:0db8:85a3:0000:0000:8a2e:0370:7334
- 특수한 주소
- '::1': Loop Back 주소. IPv4의 Localhost이다.
- '::': 주소가 지정되지 않은 인터페이스를 의미한다.
IPv4와 IPv6 간의 헤더 비교
이렇게 IPv4와 IPv6에 대한 헤더의 필드를 살펴보았다. 사실 하나하나가 별도의 주제로 글을 쓸 만큼 가벼운 주제가 아닌 필드들이 많기에 더욱 정확한 이해를 위해서는 추가적인 공부가 필요하지 싶다.
IPv4와 IPv6는 IP 프로토콜의 버전이므로 많은 유사점이 있을 수 밖에 없다. 그럼에도 불구하고 구체적인 헤더 구조와 필드는 상당히 다르다고 보는 것이 맞을 것이다. 특히 시각적으로 보여지는 두 버전 간의 차이는 극명해보인다.
그러나 필드 각각을 이해해보면, 사실 이름만 바뀌었다고 느껴지는 필드들도 몇몇 보인다. 예를 들어 IPv4의 TTL 필드는 원래 패킷이 네트워크 내에서 존재할 수 있는 시간을 나타내기 위한 것이었다. 그러나 현재는 패킷이 지나가는 라우터의 횟수를 제한하는 역할을 한다. 이러한 변화에도 불구하고 필드의 이름은 'Time to Live'로 유지되었는데, 이는 이름만 바뀌고 기능은 유지된 필드 중 하나로 볼 수 있다. IPv6에서는 이를 Hop Limit이라는 보다 직관적인 이름으로 변경하였다. 결국 의미는 동일하되, 이름만 변경되었다.
위의 이론을 기반으로 다음과 같이 두 버전의 헤더를 비교해보았다. 검증을 거치지 않은 개인적인 의견이기에 어디까지나 이런 의견이 있구나 정도로만 봐주시면 좋겠다.
| IPv4 Header Field | IPv6 Header Field | 설명 |
|---|---|---|
| Version | Version | IP 프로토콜의 버전을 나타냅니다. |
| Header Length (IHL) | (IPv6에는 존재하지 않음; 40 Bytes로 고정) | 헤더의 길이를 나타냅니다. |
| Type of Service (ToS) | Traffic Class | 서비스 타입 또는 트래픽 클래스를 나타냅니다. |
| Total Length | Payload Length | 전체 패킷의 길이를 나타냅니다. |
| Identification | (확장 헤더를 통해 Fragmentation 처리됨) | Fragmentation를 위한 식별자입니다. |
| Flags | (확장 헤더를 통해 Fragmentation 처리됨) | Fragmentation 옵션을 나타냅니다. |
| Fragment Offset | (확장 헤더를 통해 Fragmentation 처리됨) | Fragmentation을 통해 쪼개진 패킷의 순서를 나타냅니다. |
| Time to Live (TTL) | Hop Limit | 패킷이 네트워크에서 존재할 수 있는 최대 횟수를 나타냅니다. |
| Protocol | Next Header (TCP/UDP인 경우 다음 패킷이 페이로드) |
상위 프로토콜을 나타냅니다. |
| Header Checksum | (IPv6에는 존재하지 않음; 효율성을 위해 제거됨) | 헤더의 체크섬입니다. IPv6에서는 이 필드가 제거되었습니다. |
| Source Address | Source Address | 패킷의 출발지 주소를 나타냅니다. |
| Destination Address | Destination Address | 패킷의 목적지 주소를 나타냅니다. |
| Options (if IHL > 5) | (확장 헤더를 통해 Fragmentation 처리됨) | 추가적인 옵션을 나타냅니다. IPv6에서는 확장 헤더로 처리됩니다. |
그래서 IPv4와 IPv6의 호환은 어떻게 이뤄질까
IPv6는 기본적으로 IPv4와 많은 유사점을 공유한다. 그러나, 확장 헤더로 대표되는 IPv6의 패킷을 다루는 방식은 IPv4와 분명히 다르다. 확장 헤더는 IPv6가 IPv4에 비해 보다 유연하고 확장 가능하도록 설계된 주요한 특징 중 하나이다. 특히, 다양한 네트워크 상황과 요구사항에 대응할 수 있는 다양한 확장 헤더 타입들이 IPv6에 도입되었다. 이를 통해, IPv6는 보안, 트래픽 흐름, 라우팅 옵션 등 다양한 기능을 제공하며, 이에 그치지 않고 추후 새로운 기능이 도입되더라도 무한한 가능성을 열어둔다는 점에서 확장성이 무궁무진하다.
그럼에도 IPv4와 IPv6를 연결시키는 것은 쉽지 않다. 이를 가능하게 하는 기술로 해당 글에서는 Dual Stack, Tunneling, Translation까지 총 세가지 기술을 소개하고자 한다.
1. Dual Stack (이중 스택)
Dual Stack이라는 용어는 하나의 장비나 시스템에서 IPv4와 IPv6 두 가지 IP 버전을 동시에 지원하는 방식을 의미한다. 이 기술을 사용하면 하나의 NIC(네트워크 인터페이스 카드)에서 IPv4와 IPv6 주소를 동시에 할당받아 사용할 수 있다.
Dual Stack이 처리되는 순서는 대략적으로 이렇다.
- 주소 할당
- Dual Stack 환경의 장비에서는 IPv4와 IPv6 주소를 동시에 할당받는다.
- 물리적으로는 동일한 인터페이스이지만 버전에 따른 두 개의 주소를 가지고 있는 셈이다.
- Dual Stack 환경의 장비에서는 IPv4와 IPv6 주소를 동시에 할당받는다.
- 네트워크 스택
- 장비 내부의 네트워크 스택은 IPv4와 IPv6 프로토콜을 모두 처리할 수 있는 로직과 라이브러리를 포함한다.
- 들어오는 패킷의 버전을 확인하고 적절한 프로토콜 로직으로 패킷을 처리한다.
- 장비 내부의 네트워크 스택은 IPv4와 IPv6 프로토콜을 모두 처리할 수 있는 로직과 라이브러리를 포함한다.
- 패킷 전송
- 데이터 전송 이전에 전송하고자 하는 목적지의 IP 주소 타입(IPv4 or IPv6)을 확인한다.
- 주소 타입에 따라 적절한 IP 프로토콜 스택을 사용하여 패킷을 생성하고 전송한다.
- 데이터 전송 이전에 전송하고자 하는 목적지의 IP 주소 타입(IPv4 or IPv6)을 확인한다.
- DNS 조회
- 주소가 두개이기에 DNS 서버를 거칠 경우에도 동작이 두 버전에서 일어난다.
- 일반적으로는 A 레코드(Address record, IPv4)와 AAAA 레코드(Quad-A Record, IPv6)를 모두 반환받게 된다.
- 주소가 두개이기에 DNS 서버를 거칠 경우에도 동작이 두 버전에서 일어난다.
- 통신의 방향성
- IPv4와 IPv6의 패킷은 서로 직접 통신할 수 없다.
- Dual Stack이라 하더라도 IPv4 패킷은 IPv6 네트워크를 거칠 수 없고, IPv6의 경우에도 IPv4 네트워크를 거칠 수 없다.
- IPv4와 IPv6의 패킷은 서로 직접 통신할 수 없다.
- 풀백 매커니즘
- 만약 IPv6 통신이 실패한다면, Dual Stack 환경에서는 자동으로 IPv4를 활용하여 통신을 재시도할 수 있다.
Dual Stack 방식은 기존의 IPv4 네트워크 인프라를 크게 수정하지 않고도, IPv4와 IPv6를 모두 지원하는 장비를 통해 IPv6의 도입을 가능하게 한다. 해당 장비는 IPv4를 사용하면서도 IPv6로의 점진적 전환을 가능하게 한다는 점에서 기존 장비와의 호환성을 보장한다.
그러나 Dual Stack은 단점이 명확한 방식이다.
너무나도 자연스럽게 넘어갔지만, 2가지 주소 체계를 모두 관리하는 것은 쉬운 일이 아니다. 이는 운영 상의 복잡성을 야기한다. 또한 두 가지 IP 주소를 관리하고, 두 네트워크 스택을 유지하기 위한 추가적인 리소스도 만만치 않을 것이기에 하드웨어의 부담도 가중된다.
그럼에도 현재 많은 웹사이트와 온라인 서비스 또한 Dual Stack을 활용한 IPv6 지원을 실제 지원하고 있다고 알려져있다. 뿐만 아니라 대형 ISP나 데이터 센터에서도 Dual Stack 방식을 활용한 IPv6 전환이 이뤄지고 있다고 한다.
Dual Stack은 IPv4와 IPv6를 동시에 처리할 수 있는 하드웨어를 통해 IPv6로의 원활한 전환을 지원하는 기술라고 요약할 수 있을 듯 하다.
2. Tunneling (터널링)
앞서 언급한 Dual Stack 방식은 하드웨어가 IPv4와 IPv6를 동시에 지원하게 함으로써 문제를 해결하는 반면, 터널링은 별도의 하드웨어 없이 IPv6 패킷을 IPv4로 감싸 새로운 패킷 형태로 전송함으로써 호환성 문제를 극복한다. 즉, Dual Stack이 보다 하드웨어적인 해결에 가깝다면, 터널링은 하드웨어와 함께 소프트웨어적인 해결을 적용한다고 이해할 수 있겠다.
이때 감싸는 작업은 캡슐화(encapsulation)라고 불리는데, 캡슐화를 거친 IPv6 패킷은 IPv4 헤더로 감싸졌기에 마치 IPv4로 인식되어 라우터들을 거치게 된다. 최종적으로 목적지에 도착한 패킷은 다시 IPv4 헤더를 제거하는 과정을 거치는데 이를 비캡슐화(decapsulation)이라고 부른다. 이 과정을 거쳐 수신 측에서는 원본 IPv6 패킷을 그대로 처리할 수 있게 된다. 패킷 내의 데이터는 적절한 애플리케이션 또는 서비스로 전달된다.
터널링에는 여러 방식이 있는데, 오늘은 그 중 대표적인 6to4라는 기술을 소개해보고자 한다. 이는 6to4에서의 캡슐화는 다음의 단계를 거쳐 완성된다.
- IPv6 패킷 준비: 송신 측에서는 일반적인 방법으로 IPv6 패킷을 생성한다. 다만, 한 부분에서 평범한 IPv6 패킷과 차이가 있다.
- Prefix(CIDR): 바로 6to4을 사용하는 IPv6 패킷의 경우에는 주소의 첫 16비트가 "2002"라는 접두어로 고정된다.
- IPv4 Address: 이후 원본 IP 주소가 32비트 형태로 추가된다.
- SLA(Subnet ID):그 다음 16비트는 SLA로 채워진다. 만약 큰 조직에서 내부 서브넷을 쪼개야 한다면, 해당 비트를 활용할 수 있다.
- Interface ID: 마지막 64비트는 인터페이스 식별자로 사용된다. 일반적이라면 NIC(Network Interface Card)에 기록된 MAC 주소를 기반으로 생성된다.
- Prefix(CIDR): 바로 6to4을 사용하는 IPv6 패킷의 경우에는 주소의 첫 16비트가 "2002"라는 접두어로 고정된다.
- IPv4 헤더 생성: 송신 측에서는 IPv4 헤더를 준비한다. 이때 송신 측 주소는 6to4 기능을 수행하는 송신 측 장비의 IPv4 주소로 설정되고, 목적지 주소는 6to4 릴레이 주소(IPv6 네트워크 환경) 또는 IPv4의 형태의 목적지 주소(IPv4 네트워크 환경)로 구성된다.
- 어떤 목적지 주소 형태를 사용할지는 현재 보내고자 하는 네트워크가 어떤 IP 버전을 사용하는지에 기반한다.
- 만약 IPv6 네트워크 환경을 사용한다면, 해당 환경의 라우터들은 IPv4로 위장한 6to4를 처리할 수 없다. 때문에 6to4를 지원하는 별도의 중개자가 추가적으로 필요하다. 이를 6to4 릴레이라고 부른다.
- 어떤 목적지 주소 형태를 사용할지는 현재 보내고자 하는 네트워크가 어떤 IP 버전을 사용하는지에 기반한다.
- 캡슐화(Encapsulation): 준비된 IPv6 패킷을 위에서 생성한 IPv4 헤더의 데이터 부분에 넣는다. 즉, IPv6 패킷 전체가 IPv4 패킷의 페이로드가 된다. 6to4를 지원하는 IPv4 패킷 헤더의 필드와 IPv6 헤더의 필드 간에 일대일 변환이 이뤄지는 것은 아니다.
그럼에도 불구하고 앞서 살펴보았던 몇몇 필드들에 대해서는 두 버전 간에 어느정도의 유사성이 존재함을 확인하였다. 예를 들어 다음의 IPv6 헤더는 다음과 같이 IPv4 헤더로 변환된다.
- Version: 캡슐화가 수행되며, IPv4의 헤더에 4가 기록된다. 페이로드 내부의 IPv6 패킷은 6이 기록되어 있다.
- Source, Destination Address: 6to4 방식에 따라 앞서 설명한 터널링을 위한 IPv4 주소가 설정된다.
- Payload Length: IPv4의 Total Length 필드로 변환되기 위해서는 IPv4의 헤더와 캡슐화된 IPv6 패킷의 전체 길이가 더해진다.
- Next Header: Protocol 필드의 값이 상위 계층의 프로토콜(TCP/UDP)을 표현하지 않는다. 대신 IPv6를 표현하는 41이라는 값이 들어간다.
(참고: https://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml) - Hop Limit: TTL 필드에 그대로 복사된다.
- Version: 캡슐화가 수행되며, IPv4의 헤더에 4가 기록된다. 페이로드 내부의 IPv6 패킷은 6이 기록되어 있다.
- 패킷 전송: 완성된 IPv4 패킷은 일반적인 방법으로 IPv4 네트워크를 통해 전송된다.
- 도착 이후 6to4 패킷은 비캡슐화를 수행해야 한다. 때문에 목적지의 호스트 또한 6to4를 지원할 수 있도록 하드웨어와 소프트웨어를 지원해야 한다.
이렇게 전송된 6to4 패킷은 IPv4 환경에서는 기존 IPv4 라우터를 거쳐 처음부터 IPv4였다는 듯이 전송되고, IPv6 환경에서는 6to4를 지원하는 릴레이 라우터를 거쳐 적절하게 전송된다.
다만 6to4 방식의 경우 개인적으로 장점보다는 단점이 많다고 생각된다. IPv6 호스트를 IPv4 네트워크에 통합시킨다는 아이디어 자체는 문제가 없다. 때문에 별도의 IPv6 인프라 없이도, 기존 IPv4 인프라를 통해서 IPv6 주소체계를 활용하는 호스트를 IPv4 환경에서도 활용할 수 있게 만들어준다.
다만, 앞서 Dual Stack의 단점으로 언급했던 하드웨어 업그레이드는 여전히 6to4 방식에서도 해결되지 않는다. 오히려 캡슐화를 위한 소프트웨어에 대한 부담만 늘 수 있겠다는 생각도 든다. 그리고 캡슐화와 비캡슐화 과정 또한 추가적인 리소스를 활용하기에 호스트 머신의 리소스 활용 측면에서도 부정적인 결과를 초래한다는 점도 고려해야 한다.
두 방식을 간단하게 테이블로 비교해보자.
| Method | Advantages | Disadvantages |
|---|---|---|
| Dual Stack |
|
|
| 6to4 (Turnneling) |
|
|
3. Translation (번역)
앞선 터널링과 달리 IPv4와 IPv6 패킷을 직접 번역하여, 두 프로토콜의 직접적인 통신을 가능하게 하는 기술이다. 구체적으로 NAT64, DNS64, SIIT(Stateless IP/ICMP Translation)이라는 세가지 기술이 대표적이다.
NAT64
- IPv6-only 클라이언트가 IPv4 서비스에 액세스할 수 있게 하는 변환 매커니즘이다.
- 세션을 통해 상태를 유지하며(Stateful), 저장된 연결 상태 정보를 통해 IPv4와 IPv6 주소를 서로 매핑시켜놓는다.
- 실제 네트워크 환경에서 단독으로 사용되기보다는 DNS64와 함께 사용되어, IPv6 클라이언트가 IPv4 웹사이트에 접근할 수 있도록 도와준다.
- IPv4-only 주소를 IPv6 형태로 변환하는데는 활용되지 않기 때문에, 이는 별도로 464XLAT라는 기술을 활용해야 한다.
DNS64
- IPv6-only 클라이언트가 IPv4-only 목적지의 DNS 질의를 수행할 때 IPv4의 응답을 받아 IPv6 주소로 변환해 반환하는 기술이다.
- 실제 웹서비스 환경에서는 클라이언트는 대체로 DNS 질의를 통해 목적지의 IP 주소를 확인한다. IPv6-only 클라이언트가 DNS 질의를 실행하는 경우 만약 DNS에 저장된 응답이 A 레코드 (IPv4)라면, DNS64는 이를 AAAA 레코드 (IPv6) 형태로 변환하여 클라이언트에게 반환한다.
- 반환된 AAAA 레코드는 패킷의 목적지 주소에 담긴다. 그대로 보내는 경우 IPv6 인프라가 아니라면 목적지를 찾을 수 없을 것이다.
- 이 경우 NAT64 기술이 활용된다. AAAA 레코드는 NAT64를 거쳐 원래의 A 레코드로 다시 변환되며 그 후 변환된 A 레코드를 기반으로 IPv4 패킷을 원래의 IPv4 목적지로 전송한다.
SIIT (Stateless IP/ICMP Transition)
- 상태가 없는 변환을 제공한다. 이는 직전의 NAT64와 정확히 반대되는 내용이다.
- 별도의 세션을 활용하지 않기 때문에 각 패킷은 개별적이다.
- A 레코드를 AAAA 레코드로 변화시키거나 그 반대의 경우도 가능하다.
- 별도의 세션 관리가 없다는 점은 곧 장점이자 단점으로 작용한다.
- 예를 들어 대규모의 네트워크의 경우, 굳이 세션을 사용해도 되지 않아도 되는 서비스라면 이는 메모리 사용량 측면에서 큰 이점을 가져다준다. 또한 세션 테이블의 관리가 필요없다는 점은 운용과 관리 측면에서 훨씬 유리하다.
- 그러나 만약 별도의 세션을 통해 관리가 필요한 애플리케이션이라면 SIIT를 사용할 수 없다.
- e.g. 동적 포트 할당
- Stateful 변환에서는 세션의 상태를 추적하므로, 클라이언트나 서버에서 동적으로 할당된 포트에 대한 매핑을 유지할 수 있다.
- 만약 포트 할당이 새롭게 필요한 경우, 해당 포트 번호에 대한 변환을 동적으로 수행한 후 이를 세션 테이블에 저장하게 지속적으로 추적할 수 있다.
- Stateful 변환에서는 세션의 상태를 추적하므로, 클라이언트나 서버에서 동적으로 할당된 포트에 대한 매핑을 유지할 수 있다.
- e.g. 동적 포트 할당
- 예를 들어 대규모의 네트워크의 경우, 굳이 세션을 사용해도 되지 않아도 되는 서비스라면 이는 메모리 사용량 측면에서 큰 이점을 가져다준다. 또한 세션 테이블의 관리가 필요없다는 점은 운용과 관리 측면에서 훨씬 유리하다.
여기까지해서 내용이 마무리되었다. 다른 분야도 마찬가지지만 네트워크 분야야 깊게 파고들어갈 수록 정말 끝이 없다는 느낌을 많이 받는다. 사실 간단하게 주제만 정리하고 글을 마무리했었어도 됐지만, 내 스스로가 IPv6에 대해서 이해를 잘 하고 있지 못하고 있다는 느낌을 받게되어 글이 쓸데 없이 길어지고 말았다.
아무쪼록 주제 자체도 흥미롭고, 내용이 (너무) 많은 거 말고는 이해가 그렇게 어렵지 않기에 한 번 익혀두고 다시 읽어보면 금방 기억이 날 듯 하다. 부족한 네트워크 지식이 조금은 늘었다고 생각하니 행복하다.
'CS' 카테고리의 다른 글
| L7 프로토콜 - HTTP (0) | 2023.08.08 |
|---|---|
| 정적 라이브러리 (0) | 2022.12.05 |
| 실행가능한 목적파일 (0) | 2022.12.03 |
| Linking(링킹) 소개 (0) | 2022.12.02 |
| 시간 지역성을 위한 캐시 재배치 (0) | 2022.12.01 |
class Solution:
def diagonalSum(self, mat: List[List[int]]) -> int:
n = len(mat)
answer = 0
for i in range(n):
answer += mat[i][i] + mat[i][n - i - 1]
if n % 2 != 0:
answer -= mat[n // 2][n // 2]
return answer'CS > 알고리즘' 카테고리의 다른 글
| [Leetcode] 34. Find First and Last Position of Element in Sorted Array (0) | 2023.05.09 |
|---|---|
| [Leetcode] 1498. Number of Subsequences That Satisfy the Given Sum Condition (1) | 2023.05.06 |
| [Leetcode] 1456. Maximum Number of Vowels in a Substring of Given Length (0) | 2023.05.06 |
| [Leetcode] 649. Dota2 Senate (0) | 2023.05.05 |
| [Leetcode] 986. Interval List Intersections (0) | 2023.05.05 |
import bisect
class Solution:
def longestObstacleCourseAtEachPosition(self, obstacles: List[int]) -> List[int]:
lis = []
result = []
for obstacle in obstacles:
idx = bisect.bisect_right(lis, obstacle)
if idx == len(lis):
lis.append(obstacle)
else:
lis[idx] = obstacle
print(idx, lis, obstacle)
result.append(idx+1)
return result'CS > 알고리즘' 카테고리의 다른 글
| [Leetcode] 1572. Matrix Diagonal Sum (0) | 2023.05.09 |
|---|---|
| [Leetcode] 1498. Number of Subsequences That Satisfy the Given Sum Condition (1) | 2023.05.06 |
| [Leetcode] 1456. Maximum Number of Vowels in a Substring of Given Length (0) | 2023.05.06 |
| [Leetcode] 649. Dota2 Senate (0) | 2023.05.05 |
| [Leetcode] 986. Interval List Intersections (0) | 2023.05.05 |
[Leetcode] 1498. Number of Subsequences That Satisfy the Given Sum Condition
class Solution:
def numSubseq(self, nums: List[int], target: int) -> int:
answer = 0
nums.sort() # O(NlogN)
left, right = 0, len(nums) - 1
while left <= right: # O(N)
if nums[left] + nums[right] <= target:
if (left - right) in [0, 1]:
answer += 1
else:
answer += pow(2, right - left)
left += 1
else:
right -= 1
return answer % (10**9 + 7)'CS > 알고리즘' 카테고리의 다른 글
| [Leetcode] 1572. Matrix Diagonal Sum (0) | 2023.05.09 |
|---|---|
| [Leetcode] 34. Find First and Last Position of Element in Sorted Array (0) | 2023.05.09 |
| [Leetcode] 1456. Maximum Number of Vowels in a Substring of Given Length (0) | 2023.05.06 |
| [Leetcode] 649. Dota2 Senate (0) | 2023.05.05 |
| [Leetcode] 986. Interval List Intersections (0) | 2023.05.05 |
class Solution:
def maxVowels(self, s: str, k: int) -> int:
q = collections.deque(s[:k])
vowel = ['a', 'e', 'i', 'o', 'u']
count = 0
max_count = 0
for v in vowel:
count += s[:k].count(v)
max_count = max(max_count, count)
i = k
while i < len(s):
if q.popleft() in vowel:
count -= 1
x = s[i]
q.append(x)
if x in vowel:
count += 1
max_count = max(max_count, count)
if count == k:
return k
i = i + 1
return max_count'CS > 알고리즘' 카테고리의 다른 글
| [Leetcode] 34. Find First and Last Position of Element in Sorted Array (0) | 2023.05.09 |
|---|---|
| [Leetcode] 1498. Number of Subsequences That Satisfy the Given Sum Condition (1) | 2023.05.06 |
| [Leetcode] 649. Dota2 Senate (0) | 2023.05.05 |
| [Leetcode] 986. Interval List Intersections (0) | 2023.05.05 |
| [Leetcode] 844. Backspace String Compare (0) | 2023.05.05 |
class Solution:
def predictPartyVictory(self, senate: str) -> str:
A = collections.deque()
people = [0, 0]
bans = [0, 0]
for person in senate:
x = person == 'R'
people[x] += 1
A.append(x)
while all(people):
x = A.popleft()
people[x] -= 1
if bans[x]:
bans[x] -= 1
else:
people[x] +=1
bans[x^1] += 1
A.append(x)
return 'Radiant' if people[1] else 'Dire''CS > 알고리즘' 카테고리의 다른 글
| [Leetcode] 1498. Number of Subsequences That Satisfy the Given Sum Condition (1) | 2023.05.06 |
|---|---|
| [Leetcode] 1456. Maximum Number of Vowels in a Substring of Given Length (0) | 2023.05.06 |
| [Leetcode] 986. Interval List Intersections (0) | 2023.05.05 |
| [Leetcode] 844. Backspace String Compare (0) | 2023.05.05 |
| [Leetcode] 82. Remove Duplicates from Sorted List II (0) | 2023.05.04 |
class Solution:
def intervalIntersection(self, firstList: List[List[int]], secondList: List[List[int]]) -> List[List[int]]:
answer = []
i, j = 0, 0
if len(firstList) == 0 or len(secondList) == 0:
return []
while i < len(firstList) and j < len(secondList):
if firstList[i][1] < secondList[j][0]:
i += 1
elif secondList[j][1] < firstList[i][0]:
j += 1
else:
intersection_start = max(firstList[i][0], secondList[j][0])
intersection_end = min(firstList[i][1], secondList[j][1])
answer.append([intersection_start, intersection_end])
if firstList[i][1] < secondList[j][1]:
i += 1
else:
j += 1
return answer
더 간단한 접근
class Solution:
def intervalIntersection(self, A, B):
i, j, ans = 0, 0, []
while i < len(A) and j < len(B):
curr = [max(A[i][0], B[j][0]), min(A[i][1], B[j][1])]
if curr[0] <= curr[1]:
ans.append(curr)
if A[i][1] <= B[j][1]:
i += 1
else:
j += 1
return ans'CS > 알고리즘' 카테고리의 다른 글
| [Leetcode] 1456. Maximum Number of Vowels in a Substring of Given Length (0) | 2023.05.06 |
|---|---|
| [Leetcode] 649. Dota2 Senate (0) | 2023.05.05 |
| [Leetcode] 844. Backspace String Compare (0) | 2023.05.05 |
| [Leetcode] 82. Remove Duplicates from Sorted List II (0) | 2023.05.04 |
| [Leetcode] 2215. Find the Difference of Two Arrays (0) | 2023.05.03 |