



신경망에서는 데이터 간의 연관 관계를 기억하는 능력을 가지고 있고, 데이터로부터 연관관계를 표현할 수 있는 특정한 수식을 자동으로 찾아내는 동작을 수행합니다.
그러면 어떤 동작을 수행하기에 신경망에서는 자동으로 수식을 찾아낼 수 있는 걸까요. 바꿔 말해 신경망은 어떻게 학습을 수행하는 것일까요. 해당 글에서는 신경망의 학습이라는 주제로 해당 궁금증을 해결해보도록 하겠습니다.

해당 그림은 간단한 형태의 뉴럴 네트워크입니다.
뉴럴 네트워크는 가장 왼쪽에 입력 데이터가 들어오면, 가장 오른쪽에 출력 데이터를 내보내게 됩니다. 그 사이에는 다양한 선들과 동그라미가 보입니다.

이떄 선들은 각자 고유한 값을 가지게 되며, 선들은 자신의 왼쪽 동그라미의 값과 자신이 가진 값을 곲아여 오른쪽 동그라미로 넘겨줍니다. 동그라미는 이때 들어오는 모든 값을 더해 자신의 값으로 두게 됩니다. 그리고 더한 값이 0보다 크면 오른쪽으로 내보내고 0보다 작으면 아무것도 하지 않습니다.
또한 첫 번째로 제시된 그림을 살펴보면 아래 x 축 쯔음에 layer라는 글씨가 연속적으로 보일 것입니다. 신경망은 이러한 layer의 연속으로 구성됩니다. 모든 layer를 함께 보면 복잡해보이지만 일부만 따로 떼어서 보면 다음과 같습니다.

1th 동그라미 x 0.1 + 2th 동그라미 x 0.2 + 3th 동그라미 x 0.5 와 같은 형태로 표현이 가능합니다.
이러한 구조를 통해 뉴럴 네트워크에 존재하는 선들이 어떤 수식을 구성하는데에 사용됩니다. 선들의 값이 바뀌면 뉴럴 네트워크가 표현하는 수식 또한 바뀌게 됩니다.
즉 뉴럴 네트워크 학습의 핵심은 선들의 값을 잘 찾아내는 것이라고 할 수 있겠습니다.
올바른 선들의 값을 찾아낸다면, 연관관계를 잘 표현하는 수식을 만들어낼 수 있게 되고, 결국 연관관계를 잘 기억해내는 잘 학습된 뉴럴 네트워크가 완성되는 것입니다. 이때 선의 값을 가중치(Weight)라는 용어로 부르게 됩니다.
그런데 적절한 가중치를 찾는 것은 상당히 어려운 문제입니다. 최신 뉴럴 네트워크에서는 이러한 가중치 값들을 수천만개 많게는 수천억개 이상을 가지고 있습니다. 어떻게 적절한 가중치 값들을 찾을 수 있을까요?
수십년 동안 많은 방법들이 제시되어 왔지만, 그 중 상당히 많이 사용되는 역전파 알고리즘에 대해서 설명하고자 합니다.

학습에 앞서 다음과 같은 데이터셋이 있다고 가정해봅시다. 우리는 강아지와 고양이를 분류해야 합니다. 앞서 제시된 데이터에서는 해당 데이터가 어떤 동물인지에 대해서 애노테이션(라벨이라고도 불림)을 갖고 있습니다.
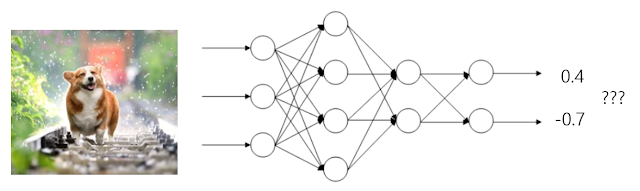
신경망 학습 이전에는 이미지를 넣어도 예측을 정상적으로 할 수 없겠죠. 강아지 이미지를 넣으면 (1, 0)의 값이 나오는 것이 이상적이지만 지금은 (0.4, -0.7)의 잘못된 값이 나옵니다. 이를 개선하여 (1, 0)의 값이 나올 수 있도록 개선해야 합니다.
조금 바꿔말하면 목표(데이터셋)와 현상태(현재 네트워크의 동작)의 차이를 최소화 하는 방향으로 선의 값을 변경해야 합니다. 현재 차이를 계산해보면 (0.6, 0.7)만큼의 괴리가 발생함을 알 수 있습니다.
이제 이 둘의 차이를 최소화하는 것에 집중하면 뉴럴 네트워크를 올바르게 학습시킬 수 있습니다. 이 둘의 차이를 손실 함수(Loss function)이라고 하며, 우리는 손실 함수의 값이 최소가 되도록 하는 것을 목표로 합니다.
이때 수많은 선 중 하나의 선을 A라고 할 때, A의 값을 잘 바꾸면 손실 함수를 작아지게 할 수 있습니다. 그러기 위해서는 A 값의 변화와 손실 함수 값 사이에 어떤 관계가 있는지를 알아내야 합니다. A 값의 변화에 따라 손실 함수가 커질 수도 있고 작아질 수도 있습니다. 이 정보는 미분 계산을 통해 가능합니다.
이렇게 얻어낸 정보를 바탕으로 A 값을 손실 함수가 줄어드는 방향으로 수정하는 것이 역전파 알고리즘의 아이디어 입니다.
이러한 역전파 알고리즘을 A, B, C 등의 신경망 내의 모든 선들에 대해 사용합니다. 또 데이터셋에 있는 다른 사진들에 대해서도 같은 과정을 반복합니다. 이미지를 넣어서 손실 함수를 계산하고, 미분 계산을 거쳐, 선들의 값을 변경하는 과정을 계속 반복하는 것입니다.
그러한 과정을 계속 반복하면, 어느 순간 잘못된 값을 내보내던 네트워크는 역전파 알고리즘을 반복함에 따라 손실 함수의 값이 함수의 최소값에 다다르게 되고 최종적으로 올바른 동작을 할 수 있는 네트워크가 됩니다.

Appendix. 역전파 알고리즘 (BackPropagarion의 수학적 원리 가볍게 설명)
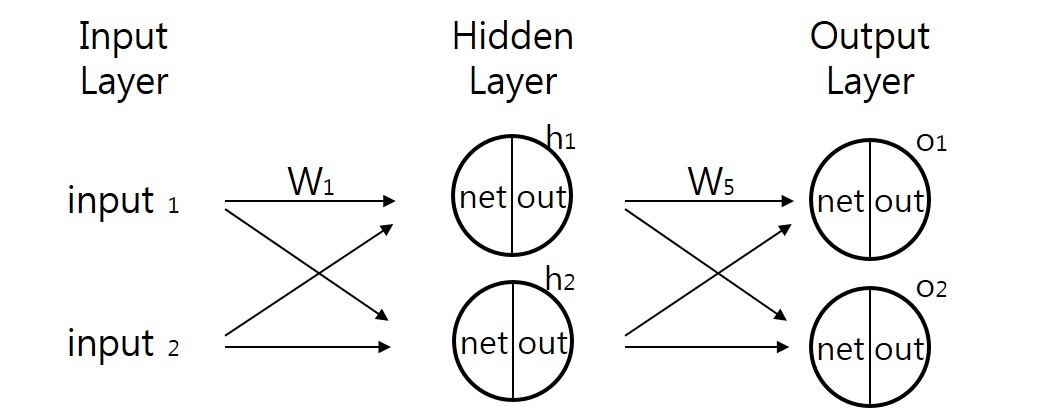
역전파 알고리즘을 조금 더 심층적으로 살펴보겠습니다. 역전파 알고리즘은 input과 output을 알고있는 상태(=supervised learning)에서 신경망을 학습시키는 방법입니다. 역전파가 사용되는 딥러닝은 MLP(multi-layer perceptron, 다층 신경망)이론의 일종으로 다음과 같은 MLP의 특징을 공유합니다.
- 초기 가중치, Weight 값은 랜덤으로 주어진다. (이를 Ground Truth 라고 합니다)
- 각각의 노드(동그라미)는 하나의 퍼셉트론으로 생각할 수 있다. 즉 노드를 지나칠 때마다 활성함수를 적용하게 된다. 활성함수를 적용하기 이전을 Net 이후를 Out이라고 한다면, 다음 레이어의 계산은 Out 값을 사용하게 되며, 마지막 Out이 최종적인 output이 된다.
- 활성함수는 시그모이드 함수로 한다. 주로 미분의 용이성으로 인해 자주 사용된다.
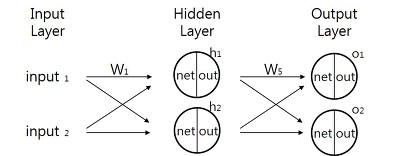
우리가 결과 값으로 얻기를 바라는 값이 Target, 실제로 얻게된 값이 Output이라고 하며 오차 E는 다음과 같이 계산됩니다.
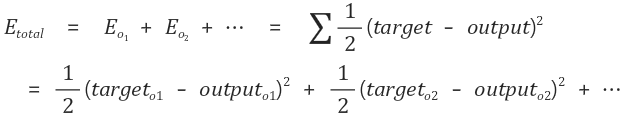
이때의 합의 의미는 모든 output에서 발생한 모든 오차를 더해주는 것입니다. 최종 목적은 이 오차에 관한 E의 함수(Loss Function) 값을 0에 근사시키는 것이며, 오차가 0에 가까워지면 신경망은 학습에 사용된 input들과 그에 유사한 input에 대해서 우리가 원하는 output 정답이라고 할 수 있는 값들을 산출할 것입니다.
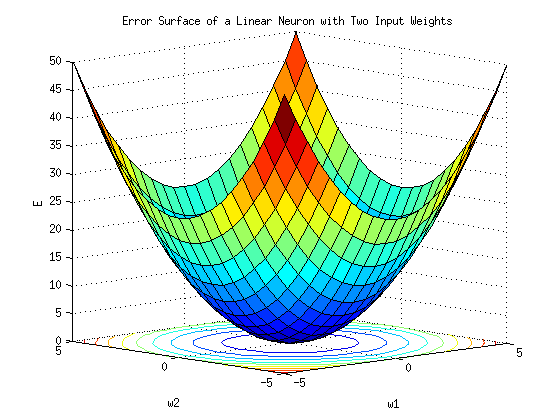
오차 E를 모든 가중치 W1 ... Wn에 대한 방정식으로 본다면 우리가 해야하는 일은 가중치 w를 수정하여 E가 최소가 될 수 있도록 하는 것입니다. 이를 위해 사용하는 것이 경사 감소법(gradient descent)라는 최적화 알고리즘입니다. 기본원리는 기울기가 낮은 쪽으로 연속적으로 이동시켜 값이 최소가 되는 점(극값)에 다다르도록 하는 것입니다.
알고리즘 자체는 단순한데, 총 4단계 정도로 세분화가 가능합니다.
1. 기존에 설정되어 있는 가중치를 사용해서 net, out을 계산합니다. (forward pass)
2. 전체 오차를 각 가중치로 편미분한 값을 기존 가중치에서 빼줍니다.
3. 모든 가중치에 대해서 2를 실행합니다. (output에 가까운 쪽에서 먼 쪽으로)
4. 1~3을 학습 횟수만큼 반복합니다.
이때 output에서 가까운 쪽에서부터 갱신하는 이유는 가까운 쪽에서 사용한 값을 먼 쪽의 계산과정에서 다시 사용하기 때문입니다.
여기까지해서 역전파의 수학적 원리에 대해서도 가볍게 알아보았습니다. 편미분 과정을 포함하여 본격적인 수식 전개는 추후 올라오는 글에서 다시 다루도록 하겠습니다.
'AI' 카테고리의 다른 글
| CNN 가벼운 정리 (1) | 2022.12.08 |
|---|---|
| CNN (Convolutional Neural Networks) (2) | 2022.12.08 |
1) CNN의 장점
- Grid가 있는 데이터에 유리하다 (이미지, 시계열 데이터)
- 다른 뉴럴 네트워크에 비해 paramter의 수가 적어 시간이 적게 걸리고, 오버피팅의 가능성도 상대적으로 낮다.
- input의 크기에 비교적 영향을 덜 받는다.
2) CNN의 단점
- Pooling 과정에서 정보 손실이 발생할 수 있다.
- 파라미터 수의 감소로 인해 연산량은 감소가 있으나, 촘촘한 convolution 연산 수행을 위해서는 큰 연산량이 요구된다.
3) 필터는 왜 필요한가
필터는 이미지의 특징을 추출하기 위한 공용 파라미터이다. Filter를 Kernel이라고도 하며, convolution 과정에서 필터를 거치지 않고 곧바로 flatten layer로 들어가게 되는 경우 spatial or tolopological 한 특성을 잃을 수 있다.
4) 점점 작은 필터를 쓰는 이유는?
과거에는 데이터의 양이 적고 컴퓨터의 성능도 좋지 않아 아키텍처의 depth를 크게 갖지 못했기 때문에 filter size를 크게 설정할 수 밖에 없엇으나, 최근에는 그러한 제약이 사라져서 filter size를 작게하여 depth를 깊게 하여 비선형성을 추가하고 high level의 feature를 추출하는 것이 목표가 되었다.
5) 패딩은 왜 필요한가
Convolution layer에서 Filter를 활용하여 계산된 결과 결과값(Feature Map)의 크기는 입력데이터보다 작아지는데, 이때 출력 데이터가 줄어드는 것을 방지하는 방법이 패딩이다. 패딩은 입력 데이터의 외곽에 픽셀만큼 특정 값으로 채워 넣는 것을 의미하며 보통 패딩 값으로 0을 채워넣는다. 이를 통해 가장자리에 위치한 정보(feature)를 살릴 수 있게 된다.
6) 풀링은 왜 필요한가
Convolution 레이어의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄일 수 있다. 중요한 feature를 강조하는 한편, 중요하지 않은 feature 또는 중복된 정보를 사라지게 하여 넓은 범위의 정보를 축약해서 볼 수 있다.
7) Convolutional layer의 출력 데이터 크기 공식
((N - F + 2P) / S) + 1 ( N: 기존 size, F: filter size 크기, P: padding 크기, S: stride크기)
예시: AlexNet에서 입력 이미지의 크기는 227x227x3 이다. 첫 번째 컨볼루션 레이어는 11x11x3 크기의 커널 96개를 갖는다. 스트라이드는 4이고 패딩은 0이다. 이때 출력값(Feature Map)의 크기는?
(227 - 11 + 2 * 0) / 4 + 1 = 55
=> (55, 55, 96)
8) Pooling 레이어 출력 데이터 크기 공식
N-F'/S+1 (N: 기존 size, F': Pooling size, S:stride 크기)
Convolutional 레이어 공식을 그대로 써도 된다
(차이는 1) padding은 없어서 0으로 놓는다 2) filter size 대신 pooling size를 넣는다)
위의 예시에 이어서 Pooling size가 3이고 stride가 2인 pooling layer의 결과 값은?
(55 - 3) / 2 + 1
=> (27, 27, 96)
9) Convolutional 레이어의 학습 파라미터수를 구하시오
1) wieght 수 : (입력 채널 수)x (필터폭) x (필터 높이) x (커널 수)
2) bias 수 : (커널수)
3) parameter 수 = weight 수 + bias 수 = (입력 채널 수) x (필터폭) x (필터 높이) x (커널 수) + (커널수)
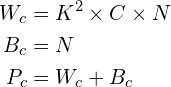
AlexNet에서 입력 채널의 수가 3, 커널 사이즈가 11, 커널의 수가 96 인 경우 가중치, 편향, 파라미터 수를 모두 구하시오.
1) 입력 데이터는 채널 수와 상관없이 필터 별로 1개의 피처 맵이 만들어진다. (O)
: 입력 데이터가 여러 채널을 갖을 경우 필터는 각 채널을 순회하며 합성곱을 계산한 후, 채널별 피처 맵을 만듭니다. 그리고 각 채널의 피처 맵을 합산하여 최종 피처 맵으로 반환합니다.
2) Pooling 레이어는 학습대상 파라미터가 없다(O)
3) Pooling 레이어를 통과하면 행렬의 크기 감소한다.(O)
4) Pooling 레이어를 통과하면 채널 수가 변경되지 않는다(O)
5) Convolutional 레이어에서 filter의 수만큼 dimension이 정해진다 (O)
'AI' 카테고리의 다른 글
| 신경망에서 학습을 시킨다는 의미 (1) | 2022.12.08 |
|---|---|
| CNN (Convolutional Neural Networks) (2) | 2022.12.08 |
1. 합성곱 신경망 (CNN, Convolution Neural Networks)
CNN은 Convolution Neural Network의 약자로 딥러닝에서 주로 이미지나 영상 데이터를 처리할 때 쓰이며 이름에서 알 수 있듯 Convolution이라는 전처리 작업이 들어가는 뉴럴 네트워크 모델입니다.
1.1 일반적인 DNN 방식의 뉴럴 네트워크와의 비교
합성곱 신경망 CNN은 일반적인 뉴럴 네트워크와 아주 유사합니다. 뉴런과 학습가능한 가중치와 편향으로 구성되어 있다는 점, 각 뉴런은 입력값을 받아 곱(dot product)연산을 수행하며 비선형성을 따릅니다. 또 마지막 층에는 손실함수(Loss function)이 있으며, 일반적인 뉴럴 네트워크를 학습하기 위해 고안한 팁과 트릭들도 여전히 적용 가능합니다.
다만, 한가지 단적인 차이가 존재합니다. 바로 CNN은 입력값이 이미지라는 가정을 깔고 간다는 것이 그것입니다.
1.1.1 일반적인 DNN 방식의 뉴럴 네트워크
뉴럴 네트워크는 입력 값(single vector)를 받아서 은닉층(hidden layer)를 거쳐 변환시킵니다. 매 은닉층은 뉴런의 집합으로 구성되어 있으며 각 뉴런은 이전 층의 모든 뉴런과 완전 연결(fully connected)되어 있습니다. 마지막으로 완전 연결된 뉴런은 출력층(output layer)이라고 불리며 분류 문제에서 각 class의 점수를 나타내게 됩니다.
사실 일반적인 뉴럴 네트워크는 이미지 데이터(full image)에는 잘 맞지 않습니다. 예를 들어 CIFAR-10에서 이미지는 32x32x3 (wide, high, color channel)이기 때문에 일반적인 뉴럴네트워크에서 첫 은닉층에 있는 완전 연결(fully connected) 뉴런은 32*32*3으로 총 3072 개의 가중치를 갖게 될 것입니다. 만약 이보다 더 거대한 사이즈의 이미지라면 어떻게 될까요? 예를 들어 200x200x3의 이미지라면 총 12만 개의 가중치가 필요합니다. 이와 같은 완전 연결(fully connected)이라는 특성은 효율적이지 않고(wasteful), 아주 많은 파라미터수를 강제하게 됩니다. 또한 아주 많은 파라미터 수는 빠른 오버피팅으로 이어진다는 한계점이 존재합니다.
*CIFAR-10: 일반적으로 머신 러닝 및 컴퓨터 비전 알고리즘을 훈련시키는 데 사용되는 이미지 모음
일반적인 뉴럴네트워크의 한계점
1. 이미지를 입력값으로 받을 때, 파라미터수가 많이 필요함(오버피팅 발생 가능성 높음)
2. 중복된 이미지의 정보가 많을 수 있음
3. 픽셀이 하나만 이동(shift)하더라도 다른 이미지로 해석
4. 이미지 내의 특징이 어디에 위치하느냐에 따라 동일하게 해석하지 못함
1.1.2 합성곱 신경망 (CNN)
합성곱 신경망은 입력 데이터가 이미지로 이루어졌다는 가정을 바탕으로 하기 때문에 이미지가 입력으로 들어오는 상황에서 아키텍처를 더 합리적으로 제한할 수 있다는 것에 이점이 있습니다. 일반적인 뉴럴 네트워크와 다르게 ConvNet의 레이어들은 (wide, height, depth)의 3차원의 뉴런으로 구성되어 있습니다. 앞으로 다루겠지만 fully connected 방법과 다르게 CNN에서 한 층의 뉴런은 이전 층의 작은 영역에만 국소적으로 연결됩니다. 또한 CIFAR-10의 최종 출력층은 1x1x10 차원입니다. ConvNet의 아키텍쳐를 활용하여 우리는 이미지(full image)를 class 점수로 이뤄진 단일 벡터로 축소할 수 있습니다.
1.1.3 비교
DNN의 경우 기본적으로 1차원 형태의 데이터를 사용합니다. 때문에 이미지가 입력값이 되는 경우 이를 flatten하여 한 줄 데이터로 만들어야 하지만, 1) DNN의 flatten을 이미지에 그대로 적용하면 이미지의 공간적/지역적 정보(spatial/topological information)가 손실되게 됩니다. 또한 2) 추상화 과정 없이 바로 연산 과정으로 넘어가기 때문에 학습의 능률과 효율성이 저하됩니다.

예를 들어 어떠한 이미지가 주어졌을때 이것이 새의 이미지인지 아닌지를 결정할 수 있는 모델을 만들고 싶다고 가정합시다. 그렇다면 새의 주요한 특징인 새의 부리가 중요한 포인트가 될 수 있을 것입니다. 때문에 주어진 이미지에 새의 부리가 있는지 없는지를 판가름 하는 것이 중요한 척도가 될 것입니다. 하지만 새의 전체 이미지에서 새의 부리 부분은 비교적 작은 부분입니다. 때문에 모델이 전체 이미지를 보는 것보다 새의 부리 부분만을 잘라 보는 것이 더욱 효율적이라고 기대할 수 있습니다. 이를 가능하게 해주는 것이 CNN입니다. CNN의 뉴런이 패턴(부리)을 파악하기 위해서는 전체 이미지를 전부 볼 필요가 없습니다.
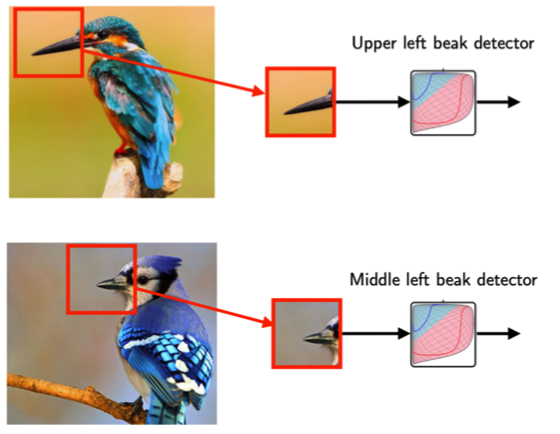
또한 위의 두 이미지에서 새의 부리 부분은 이미지의 다른 부분에 위치해 있다는 것을 알 수 있습니다. 위쪽의 이미지는 왼쪽 상단에 아래의 이미지는 중앙에서 살짝 위쪽 부분에 부리가 위치합니다. 이처럼 전체적인 이미지를 전부 살펴보기보단 이미지의 부분부분을 캐치하는 것이 더욱 효율적일 수 있습니다.
2. CNN의 주요한 컨셉들
본격적으로 CNN을 구성하는 주요한 컨셉들을 살펴보도록 하겠습니다.
2.1 Convolution의 작동 원리
우선 2차원의 이미지를 예로 들어봅시다. 2차원의 이미지는 픽셀 단위로 구성되어 있습니다.

위의 이미지는 MNIST Dataset에서 추출한 샘플 중의 하나이며 손글씨로 쓰여진 '8'의 gray scale 이미지 입니다. 28x28 단위의 픽셀로 구성되어 있으며 우리는 이 데이터 입력 값을 28x28 matrix로 표현할 수 있습니다. 즉 우리는 2차원 이미지를 matrix로 표현할 수 있다는 뜻입니다. 우리가 CNN에 넣어줄 입력값은 다음과 같이 matrix로 표현된 이미지입니다.

조금 더 간략한 예를 위해 위와 같이 5x5의 matrix로 표현된 이미지 입력값이 있다고 가정합시다. 그리고 CNN에는 필터(커널)가 존재합니다. 위의 예시의 경우에는 3x3 크기의 필터입니다. 쉽게 표현하면 이 하나의 필터를 이미지 입력값에 전체적으로 훑어준다고 생각하면 됩니다. 즉 우리의 입력값 이미지의 모든 영역에 같은 필터를 반복 적용해 패턴을 찾아 처리하는 것이 목적입니다. 그렇다면 이미지 위에 이 필터를 훑어줄때 어떤 일이 일어날까요? 정확히 말하면 이 필터를 이용해 연산처리를 해주는 것입니다. 그리고 이 연산처리는 matrix와 matrix 간의 Inner Product라는 것을 사용합니다.
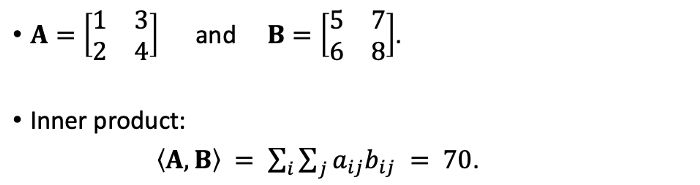
Inner Product는 결국 쉽게 말해 두 matrix를 놓고 각 위치에 있는 숫자를 모두 곱해서 더해주는 것이라고 이해할 수 있겠습니다.
다시 본론으로 돌아와서 이 이미지 입력값 matrix의 각 부분과 연산처리가 어떻게 되는지 그림으로 살펴보겠습니다.
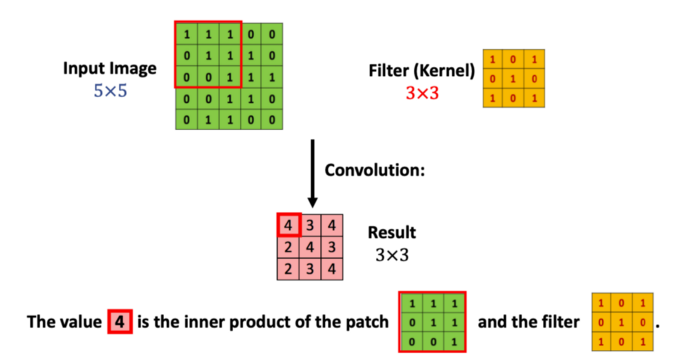
우선 빨간 테두리 부분의 matrix와 필터의 Inner Product 연산을 해주면 그 결과값은 4가 됩니다. 그리고 필터를 한칸 옆으로 옮겨주면,
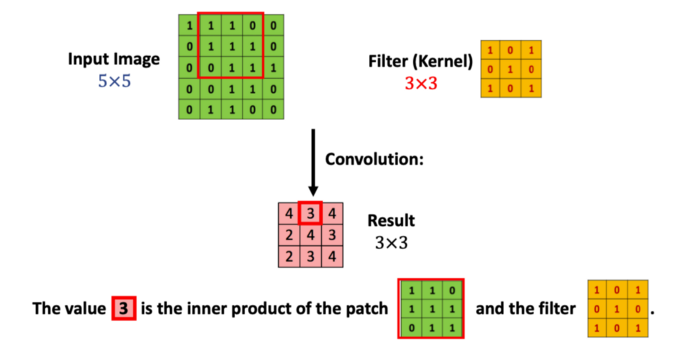
이번엔 빨간 테두리 부분의 matrix의 필터의 연산처리를 해주어 결과값 3을 얻어냅니다. 이러한 과정을 전체 이미지 matrix에 필터 matrix를 조금씩 움직이며 반복해줍니다. 그렇게 반복하여 얻어낸 결과값이 분홍색으로 표시된 matrix입니다.
자세히 보면 결과값의 크기(여기서는 matrix의 dimension을 의미)는 3x3이라는 것을 파악할 수 있습니다. 5x5로 구성된 칸에 3x3 크기의 불록을 움직였고 이는 너비와 높이를 총 3번씩 놓을 수 있었기에 나온 결과였습니다. 이를 수학적으로 표현해보면 다음과 같습니다.
입력값: d_1 x d_2
필터: k_1 x k_2
결과값: (d_1 - k_1 + 1) x (d_2 - k_2 + 1)
2.2 Zero Padding
방금 우리가 살펴본 Convolution 처리를 보면 5x5의 크기의 이미지에 필터처리를 해주었더니 결과값의 크기가 3x3으로 줄어들었다는 것을 알 수 있습니다. 즉 손실되는 부분이 발생한다는 뜻입니다. 이러한 문제점을 해결하기 위해 Padding이라는 방법을 사용할 수 있습니다. 쉽게 말해 0으로 구성된 테두리를 이미지 가장자리에 감싸 준다고 생각할 수 있습니다.
그렇다면 위의 경우 5x5 크기의 이미지 입력값이 7x7 크기 (d_1 + 2) x (d_2 + 2) 이 될 것입니다. 이 상태에서 3x3 필터를 적용해줄 경우 똑같이 5x5의 결과값을 얻을 수 있습니다. 이렇게 되면 입력값의 크기와 결과 값의 크기가 같아짐. 즉 손실이 없어졌음을 의미하게 됩니다.
2.3 Stride
Stride는 쉽게 말해 필터를 얼마만큼 움직여주는 가에 대한 것입니다. Stride 값이 1인 경우 필터를 한 칸씩 움직여주게 됩니다. 참고로 stride-1이 기본값이고 stride는 1보다 큰 값이 될 수도 있습니다. stride 값이 커질 경우 필터가 이미지를 건너뛰는 칸이 커짐을 의미하므로 결과값 이미지의 크기는 작아짐을 의미합니다. stride 값을 적용한 수학적 표현을 다음과 같습니다.
입력값: d_1 x d_2
필터: k_1 x k_2
stride: 1
결과값: (((d_1 - k_1) / s) + 1) x (((d_2 - k_2) / 2) + 1)
2.4 The Order-3 Tensor
지금까지 우리는 2차원 이미지의 입력값을 살펴보았습니다. 물론 입력값이 3차원인 경우도 존재합니다. 예를 들어 컬러이미지는 R, G, B의 세가지 채널로 구성되어 있기 때문에 d_1 x d_2 x 3과 같은 삼차원의 크기를 같습니다. 이러한 모양을 order-3 텐서라고 부릅니다. 유사하게 익숙한 2차원의 이미지는 order-2 텐서 (matrix)라고도 칭합니다.
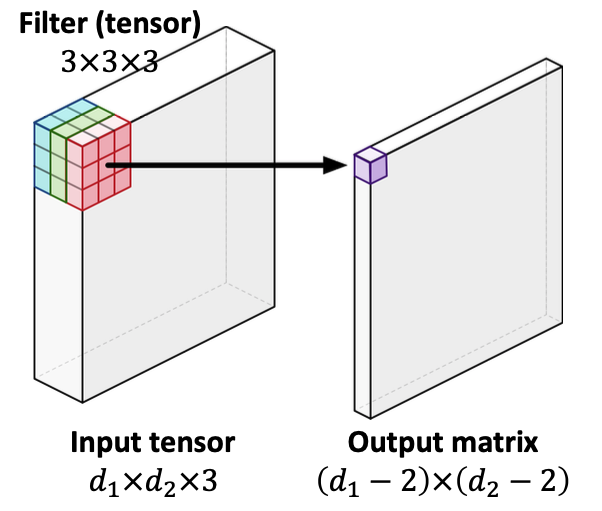
위의 이미지와 같이 이 경우 필터는 k1xk2x3의 크기를 가진 order-3 텐서가 됩니다. 연산처리는 똑같이 Inner Product를 사용하며 결과값의 모양은 matrix가 됩니다.
3. CNN의 전체적인 네트워크 구조
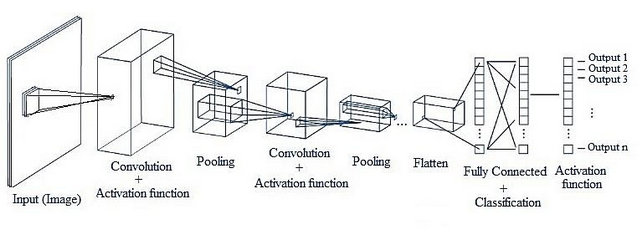
CNN의 구조는 기존의 완전연결계층(Fully-Connected Layer)와는 다르게 구성되어 있습니다. 완전연결계층(또는 Dense Layer)에서는 이전 계층의 모든 뉴런과 결합되어 있는 Affine 계층으로 구현했지만, CNN은 Convolution Layer와 Pooling Layer들을 활성화 함수 앞뒤에 배치하여 만들어집니다.
3.1. 첫번째 Convolutional Layer
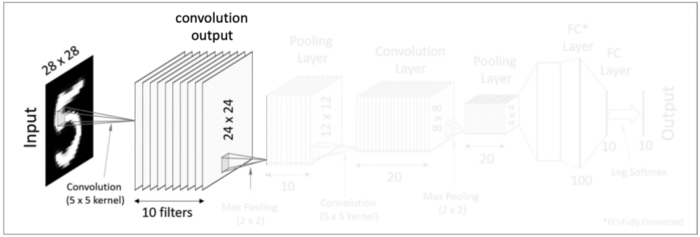
우리에게 주어진 값은 28x28의 크기를 가진 이미지입니다. 이 이미지를 대상으로 여러 개의 필터(커널)을 사용하여 결과값(feature mapping)을 얻습니다. 즉 한 개의 28x28 이미지 입력값에 10개의 5x5 필터를 사용하여 10의 24x24 matrics 즉 convolution 결과값을 만들어 냈습니다.
그 후 이렇게 도출된 결과값에 Activation function (ReLU 함수와 같은)을 적용합니다. 이렇게 첫번째 Convolutional Layer가 완성되었습니다. 우리는 여기서 한 Convolution Layer가 Convolution 처리와 Activation function으로 구성되어 있다는 것을 알 수 있습니다.
활성 함수(Activation function)을 왜 사용할까?
간단히 말하자면 선형함수인 convolution에 비선형성(nonlinearity)를 추가하기 위해 사용합니다. 보다 자세한 내용은 아래 링크를 참고하면 좋을 듯 합니다.
What, Why and Which?? Activation Functions
While studying neural network, we often come across the term — “Activation functions”. What are these activation functions?
medium.com
3.2. 첫번째 Pooling Layer
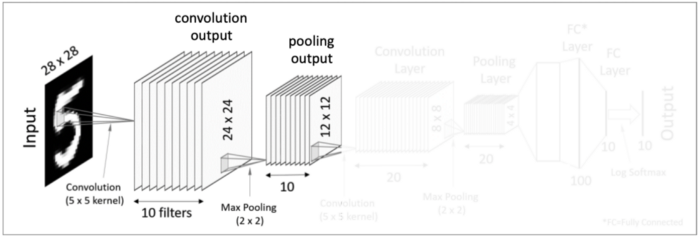
그 다음은 Pooling Layer 입니다. 우선 Pooling이라는 개념이 무엇인지부터 짚고 넘어가고자 합니다.
이 전 단계에서 convolution 과정을 통해 많은 수의 결과 값들을 생성했었습니다. 하지만 위와 같이 한 개의 이미지에서 10개의 이미지 결과값이 도출되어버리면 값이 너무 많아졌다는 것이 문제가 됩니다. 때문에 고안된 방법이 Pooling이라는 과정입니다. Pooling은 각 결과값(feature map)의 dimentionality를 축소하는 것을 주요한 목적으로 둡니다. 즉 correlation이 낮은 부분을 제거하여 각 결과 값의 크기(dimension)를 줄이는 과정입니다.
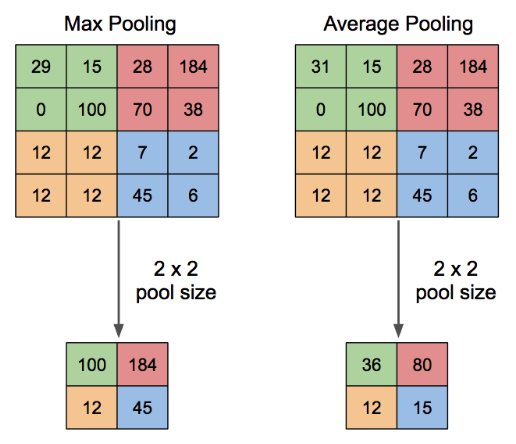
Pooling은 그림에서 볼 수 있듯 대표적인 두 가지 방법이 존재합니다. 먼저 이미지에서 볼 수 있는 Pooling은 Pool의 크기가 2x2인 경우 2x2인 matrix에서 가장 큰 값(max)나 평균값(average)를 가져와 결과값의 크기를 반으로 줄여주게 됩니다. 이때 적용하는 Pooling 단위가 무엇인지에 따라 Max Pooling과 Average Pooling으로 분류가 됩니다.
다시 본론으로 돌아와서 그 위의 전체 네트워크 이미지로 돌아가면 Pooling을 거쳐 결과 값(feature map)이 10개의 12x12 matrices가 된 것을 확인할 수 있습니다.
3.3 두번째 Convolution Layer
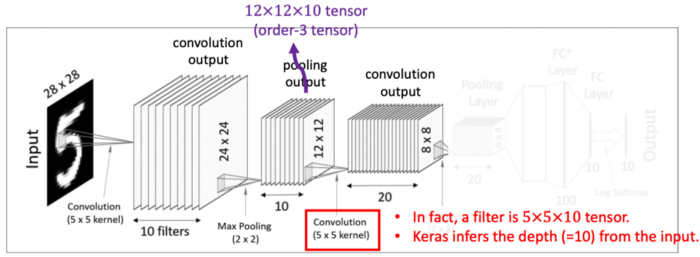
이번 Convolution Layer에서는 텐서 convolution을 적용합니다. 이전의 Pooling layer에서 얻어낸 12x12x10 텐서(order-3 tensor)를 대상으로 5x5x10 크기의 텐서필터 20개를 사용해줍니다. 그렇게 되면 8x8 크기를 가진 결과값 20개를 얻어낼 수 있습니다.
3.4 두번째 Pooling Layer
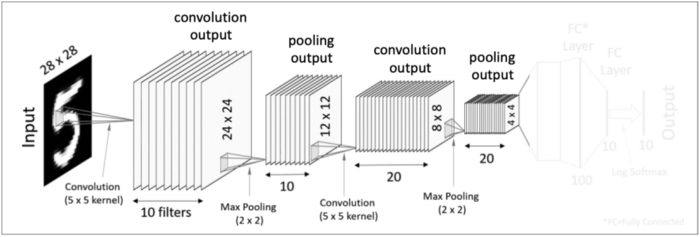
두번째 Pooling Layer입니다. 전과 똑같은 방식으로 Pooling 과정을 처리해주면 크기가 더 작아진 20 개의 4x4의 결과 값을 얻습니다.
3.5 Flatten (Vectorization)
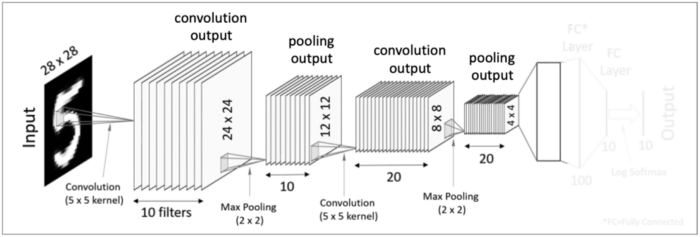
그 이후 이 4x4x20의 텐서를 일자 형태의 데이터로 쭉 펼쳐주게 됩니다. 이 과정을 Flatten 또는 Vectorization이라고 하는데 쉽게 말해 세로줄을 일렬로 쭉 세워두는 것을 의미합니다. 그러면 이것은 320-dimension을 가진 벡터 형태가 됩니다.
그렇다면 왜 이렇게 1차원 데이터로 변형해도 상관이 없을까요? 이 전에 두번째 pooling layer에서 얻어낸 4x4 크기의 이미지들은 이미지 자체라기 보다는 입력된 이미지에서 얻어온 특이점 데이터라고 볼 수 있으며, 여기서 1차원 벡터 데이터로 변환하는 것이 이제 더이상 spatial하거나 topolological한 특성의 소거를 의미하지 않게 됩니다.
3.6. Fully-Connected Layers(Dense Layers)
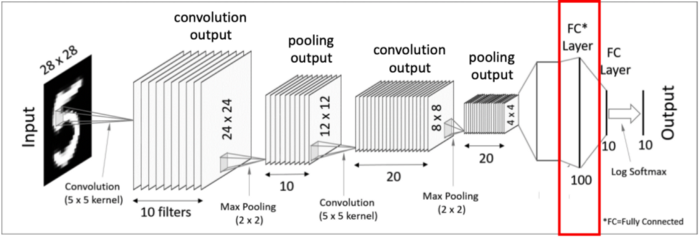
이제 마지막으로 하나 혹은 하나 이상의 Fully-Connected Layer를 적용시키고 마지막에 Softmax activation function을 적용해주면 드디어 최종 결과물을 출력하게 됩니다.
4. 매개변수(Parameter)와 하이퍼 매개변수(Hyper-parameter)
우선 Parameter와 Hyper-parameter, 용어 정리부터 해보도록 하겠습니다.
모델 매개변수(parameter)는 모델 내부에 있으며 데이터로부터 값이 추정될 수 있는 설정 변수(configuration variable)입니다. 모델 하이퍼파라미터(hyper-parameter)는 모델 외부에 있으며 데이터로부터 값이 추정될 수 없는 설정변수 입니다.
딥러닝의 기본은 파라미터들을 최적의 값으로 빠르고 정확하게 수렴하는 것을 목적으로 합니다. 때문에 어떻게 모델의 파라미터들을 최적화시키냐 하는 것이 모델 트레이닝의 중요한 포인트입니다.
모델을 학습시킬때 좋은 하이퍼파라미터를 찾는 것 또한 중요합니다. 이를 찾는 과정을 하이퍼 파라미터 튜닝이라고 합니다.
4.1 .학습 가능한 매개변수의 수
앞서 살펴본 CNN 모델의 학습 가능한 매개변수(trainable parameter)는 몇개나 되는지 살펴봅시다.
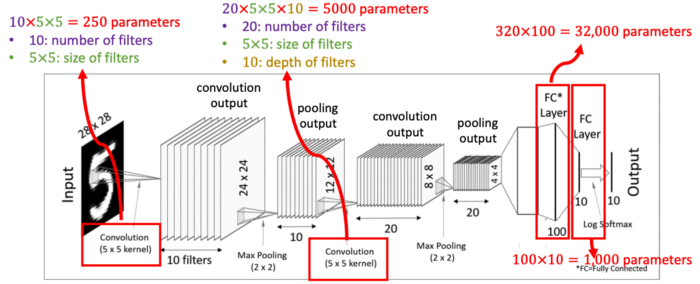
- 첫 convolution 과정에서 5x5 크기의 필터 10개를 사용하였으므로 250개의 매개변수가 존재합니다.
- Pooling Layer에서는 단순히 크기를 줄이는 개념이므로 매개변수가 없습니다.
- 두 번째 convolution 과정에서 5x5x10 크기의 텐서 20개를 사용했으므로 5000개의 매개변수가 추가되었습니다.
- 두 개의 fully-connected layer들에서 각각 매개변수 32,000개와 1000개가 추가되었습니다.
결과적으로 생략한 intercept 값까지 고려해보면 총 38,250 개 이상의 학습 가능한 매개변수를 갖게 됩니다.
4.2. 초매개변수 (Hyper-parameter)
마지막으로 CNN모델에서 튜닝 가능한 하이퍼파라미터는 어떤 것들이 있는지 간단히 살펴보겠습니다.
- Convolutional layers: 필터의 갯수, 필터의 크기, stride값, zero-padding의 유무
- Pooling layers: Pooling방식 선택(MaxPool or AvgPool), Pool의 크기, Pool stride 값(overlapping)
- Fully-connected layers: 넓이(width)
- 활성함수(Activation function): ReLU(가장 주로 사용되는 함수), SoftMax(multi class classification), Sigmoid(binary classification)
- Loss function: Cross-entropy for classification, L1 or L2 for regression
- 최적화(Optimization) 알고리즘과 이것에 대한 hyperparameter(보통 learning rate): SGD(Stochastic gradient descent), SGD with momentum, AdaGrad, RMSprop
- Random initialization: Gaussian or uniform, Scaling
여기서 간단히 알고 넘어가야 할것은 CNN을 학습시킬때 다뤄야 할 hyper-parameter가 이렇게나 많다는 것입니다.
'AI' 카테고리의 다른 글
| 신경망에서 학습을 시킨다는 의미 (1) | 2022.12.08 |
|---|---|
| CNN 가벼운 정리 (1) | 2022.12.08 |