



💡 이번 글에서는 DAG가 어떻게 구성되어 있는지를 중점으로 기본적인 Airflow의 사용방법을 소개합니다.
데이터 셋
본격적으로 실습에 들어가기 앞서 이번 실습에 사용할 데이터 셋을 소개합니다.
하단의 링크에서는 우주와 관련된 다양한 데이터를 오픈 API 형태로 제공합니다. 하루 요청 제한(시간 당 15 call) 하에서 누구나 사용가능하며 로켓의 발사, 엔진의 테스트, 우주 비행사의 기록 등과 같은 신기한 정보들을 쉽게 제공합니다.
https://thespacedevs.com/llapi
TheSpaceDevs - Home
A group of space enthusiast developers working on services to improve accessibility of spaceflight information.
thespacedevs.com

아래의 링크는 해당 API에 대한 문서인데요. 다양한 REST API 리소스를 제공하니 한번 살펴보시고 원하는 데이터를 살펴보시면 좋을 것 같습니다. 해당 글에서는 발사가 임박한 로켓의 정보를 활용하고자 합니다. 다음의 URL을 통해서 기본적인 요청을 수행하며 테스트를 먼저 진행해보겠습니다.
$ curl -L "https://ll.thespacedevs.com/2.2.0/launch/upcoming"
{
"count": 299,
"next": "https://ll.thespacedevs.com/2.2.0/launch/upcoming/?limit=10&offset=10",
"previous": null,
"results": [
{
"id": "5d3e11d7-5d13-4c8c-b94a-c73da97c39a5",
"url": "https://ll.thespacedevs.com/2.2.0/launch/5d3e11d7-5d13-4c8c-b94a-c73da97c39a5/",
"slug": "falcon-9-block-5-starlink-group-5-13",
"name": "Falcon 9 Block 5 | Starlink Group 5-13",
"status": {
"id": 3,
"name": "Launch Successful",
"abbrev": "Success",
"description": "The launch vehicle successfully inserted its payload(s) into the target orbit(s)."
},
...
"webcast_live": false,
"image": "https://spacelaunchnow-prod-east.nyc3.digitaloceanspaces.com/media/launch_images/falcon2520925_image_20230522091938.png",
...
JSON을 살펴보시면 로켓의 ID와 이름, 이미지 URL을 통해 로켓 발사 정보가 주어집니다.
REST API 콜 관련해서 파라미터가 궁금하시다면 아래 문서를 확인해보시길 바랍니다.
https://github.com/TheSpaceDevs/Tutorials/blob/main/faqs/faq_LL2.md
참고) "next": "https://ll.thespacedevs.com/2.2.0/launch/upcoming/?limit=10&offset=10" 처럼 filter를 통해 paginate가 가능합니다. 명시하지 않았다면 기본적으로 첫 페이지에서부터 10개의 로켓 정보를 가져옵니다. limit=<number>를 늘려주면 최대 100개의 로켓 정보까지 가져올 수 있으며, offset=<number>를 통해 pagination이 가능하다고 하니 참고하시기 바랍니다.
사실 위의 curl을 수행해보셨다면 의문이 드실 수 있습니다. “저렇게 간단하게 데이터를 뽑을 수 있다면 bash script를 사용해서 가져오면 될 껄 굳이 Airflow까지 써야하나 …” (넵 바로 제가 들었던 첫 번째 의문입니다.)
물론 Bash 스크립트 형태만으로 데이터를 가져와도 좋겠지만, 가장 먼저 발생할 문제는 이전 글에 명시하였던 Incremental update시에 발생하는 문제에 대해 능동적인 대처가 어렵다는 점일 것이다. 주기적으로 실행하는 추출 작업이 어느날 갑자기 문제가 생겼는데 중간에 문제가 된 부분만을 다시 추출해야한다면? 기존 스크립트의 추출로는 절대 쉽지 않다.
Airflow는 태스크를 DAG 형태로 제공하며 파이프라인을 세분화합니다. 문제가 발생한 태스크가 보다 명확해집니다. 또한 이를 시각적으로 확인까지 가능합니다. 또한 태스크 형태로 제공하다보니 의존성이 없다면 병렬화까지도 훨씬 용이해질 것입니다.
물론 Airflow가 무조건 옳을 수는 없겠습니다. 위에서 휘황찬란하게 서술했지만 현업에서 사용하게 되면 Airflow만큼 데이터 엔지니어를 괴롭히는 서비스도 없다고 합니다. 그럼에도 불구하고 Airflow는 기존 방식에 비해서는 확실한 개선이라고 말할 수 있겠습니다.
혹여 CeleryExecutor를 활용하신다면…
Airflow가 CeleryExecutor를 사용하고 있다면 저장되는 위치가 호스트 머신이 아니라 Airflow의 컨테이너들이 공유하는 볼륨이이기에 확인이 참 어렵습니다. 예를 들어 특정 컨테이너 (Airflow-trigger-1)에서 폴더를 만들어도 이는 개별 컨테이너의 변경 사항일 뿐이며 전체 Airflow 클러스터에는 반영이 되지 않습니다. 예를 들어 분명 데이터를 API에서 받아서 /tmp에 저장을 했지만, 도무지 확인할 방법이 없습니다. 특정 컨테이너의 터미널에 접근하여 ls를 수행해볼 수는 있겠지만, CeleryExecutor에서 사용하는 볼륨은 특정 컨테이너에 종속되는 볼륨이 아니기에 분명 Web UI에서는 파이프라인이 성공적으로 실행되었지만 아무리 찾아봐도 데이터를 찾을 수가 없습니다.
우리가 DAG를 작성하며 “/tmp/data”라는 경로에 데이터를 저장하고 싶다면 특정 컨테이너에 접근하여 “/tmp/data”라는 폴더를 만드는게 일반적인 리눅스 파일시스템의 접근이지만 CeleryExecutor는 컨테이너 환경 하에서 분산 처리라는 특수한 상황을 가정하기에 접근이 조금 달라야만 합니다.
가장 간단한 해결을 데이터를 저장하고자 하는 호스트 파일시스템의 경로를 Airflow 클러스터에서 사용하는 볼륨에 마운트시켜주는 것입니다. 혹여 Docker-compose로 빌드를 진행하신 상황에서 CeleryExecutor를 사용하고 있는 환경을 사용 중이신 경우, airflow 컨테이너들이 공유하는 x-airflow-common라는 Placeholder 아래의 volume이라는 필드를 통해 호스트 볼륨을 airflow 클러스터에 마운트할 수 있습니다.
version: '3.8'
x-airflow-common:
&airflow-common
# In order to add custom dependencies or upgrade provider packages you can use your extended image.
# Comment the image line, place your Dockerfile in the directory where you placed the docker-compose.yaml
# and uncomment the "build" line below, Then run `docker-compose build` to build the images.
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.6.2}
...
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins
- /mnt/c/Users/admin/data/:/data/ # 여기!
별 다른 점은 없고, 직전의 정의에서 가장 아래줄의 형태로 호스트 볼륨을 airflow-common 내부의 볼륨에 마운트해주시면 됩니다. 제 경우에는 윈도우 환경의 wsl 파일 시스템을 사용하고 있으니, 혹여 다른 설정이 필요하신 분들께서는 호스트 파일시스템의 권한만 잘 확인해주신 후 마운트해주신다면 이후 문제 없으시리라 생각합니다.
Docker-compose.yaml을 찾고 계신분이 있다면 다음 사이트를 참고해보세요.
https://airflow.apache.org/docs/apache-airflow/2.6.2/docker-compose.yaml
Airflow에서 공식적으로 제공하는 yaml 파일입니다. 다른 것은 없고 볼륨 쪽에서 마운트 부분의 경우에는 기본 정의에는 없는 사항이니 상황에 맞게 추가해주시면 됩니다. (부디 제 설명이 직관적으로 잘 전달되었길 …!)
DAG 작성
본격적으로 Airflow를 통해 로켓 발사 데이터셋에 대한 파이프라인을 구성해보겠습니다.
파이프라인의 목표는 최대한 간단하게 설정해보겠습니다. 바로 로켓의 이미지를 제 호스트 컴퓨터에 저장하는 것입니다.
본격적으로 작성하기 앞서 제 환경을 다시 한번 설명드리면
1. 저는 Airflow를 Docker compose를 통해 컨테이너 환경에서 실행 중에 있습니다.
2. 저는 Docker를 Window 10의 wsl 환경 아래에서 실행 중에 있습니다.
3. 제 Airflow 클러스터는 CeleryExecutor를 기반으로 실행되고 있으며, 별도의 볼륨 마운트를 통해 호스트의 경로와 Airflow 클러스터 내부의 경로를 마운트해놓은 상황입니다.
앞서 API 호출을 수행한 결과를 바탕으로 Image 필드의 정보를 바탕으로 데이터를 호스트 머신에 저장해보겠습니다.
앞서 설명하였듯, DAG는 여러 태스크로 구성되며 여느 아키텍처가 그렇듯 태스크를 어떻게 쪼개는 것이 정답인지는 대부분 명확하지 않습니다. 다양한 DAG 작성 경험을 통해 각 시나리오 상에서 발생할 수 있는 장단점을 익혀가면 OK라고 생각합니다.
해당 글에서는 세 태스크로 나뉜 DAG를 작성하고자 합니다.
Task 1: curl 을 통해 로켓 API를 통해 데이터를 가져와 내부에 저장합니다.
본격적으로 각 태스크들을 작성하기에 앞서서 DAG를 정의해줍니다. 앞으로 정의할 태스크들은 해당 DAG에 속할 예정입니다.
dag = DAG(
dag_id="download_rocket_launches", # DAG 구분자
start_date=airflow.utils.dates.days_ago(14), # DAG의 처음 실행 시작 날짜
schedule_interval=None, # DAG 실행주기
)
BashOperator를 통해 앞서 수행했던 curl 명령어를 별도의 태스크를 통해 구성합니다. Operator는 태스크를 사용하기 쉽도록 미리 구성된 템플릿이라고 생각해주시면 됩니다. (Operator 이야기를 하다보면 끝이 나지 않을 것 같아 추후 다른 글로 찾아오도록하겠습니다)
download_launches=BashOperator(
task_id="download_launches", # task 구분자
bash_command="curl -o /data/launches.json -L 'https://ll.thespacedevs.com/2.2.0/launch/upcoming'",
dag=dag, # 속하는 DAG
)
parameter 자체가 상당히 직관적이기 때문에 별도의 설명없이도 코드 내부의 주석을 통해서도 무리없이 이해하실 수 있으리라 생각합니다.
여기까지 태스크가 수행이 된다면 /data 경로 바로 아래에 launches.json이라는 파일이 생성되어야 합니다. 좀 더 아래쪽에서 파이프라인을 실행해보며 정말 생성이 된 건지 확인해보겠습니다.
Task 2: 내부 Image라는 필드를 통해 해당 URL에서 이미지를 다운받아 호스트에 저장합니다.
여기까지 왔다면 각 Image의 URL 정보를 가져올 수 있게 되었으니 실제 주소에 가서 이미지를 다운받아야겠죠. 앞선 작업과는 달리 JSON 필드에 접근하여 각 주소로부터 API 요청을 보내는 작업이 필요합니다. 작업이 조금 더 세밀하니 이번에는 파이썬 코드를 통해 태스크를 표현합니다.
def _get_pictures():
pathlib.Path("/data/images").mkdir(parents=True, exist_ok=True)
with open("/data/launches.json") as f:
launches=json.load(f)
image_urls=[launch["image"] for launch in launches["results"]]
for image_url in image_urls:
try:
response=requests.get(image_url)
image_filename=image_url.split("/")[-1]
target_file=f"/data/images/{image_filename}"
with open(target_file, "wb") as f:
f.write(response.content)
print(f"Downloaded {image_url} to {target_file}")
except requests_exceptions.MissingSchema:
print(f"{image_url} appears to be an invalid URL.")
except requests_exceptions.ConnectionError:
print(f"Could not connect to {image_url}.")
먼저 pathlib.Path는 해당 경로에 폴더가 존재하는 지를 확인하고 만약 해당 경로에 폴더가 없다면 mkdir을 수행하여 경로를 생성해줍니다.
pathlib.Path("/data/images").mkdir(parents=True, exist_ok=True)
그 다음에는 앞서 저장한 json 파일에 접근하여 데이터를 읽어옵니다. 이때 앞서 테스트 호출을 수행하면서 보셨듯 results의 하위 필드에 위치한 image 정보를 가져와야 합니다. 이미지의 이름의 경우에는 URL의 맨 마지막 부분을 잘라오며 정의합니다.
마지막에는 데이터를 저장해야겠죠. 데이터를 쓸때는 “wb (write binary)” 권한을 부여하는데 이는 현재 저장하고자 하는 데이터가 이미지(Non-text) 데이터이기에 Binary 형태로의 Write를 의미한다고 보시면 됩니다.
또 중요한 점은 Data Pipeline의 경우 에러 처리에 대해서 상당히 민감해야 한다는 점입니다. 해당 글에서는 간단히 try-catch를 사용하며 URL 구성이 이상하다던지, URL에 접근했는데 정작 이미지가 없다던지 등의 에러를 만났을 때 로그에 표시해줄 뿐입니다. 향후 에러 처리에 대해서도 별도의 글로 다뤄보도록 하겠습니다. (어째 써야할 글이 점점 늘어나는 것 같네요)
마지막으로 태스크의 동작 정의가 끝났다면, DAG에 등록해주며 마무리합니다. 직전의 BashOperator와 달리 파이썬 함수를 태스크로 옮기기 위해서는 PythonOperator를 사용합니다.
get_pictures=PythonOperator(
task_id="get_pictures",
python_callable=_get_pictures, # 등록할 Python 함수
dag=dag,
)
Task 3: 실제로 잘 저장되었는지 확인합니다.
이후에는 간단하게 데이터 저장 경로에 접근하여 몇 개의 파일이 저장되었는지를 확인합니다.
notify=BashOperator(
task_id="notify",
bash_command='echo "There are now $(ls /data/images | wc -l) images."',
dag=dag,
)
명령어는 중간의 파이프(’|’) 를 통해 ls의 결과를 wc에 넘기고 있습니다. 혹여 wc -l이 생소하시다면, wordcount -line이 줄여져있다고 기억하시면 바로 이해가 되실 것 같습니다.
여기까지 왔다면 DAG 내의 태스크 간의 실행 순서를 명시해줘야 합니다. 매우 직관적인 형태임을 확인하실 수 있습니다.
download_launches >> get_pictures >> notify
이렇게 정의한 DAG를 정리해보면 다음과 같습니다. 경로 쪽에서만 잘 신경써주시면 딱히 문제가 될 부분이 없는 코드입니다.
import json
import pathlib
import airflow
import requests
import requests.exceptions as requests_exceptions
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
dag = DAG(
dag_id="download_rocket_launches",
start_date=airflow.utils.dates.days_ago(14),
schedule_interval=None,
)
download_launches=BashOperator(
task_id="download_launches",
bash_command="curl -o /data/launches.json -L 'https://ll.thespacedevs.com/2.2.0/launch/upcoming'",
dag=dag,
)
def _get_pictures():
pathlib.Path("/data/images").mkdir(parents=True, exist_ok=True)
with open("/data/launches.json") as f:
launches=json.load(f)
image_urls=[launch["image"] for launch in launches["results"]]
for image_url in image_urls:
try:
response=requests.get(image_url)
image_filename=image_url.split("/")[-1]
target_file=f"/data/images/{image_filename}"
with open(target_file, "wb") as f:
f.write(response.content)
print(f"Downloaded {image_url} to {target_file}")
except requests_exceptions.MissingSchema:
print(f"{image_url} appears to be an invalid URL.")
except requests_exceptions.ConnectionError:
print(f"Could not connect to {image_url}.")
get_pictures=PythonOperator(
task_id="get_pictures",
python_callable=_get_pictures,
dag=dag,
)
notify=BashOperator(
task_id="notify",
bash_command='echo "There are now $(ls /data/images | wc -l) images."',
dag=dag,
)
download_launches >> get_pictures >> notify
DAG 실행
무사히 Docker compose를 통해 Airflow가 띄워졌다면, http://localhost:8080/home에서 Airflow의 Web UI에 접근할 수 있습니다.
참고로 Airflow 공식 문서에서 제공하는 정의의 경우 ID와 PW가 airflow로 동일합니다.
로그인에 성공하셨다면 DAGs라는 제목과 함께 DAG들의 목록을 확인하실 수 있습니다.

지금 제 환경에서는 위에서 정의한 DAG가 실행이 완료되어 있는 상태인데요. 아마 방금 실행을 하셨다면 아직 DAG를 제출하지 않았으므로 인식이 안되는게 맞습니다.
docker compose up을 해주셨던 저장소를 확인해보시면 dags라는 폴더가 생성되는 것을 확인할 수 있습니다. 이름에서 알 수 있듯 DAG를 제출하는 폴더이고 아래 그림처럼 파이썬 코드 형태로 DAG 정의를 제출해주시면 됩니다.

여기까지 DAG의 추가까지 완료되었다면 UI에서 실행해주시면 됩니다.
실행하는 방법은 여러가지인데, 일단 해당 DAG로 들어가서 우측 상단에 있는 시작 버튼을 눌러주겠습니다.

만약 실행해서 문제가 없다면 제 실행처럼 초록색으로 완료가 되어야 합니다.
혹여 문제가 생겼을 시 로그를 추적해볼 수 있을텐데, 각 테스크 실행에 대한 로그는 제 화면 기준 초록색의 긴 사각형 아래의 개별 태스크를 의미하는 정사각형들을 눌러주셔야 합니다. 빨간색으로 표시되거나 주황색으로 표시되어 정상 실행이 되지 않은 태스크를 눌러주시면 되겠습니다. (저는 정상 실행이기에 빨간색이나 주황색은 없습니다.)

그러면 Details, Graph 옆에 친절하게 Logs를 제공하는 페이지 링크가 존재합니다.
제 경우 문제 없이 실행되어 이러한 메세지를 받을 수 있었습니다.

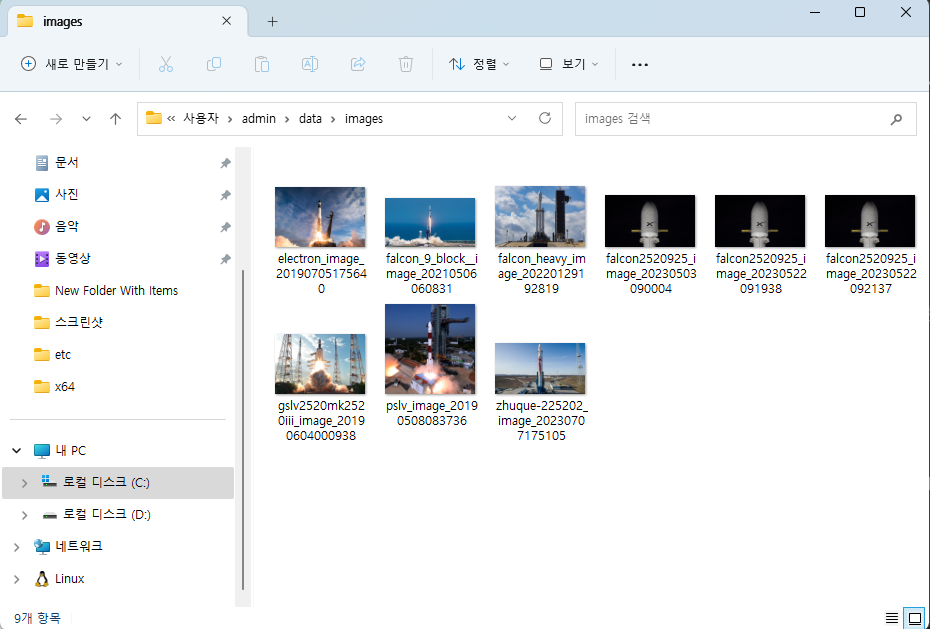
마지막으로 실제 호스트 PC의 경로에도 데이터가 저장된 것을 확인하였습니다.
마치며
저 또한 이제 막 Airflow를 공부하는 입장에서 거창한 형용사들로 글을 꾸며보았는데, 사실 그리 어려운 내용은 아닌지라 혹여 이해가 안되시는 부분이 있다면 제 글솜씨가 아쉬운 탓이라고 양해해주시면 감사하겠습니다 ㅠㅠ 아무쪼록 이해가 안되시는 부분이 있다면 최대한 제가 아는 선에서 도움드리겠습니다. 피드백도 환영합니다. 언제든 답글 주세요!
'Data Engineering > Airflow' 카테고리의 다른 글
| Airflow의 도입 배경 (0) | 2023.06.28 |
|---|---|
| Airflow의 DAG (0) | 2023.06.28 |

데이터 파이프라인을 구성하다보면 근거 없는 자신감이 들 때가 있다. 그럴싸한 아키텍처를 설계하고 나면 이러이러한 서비스를 뚝딱뚝딱 이어붙이면 문제 없이 동작하겠지라는 생각이 사실 매번 드는 것 같다. 그러나 어디까지나 이상이고 현실은 다르다. 데이터 파이프라인은 많은 이유로 실패한다. 문제 상황도 아주 제각각인데, 데이터의 소스가 매우 다양하기에 발생하는 문제들, 오픈소스 호환성 때문에 발생하는 문제들, 데이터 파이프라인들 간에 의존도에 대한 이해가 부족하기에 발생하는 문제들 등 수많은 문제가 그렇다. 특히나 데이터 소스 간에 의존성이 발생하기 시작한다면 더욱 문제는 복잡해진다. 예를 들어 마케팅 채널 정보의 업데이트가 안된다면 다른 모든 정보들의 업데이트가 이뤄지지 않는 상황에서는 마케팅 채널 정보와 다른 정보들 간의 의존 관계가 형성되게 된다. 문제를 따라가다보면 쌓여있던 문제들이 왜 이제 왔냐며 나를 기다려왔다는 듯이 반겨준다. 물론 나는 반갑지 않다.
Airflow 서비스의 본질적인 필요성을 이해하기 위해서는 Incremental Update 환경에서의 Backfill에서 발생하는 여러 문제 상황들을 이해해야 한다. Incremental update는 데이터 저장소에 데이터를 업데이트할 경우 모든 데이터를 처음부터 다시 쓰는 것이 아니라 새롭게 추가된 부분만을 뒤에 이어붙이는 방식이다. Incremental update의 반대되는 개념으로는 Full Refresh가 있다. 이는 매번 소스의 내용을 전부 읽어오는 방식이다.
Full Refresh와 Incremental update에는 각각의 장단점이 있다. 먼저, Full Refresh를 통해 데이터를 업데이트해나간다면 데이터를 처음부터 읽어오기 때문에 매우 비효율적이다. 특히나 데이터가 커질 수록 Full Refresh를 통해 매번 데이터를 처음부터 써야하는 것은 불가능에 가깝게 들린다. 반면 Incremental update는 daily나 hourly 주기로 추가할 데이터만 쓰므로 비교적 효율적이다. 여기까지만 본다면 Incremental update 방식에는 아무런 문제가 없다.
다만 Inremental update는 유지보수가 매우 어렵다. 만약 소스 데이터 상에 문제가 생기거나, 중복 데이터가 쌓이게 되면 이를 일일히 확인해가며 데이터를 정기적으로 정제해주는 추가작업이 불가피하다. Full Refresh의 경우 매번 소스의 내용을 전부 읽어오므로 중복의 문제에서는 자유롭다. 혹여 데이터를 가져오는데 있어 중간에 문제가 발생하더라도 다시 처음부터 데이터를 추가하면 되므로 그리 큰 문제가 아닐 것이다. 그럼에도 데이터 엔지니어는 Incremental update를 지향해야 한다. Full Refresh는 매우 안전한 방법이지만 데이터의 크기가 커지는 환경을 고려하지 않기 때문이다.
데이터가 작을 경우 가능하면 Full Refresh 방식의 데이터 업데이트를 진행한다. 만약 Incremental update만이 가능하다면 대상 데이터소스가 갖춰야할 필드의 조건이 몇가지 있다.
1. Created: 각 레코드가 처음 생성된 시점이 기록되어 있어야 한다. 이는 Incremental update에서 필수적이지는 않지만, 데이터의 수명 주기를 추적하거나 특정 시점 이후 생성된 레코드를 조회할 때 유용하다.
2. Modified: 각 레코드가 마지막에 수정된 시점을 나타낸다. 해당 필드가 있다면, 마지막 업데이트 이후 변경된 레코드만 선택하여 처리할 수 있다. 해당 필드를 통해 데이터 처리의 효율성을 높이고 불필요한 작업을 수행하지 않을 수 있다.
3. Deleted: 해당 필드는 레코드의 삭제 여부를 나타낸다. "Soft delete"라는 개념과 연관이 있는데, 이는 레코드를 데이터베이스에서 물리적으로 제거하는대신 레코드를 "Deleted"라고 표시함으로서 삭제하는 방법을 의미한다. 이렇게 하면, 삭제된 레코드와 그렇지 않은 레코드를 구분할 수 있으며 필요에 따라 레코드를 복구할 수도 있게 된다.
4. 만약 대상 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야 한다.
데이터 파이프라인이라면, Incremental update라면 특히나 문제가 발생할 여지가 많으며 데이터가 중복되거나 누락되었을때 Backfillng하는 것이 데이터 엔지니어의 주요한 책무이다. 다시 말해 멱등성(Idempotency)를 보장하는 것이 파이프라인 구축의 가장 중요한 문제이다. 이를 달성하기 위해서는 결국 다음 요소들이 요구된다.
1. 실패한 데이터 파이프라인을 재실행하는데 용이해야 한다.
2. 과거 데이터를 채우는 과정(Backfill)이 쉬워야 한다.
이러한 문제에서 보다 자유롭기 위해서 Airflow는 도입되었다.
먼저 Airflow는 Backfill이 용이하다. 앞서 설명하였듯 DAG로 구성된 태스크들을 시각적으로 쉽게 확인할 수 있다. DAG가 중간에 실패하였다면, 어떤 태스크에서 문제가 발생하였는지를 쉽게 대시보드 형태로 모니터링 할 수 있다. 즉 실패한 데이터 파이프라인의 재실행을 용이하게 만들어주자는 것이 Airflow의 의의이다.
스크립트 기반의 다음의 작업을 수행하는 파이프라인이 있다고 하자.
from datetime import datetime, timedelta
# 지금 시간 기준으로 어제 날짜를 계산
y = datetime.now() - timedelta(1)
yesterday = datetime.strftime(y, '%Y-%m-%d')
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
이는 매우 이상적인 파이프라인에서만 유효하다. 앞서 설명했듯 파이프라인은 문제가 발생할 수 밖에 없고 데이터 소스의 복잡성이 늘어날 수록, 운영 기간이 늘어날 수록 문제는 복잡해진다. 만약 올 초의 1월 1일 문제가 생겨서 해당 일자 정보에 대한 Backfill을 수행해야한다면 다음의 코드로 수행을 할 것이다.
간단해보이는 코드이지만, 만약 파이프라인이 많고 복잡해질 수록 이러한 형태의 관리는 실수의 가능성이 높을 수 밖에 없다. 특히 연도를 잘못 기입한 후 파이프라인을 실행해버리면 말그대로 대참사가 발생해버릴 수 있다.
from datetime import datetime, timedelta
# 코드를 직접 수정
yesterday = '2023-01-01'
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
Airflow의 DAG에서는 catchup 파라미터가 True이면서 start_date와 end_date가 적절하게 설정된 경우 손쉽게 Backfill이 가능하다. Airflow에서는 날짜 별로 Backfill의 결과를 기록하고 성공 여부를 기록한다. 이를 통해 이후에도 쉽게 결과를 확인할 수 있게 된다. 해당 성공과 실패의 날짜들은 시스템에서 ETL의 인자로 제공된다. 때문에 데이터 엔지니어는 데이터의 날짜를 계산하지 않고 시스템이 지정해준 날짜('execution_date')를 사용만 하면 된다.
from airflow.operators.python_operator import PythonOperator
def sample_task(**context):
# context로부터 실행 시점을 불러온다
execution_date = context['execution_date']
# 시스템에 의해 관리된 execution_date에 의해 어떤 데이터를 업데이트할지를 정할 수 있다.
...
task = PythonOperator(
task_id='sample_task',
python_callable=sample_task,
provide_context=True, # execution_date와 같은 context 변수를 넘길 때 필요하다.
dag=my_dag,
)
파이썬의 datetime등을 통해 업데이트 대상을 선택하는 것은 안티 패턴이다. 대신 Airflow에서 지원하는 execution_date를 활용하여 레코드가 업데이트되는 날짜 혹은 시간을 알아낼 수 있도록 코드를 작성해야 한다.
물론 이 경우에도 수많은 하위 문제들이 발생한다.
때문에 아무리 Airflow를 사용한다고 하더라도 데이터 파이프라인의 입력과 출력을 명확히 하고 이를 문서화하는 것이 중요하다. 특히 테이블이 늘어나고 데이터가 복잡해지는 경우 분석팀에서 데이터를 찾아내는 데 어려움을 겪을 수 있다. 소위 데이터 디스커버리 문제라고도 불리는데, 분석을 하고 싶어도 방대한 데이터에 압도되어 어디서부터 시작해야할지 모르는 경우가 종종 발생한다. 이때 잘 정리된 문서는 큰 도움이 된다.
또한 주기적으로 쓸모없는 데이터를 삭제하는 과정은 불가피하다. 아무리 잘 만든 파이프라인이라도 관리가 필요하다. 예를 들어 주기적으로 사용하지 않는 테이블과 파이프라인을 삭제한다거나 필수적으로 빠른 접근이 요구되는 데이터만을 DW(Hot storage)에 남기고 그렇지 않은 데이터를 DL(Cold Storage)에 옮기는 일은 인간의 개입이 필요할 가능성이 높다. 물론 이조차도 자동화할 수 있겠으나 이는 자동화에 따른 위험성을 고려해야 한다.
그 외에도 데이터 파이프라인의 사고가 발생하면 사고 리포트를 작성하여 이후의 비슷한 사고가 발생하였을 때 이를 방지하도록 한다거나 중요한 데이터 파이프라인의 경우에는 입력과 출력 데이터의 체크가 필요할 것이다. 간단하게는 입력 레코드의 수와 출력 레코드의 수를 체크하는 것에서부터 중복 레코드 체크를 수행한다거나 Summary 테이블을 만들고 PK가 존재한다면 정말로 PK의 Uniqueness가 보장이 되는지를 체크하는 것이 필요하다(Big query 같은 빅데이터 스토리지에서는 PK의 유일성이 보장되지 않는 것이 일반적).
'Data Engineering > Airflow' 카테고리의 다른 글
| DAG 작성 (0) | 2023.07.09 |
|---|---|
| Airflow의 DAG (0) | 2023.06.28 |
DAG (Directed, Acyclic Graph)
DAG는 파이프라인을 실행하기 위한 단순한 알고리즘을 제공해준다는 의의를 가진다.
아래의 날씨 대시보드 파이프라인에서는 방향성 그래프 표현을 통해 전체 파이프라인을 직관적으로 표현하고 있다.

이때 DAG를 구성하는 파이프라인 요소 각각은 Node라는 이름 대신 태스크라고 불리게 되며, 보다 직관적인 의존관계 파악이 가능해진다.
DAG의 또 다른 특징은 Cycle이 존재하지 않는다는 점이다.
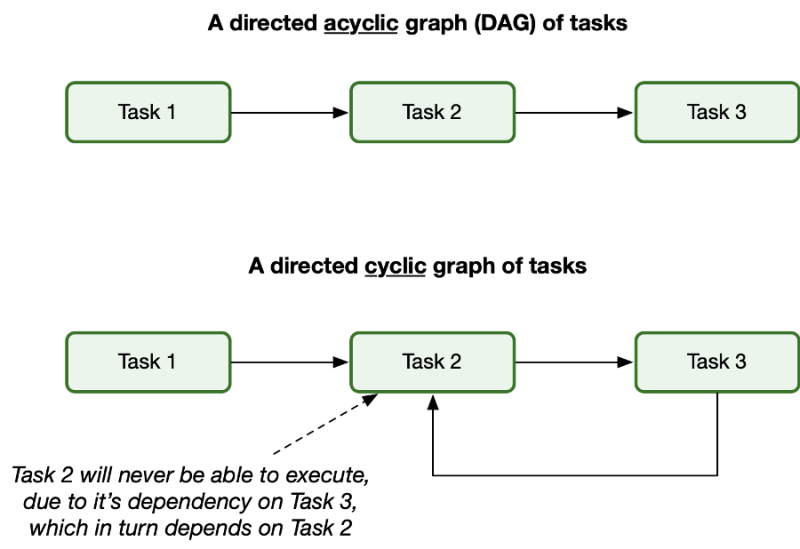
위의 그림에서 볼 수 있 듯 두 개의 태스크 간에 Cyclic 한 의존 관계가 생기는 순간 해당 DAG는 끝까지 진행될 수 없다. 태스크 2를 실행하기 위해서는 태스크 3의 실행이 전제되어야 하지만, 태스크 3의 실행은 반대로 태스크 2의 실행을 전제한다.
때문에 태스크 2와 태스크 3가 실행될 수 없게 되고 마치 프로세스 Deadlock과 같은 상태에 머물게 된다.
DAG를 통한 파이프라인 그래프 실행
DAG는 파이프라인 실행을 위한 단순한 알고리즘을 제공한다.
그래프 내부의 각 태스크는 최초에 Open(미완료) 상태에 놓이게 되며, 태스크의 실행은 다음의 단계를 따른다.
1. 화살표의 끝점에 해당하는 태스크를 실행하며 다음 태스크를 실행하기 전에 이전 태스크가 완료되었는지를 먼저 확인한다.
2. 태스크가 완료되었다면 다음에 실행해야할 태스크를 대기열에 추가한다. 이때 완료된 태스크의 경우에는 완료 표시를 남기게 되고, 대기열에 있는 태스크는 실행된다.
3. 모든 태스크가 완료될 때까지 해당 단계가 반복되며, 모든 태스크가 완료되었다면 DAG의 실행이 비로소 종료되게 된다.

스크립트 기반 파이프라인과의 비교
DAG 대신 스크립트를 통해 파이프라인을 구성할 수도 있다. 간단한 파이프라인 작업의 경우에는 태스크들을 하나의 스크립트를 통해 표현해도 문제가 없지만 복잡한 설계가 요구되는 경우 DAG는 다음의 이점을 갖는다.
1. 태스크의 병렬적 수행이 가능해진다.
DAG에서는 의존관계가 보다 명확하다. 때문에 의존성이 존재하지 않는 태스크들에 대해서는 병렬적인 수행이 가능하다.

2. DAG는 파이프라인을 점진적인 태스크로 분리한다.
스크립트 기반 파이프라인은 마치 Monolith 구조의 아키텍처처럼 하나의 프로세스를 통해 모든 파이프라인이 표현된다. 때문에 중간에 실패하는 경우가 발생하면, 실패 지점이 어디인지와 상관없이 모든 작업을 처음부터 다시 수행해야한다.
DAG는 반대로 파이프라인을 마치 MSA 아키텍처처럼 점진적인 태스크로 분리한다. 때문에 중간에 실패한 지점에서부터 실행이 가능하며 이는 효율성 증가로 이어진다.
Backfill: 하나의 파이프라인에서 이미 지나쳐간 특정 기간을 기준으로 다시 파이프라인을 수행하는 것을 의미한다. 태스크가 몇일 동안 실패하거나 새롭게 만든 파이프라인을 이전 시점부터 실행하고 싶은 경우 사용된다. Backfilling은 데이터 파이프라인 운영에 있어 매우 중요한 주제이며 데이터 파이프라인의 실패로 인한 Backfill이야말로 데이터 엔지니어의 삶을 고단하게 만드는 원흉라고 볼 수 있다.
Airflow의 특징
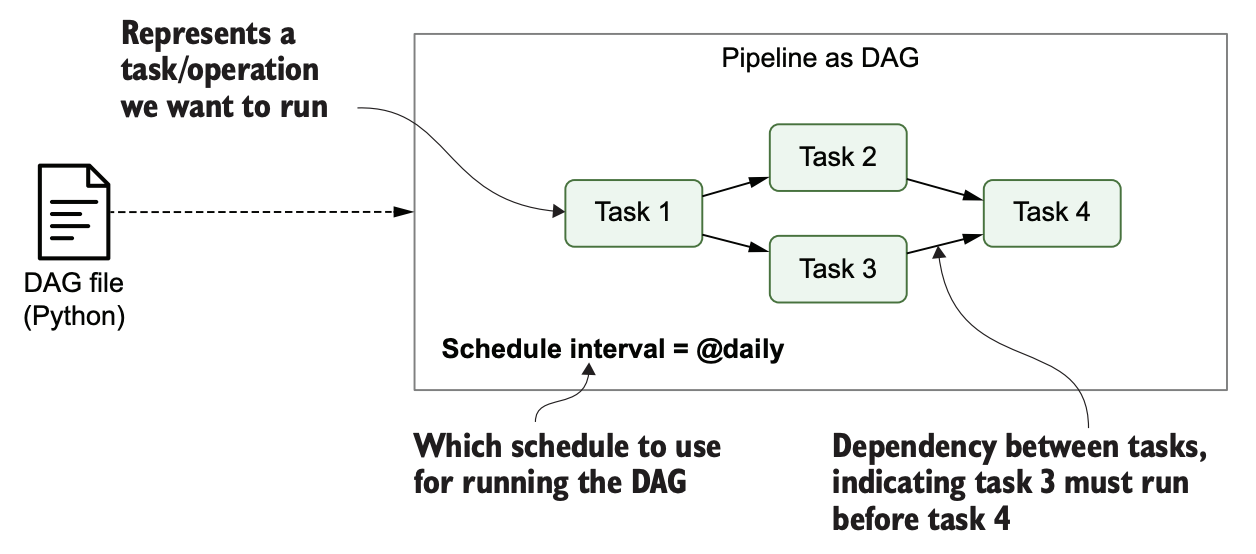
위의 그림에서는 파이썬 파일로 제출된 DAG의 특징을 보여준다. 유저는 파이썬 파일을 통해 태스크들의 의존 관계, DAG의 실행 주기 등을 쉽게 표현할 수 있다.
Airflow에서 파이썬 파일이 제출될 경우 일반적인 프로세스는 다음과 같다. 먼저 엔지니어가 DAG 파일을 파이썬의 형태로 Airflow에 제출한다. (자세한 구현은 이후의 글에서 소개한다) 제출이 완료되었다면 해당 파일을 Airflow에서는 파싱(serialize) 후 읽어들인다.
이후 각 DAG 내의 각 태스크는 스케쥴링을 거쳐 대기열(Queue)에 추가되고 대기열의 순서에 따라 Worker에서 실행된다. 해당 결과는 Airlow 내부의 데이터베이스로 이동하고, 유저는 데이터베이스에 기록된 DAG의 실행결과를 웹에서 대시보드 형태로 확인한다.

사용자가 DAG를 제출하면, 스케쥴러는 DAG 파일을 분석하여 각 DAG의 태스크, 의존성, 예약 주기를 확인한다.
마지막 DAG까지 확인을 했다면, 이제 DAG의 예약 주기를 확인해가며 해당 예약 주기가 이미 경과했는지 여부를 확인한다. 예약 주기가 경과하였다면 실행할 수 있도록 예약한다. 예약된 각 태스크에 대해 스케쥴러는 해당 태스크의 의존성(upstream task)을 확인한다. 만약 의존성이 있는 태스크를 실행하기 이전이라면 실행 대기열에 추가한다.
이후 Airflow의 워커 풀(worker pool)에서는 특정 태스크를 처리할 수 있는 워커 그룹을 정의하는 방식으로, 워커 풀에 속하는 워커들은 병렬적으로 태스크를 실행하게 된다. 이때 워커 풀은 태스크의 병렬 처리 가능성을 관리하며, 동시에 특정 태스크에 대한 동시 실행 제한을 관리한다. 주의할 점은 워커 풀이나 워커가 태스크를 선택하는 점은 아니라는 것이다. 워커는 실행의 주체일 수는 있으나 무엇이 실행될지, 즉 실행 순서에 대해서는 철저하게 스케쥴러의 책임이다.

워커 풀(worker pool)은 Airflow의 분산 환경을 구성하는 중요한 개념이다. 특히 Celery Executor는 여러 서버에 걸쳐 Airflow 작업을 분산시킬 수 있게 도와준다. 이런 환경에서 워커 풀은 여러 대의 서버에 분산되어 있는 워커들을 관리하는 데 사용된다. 워커 풀을 이용하게 되면 특정 풀에 속한 워커들에게만 작업을 할당한다거나, 각 풀에 할당된 동시 작업의 수를 제한하는 등의 작업의 제밀한 제어가 가능해진다.
'Data Engineering > Airflow' 카테고리의 다른 글
| DAG 작성 (0) | 2023.07.09 |
|---|---|
| Airflow의 도입 배경 (0) | 2023.06.28 |