
DAG (Directed, Acyclic Graph)
DAG는 파이프라인을 실행하기 위한 단순한 알고리즘을 제공해준다는 의의를 가진다.
아래의 날씨 대시보드 파이프라인에서는 방향성 그래프 표현을 통해 전체 파이프라인을 직관적으로 표현하고 있다.

이때 DAG를 구성하는 파이프라인 요소 각각은 Node라는 이름 대신 태스크라고 불리게 되며, 보다 직관적인 의존관계 파악이 가능해진다.
DAG의 또 다른 특징은 Cycle이 존재하지 않는다는 점이다.
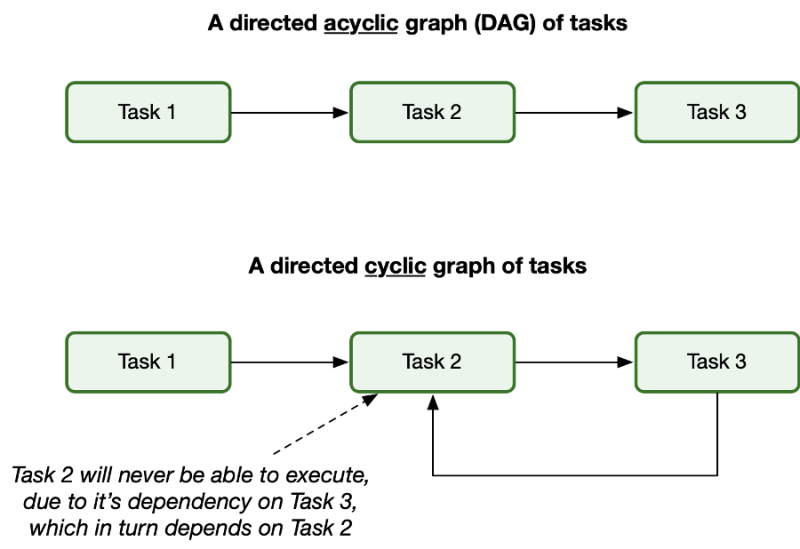
위의 그림에서 볼 수 있 듯 두 개의 태스크 간에 Cyclic 한 의존 관계가 생기는 순간 해당 DAG는 끝까지 진행될 수 없다. 태스크 2를 실행하기 위해서는 태스크 3의 실행이 전제되어야 하지만, 태스크 3의 실행은 반대로 태스크 2의 실행을 전제한다.
때문에 태스크 2와 태스크 3가 실행될 수 없게 되고 마치 프로세스 Deadlock과 같은 상태에 머물게 된다.
DAG를 통한 파이프라인 그래프 실행
DAG는 파이프라인 실행을 위한 단순한 알고리즘을 제공한다.
그래프 내부의 각 태스크는 최초에 Open(미완료) 상태에 놓이게 되며, 태스크의 실행은 다음의 단계를 따른다.
1. 화살표의 끝점에 해당하는 태스크를 실행하며 다음 태스크를 실행하기 전에 이전 태스크가 완료되었는지를 먼저 확인한다.
2. 태스크가 완료되었다면 다음에 실행해야할 태스크를 대기열에 추가한다. 이때 완료된 태스크의 경우에는 완료 표시를 남기게 되고, 대기열에 있는 태스크는 실행된다.
3. 모든 태스크가 완료될 때까지 해당 단계가 반복되며, 모든 태스크가 완료되었다면 DAG의 실행이 비로소 종료되게 된다.

스크립트 기반 파이프라인과의 비교
DAG 대신 스크립트를 통해 파이프라인을 구성할 수도 있다. 간단한 파이프라인 작업의 경우에는 태스크들을 하나의 스크립트를 통해 표현해도 문제가 없지만 복잡한 설계가 요구되는 경우 DAG는 다음의 이점을 갖는다.
1. 태스크의 병렬적 수행이 가능해진다.
DAG에서는 의존관계가 보다 명확하다. 때문에 의존성이 존재하지 않는 태스크들에 대해서는 병렬적인 수행이 가능하다.

2. DAG는 파이프라인을 점진적인 태스크로 분리한다.
스크립트 기반 파이프라인은 마치 Monolith 구조의 아키텍처처럼 하나의 프로세스를 통해 모든 파이프라인이 표현된다. 때문에 중간에 실패하는 경우가 발생하면, 실패 지점이 어디인지와 상관없이 모든 작업을 처음부터 다시 수행해야한다.
DAG는 반대로 파이프라인을 마치 MSA 아키텍처처럼 점진적인 태스크로 분리한다. 때문에 중간에 실패한 지점에서부터 실행이 가능하며 이는 효율성 증가로 이어진다.
Backfill: 하나의 파이프라인에서 이미 지나쳐간 특정 기간을 기준으로 다시 파이프라인을 수행하는 것을 의미한다. 태스크가 몇일 동안 실패하거나 새롭게 만든 파이프라인을 이전 시점부터 실행하고 싶은 경우 사용된다. Backfilling은 데이터 파이프라인 운영에 있어 매우 중요한 주제이며 데이터 파이프라인의 실패로 인한 Backfill이야말로 데이터 엔지니어의 삶을 고단하게 만드는 원흉라고 볼 수 있다.
Airflow의 특징
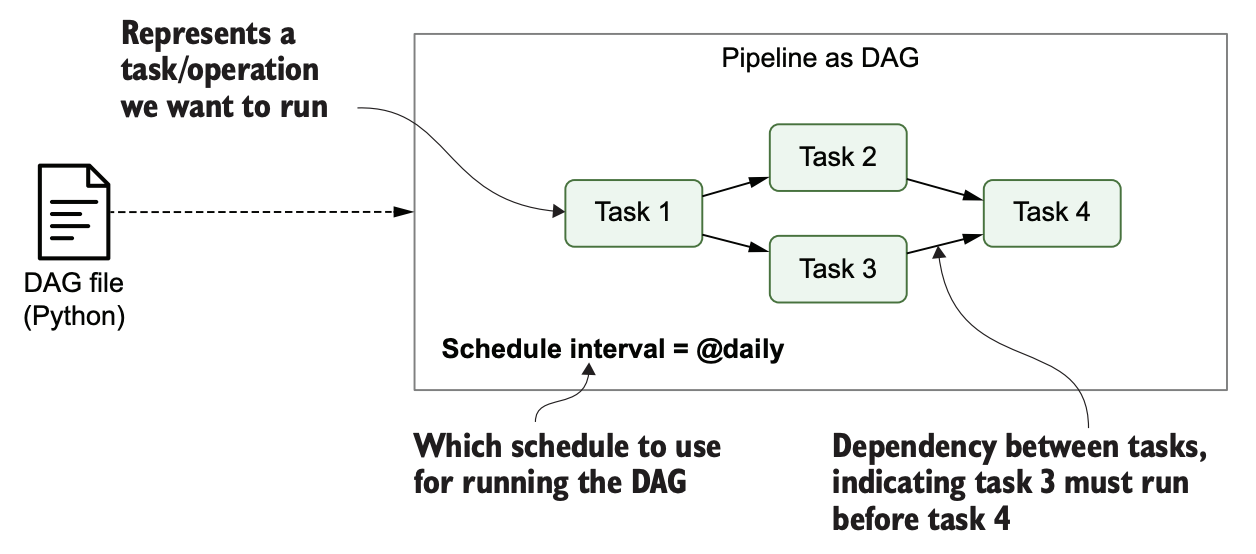
위의 그림에서는 파이썬 파일로 제출된 DAG의 특징을 보여준다. 유저는 파이썬 파일을 통해 태스크들의 의존 관계, DAG의 실행 주기 등을 쉽게 표현할 수 있다.
Airflow에서 파이썬 파일이 제출될 경우 일반적인 프로세스는 다음과 같다. 먼저 엔지니어가 DAG 파일을 파이썬의 형태로 Airflow에 제출한다. (자세한 구현은 이후의 글에서 소개한다) 제출이 완료되었다면 해당 파일을 Airflow에서는 파싱(serialize) 후 읽어들인다.
이후 각 DAG 내의 각 태스크는 스케쥴링을 거쳐 대기열(Queue)에 추가되고 대기열의 순서에 따라 Worker에서 실행된다. 해당 결과는 Airlow 내부의 데이터베이스로 이동하고, 유저는 데이터베이스에 기록된 DAG의 실행결과를 웹에서 대시보드 형태로 확인한다.

사용자가 DAG를 제출하면, 스케쥴러는 DAG 파일을 분석하여 각 DAG의 태스크, 의존성, 예약 주기를 확인한다.
마지막 DAG까지 확인을 했다면, 이제 DAG의 예약 주기를 확인해가며 해당 예약 주기가 이미 경과했는지 여부를 확인한다. 예약 주기가 경과하였다면 실행할 수 있도록 예약한다. 예약된 각 태스크에 대해 스케쥴러는 해당 태스크의 의존성(upstream task)을 확인한다. 만약 의존성이 있는 태스크를 실행하기 이전이라면 실행 대기열에 추가한다.
이후 Airflow의 워커 풀(worker pool)에서는 특정 태스크를 처리할 수 있는 워커 그룹을 정의하는 방식으로, 워커 풀에 속하는 워커들은 병렬적으로 태스크를 실행하게 된다. 이때 워커 풀은 태스크의 병렬 처리 가능성을 관리하며, 동시에 특정 태스크에 대한 동시 실행 제한을 관리한다. 주의할 점은 워커 풀이나 워커가 태스크를 선택하는 점은 아니라는 것이다. 워커는 실행의 주체일 수는 있으나 무엇이 실행될지, 즉 실행 순서에 대해서는 철저하게 스케쥴러의 책임이다.

워커 풀(worker pool)은 Airflow의 분산 환경을 구성하는 중요한 개념이다. 특히 Celery Executor는 여러 서버에 걸쳐 Airflow 작업을 분산시킬 수 있게 도와준다. 이런 환경에서 워커 풀은 여러 대의 서버에 분산되어 있는 워커들을 관리하는 데 사용된다. 워커 풀을 이용하게 되면 특정 풀에 속한 워커들에게만 작업을 할당한다거나, 각 풀에 할당된 동시 작업의 수를 제한하는 등의 작업의 제밀한 제어가 가능해진다.
'Data Engineering > Airflow' 카테고리의 다른 글
| DAG 작성 (0) | 2023.07.09 |
|---|---|
| Airflow의 도입 배경 (0) | 2023.06.28 |