






경쟁(Race)는 프로그램의 정확성이 다른 쓰레드가 포인트 y에 도달하기 전에 제어 흐름에서 한 쓰레드가 포인트 x에 도달하는 것에 의존할 때 발생한다.
예제를 사용하면 레이스의 본질을 이해하기 쉽다. 아래 코드에서는 4 개의 피어 쓰레드를 생성하고 고유한 정수 ID의 포인터를 각각의 쓰레드에 넘겨준다.
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#define N 4
void *thread(void *vargp);
int main()
{
pthread_t tid[N];
int i;
for (i = 0; i < N; i++) // Line 11
pthread_create(&tid[i], NULL, thread, &i); // Line 12
for (i = 0; i < N; i++)
pthread_join(tid[i], NULL);
exit(0);
}
/* Thread routine */
void *thread(void *vargp)
{
int myid = *((int *)vargp); // Line 21
printf("Hello, world! It's me, thread #%d!\n", myid);
return NULL;
}각 피어 쓰레드는 자신의 인자로 넘어온 ID를 지역 변수에 복사하고 자신의 ID에 포함하는 메세지를 인쇄한다. 매우 간단한 것처럼 보이지만, 이 프로그램은 다음과 같은 잘못된 결과를 얻게 된다.
unix> ./race
Hello, world! It's me, thread #1!
Hello, world! It's me, thread #3!
Hello, world! It's me, thread #2!
Hello, world! It's me, thread #3!문제는 각각의 피어 쓰레드와 메인 쓰레드 간의 경쟁 때문에 발생한다.
메인 쓰레드가 쓰레드를 만들 때, 로컬 스택 변수의 i 포인터를 전달한다. 이때, 레이스는 11번 줄에서의 다음 번 i의 증가와 21 번 줄에서 vargp의 역참조 및 할당 사이에서 발생한다. 만일 12 번 줄에서 메인 쓰레드가 실행되기 이전에 피어 쓰레드가 21번 줄을 실행한다면 myid 변수는 정확한 ID를 얻을 것이다. 그렇지 않다면 다른 쓰레드의 ID를 가져오게 된다. 즉, 피어 쓰레드가 얼마나 빨리 생성되느냐에 따라 전달되는 i 값이 변화한다.
이러한 버그는 커널이 쓰레드의 실행을 어떻게 스케쥴링하는지에 달렸다. 특정 시스템에서는 추적이 가능하지만 또 다른 시스템에서는 정상적으로 동작할 수도 있기에 레이스 문제는 까다롭다.
레이스를 제거하기 위해서는 공유 변수를 통해 상태를 전달하는 대신, 각 쓰레드마다 고유한 공간을 할당할 수 있다.
int main()
{
pthread_t tid[N];
int i *ptr;
for (i = 0; i < N; i++)
ptr = malloc(sizeof(int));
*ptr = i;
pthread_create(&tid[i], NULL, thread, ptr);
for (i = 0; i < N; i++)
pthread_join(tid[i], NULL);
exit(0);
}
/* Thread routine */
void *thread(void *vargp)
{
int myid = *((int *)vargp);
printf("Hello, world! It's me, thread #%d!\n", myid);
return NULL;
}이렇게 되면, 쓰레드의 실행 순서가 꼬이더라도 각자 고유한 ID를 갖게 되므로 앞서 제시한 레이스 문제를 해결할 수 있다.
'CS > OS' 카테고리의 다른 글
| 동기화 (3) Thread Safety (0) | 2022.12.07 |
|---|---|
| 동기화 (2) 세마포어 (0) | 2022.12.07 |
| 동기화 (1) (0) | 2022.12.07 |
| 쓰레드 (1) | 2022.12.07 |
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
쓰레드를 활용하여 프로그래밍을 수행할 때 쓰레드 안전성이라고 부르는 특성을 가지는 함수를 작성하도록 유의해야 한다. 어떤 함수는 다수의 동시성 쓰레드로부터 반복적으로 호출될 경우 항상 정확한 결과를 만드는 경우에만 Thread Safety 라고 부른다. 만일 어떤 함수가 이를 충족하지 못하는 상태라면 이를 Thread-unsafe 하다고 표현한다.
Thread-unsafe한 4가지 클래스를 정의하면 다음과 같다.
- 클래스 1: 공유 변수를 보호하지 않는 함수들. 직전 글에서 볼 수 있듯, 쓰레드 함수 내에서의 공유 변수 접근을 보호하지 못한다면 동기화 오류가 발생할 수 있다. 세마포어 연산 P와 V를 활용하여 Thread-safety한 쓰레드 함수로 개선할 수 있다.
unsigned int next = 1;
/* read - return pseudo-random integer on 0..32767 */
int rand(void)
{
next = next * 1103515245 + 12345;
return((unsigned)(next/65536) % 32768);
}
/* srand - set seed for rand() */
void srand(unsigned int seed)
{
next = seed;
}- 클래스 2: 다중 호출 사이에서 전역 변수로 상태를 유지하는 함수들. 위의 코드 상 의사 랜덤 숫자 생성기가 그 예시이다. rand 함수는 Thread-unsafe 인데, 그 이유는 현재 호출의 결과가 이전 반복 실행으로부터의 중간 결과에 의존하기 때문이다. srand를 호출하여 seed 값을 가져온 이후에 rand를 한 개의 쓰레드로부터 반복해서 호출한다면 반복되는 숫자들의 배열을 기대할 수 있겠지만, 이 가정은 만일 다수의 쓰레드가 rand를 호출한다면 더이상 성립하지 않는다.
대신 상태를 매개변수를 통해 관리하게 된다면 앞선 문제를 개선할 수 있다. 해당 함수에 제공되는 매개변수는 각 쓰레드의 고유한 스택 영역에 해당하기 때문에 쓰레드 간 공유 문제를 제거할 수 있다. 다음 코드는 그와 같은 해결을 보여준다.
/* read - return pseudo-random integer on 0..32767 */
int rand_r(int *nextp)
{
*nextp = *nextp * 1103515245 + 12345;
return((unsigned)(*nextp/65536) % 32768);
}매개변수를 도입함에 따라 전역 변수에 의존하여 상태를 의존하지 않게 되었다. 즉 공유 데이터는 전혀 참조되지 않으며 이를 재진입 가능한 함수라고 부르며 그에 따른 속성을 재진입성(Reentrancy)이라고 부른다. 흔히 재진입성과 Thread-safety, Thread-unsafe 와의 관계를 많이 헷갈리는데, 다음 그림을 통해 보다 명확히 이해할 수 있다.
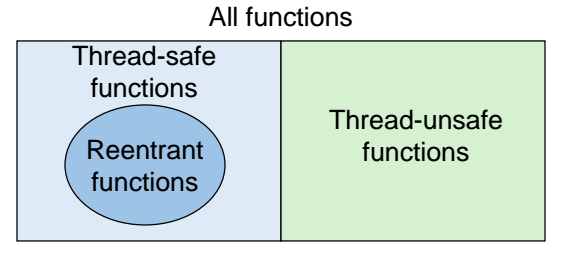
모든 함수는 크게 Thread-safe 한 함수와 Thread-unsafe 함수로 나뉜다. Thread-safety 측면에서 앞서 살펴본 것처럼 동기화를 통해 Thread-safe를 달성할 수 있다. 그러나 애초에 공유 변수에 접근하지 않는 함수들도 Thread Safe 하다고 할 수 있다. 이를 우리는 재진입가능한 함수라고 부르게 된다.
- 클래스 3: 정적 변수를 가리키는 포인터를 리턴하는 함수. ctime과 gethostbyname과 같은 함수들은 static 변수에 결과를 계산하고 그 이후에 이 변수를 가리키는 포인터를 리턴한다. 만일 이러한 함수들을 동시성 쓰레드로부터 호출한다면 재앙이 발생할 수 있다. 그 이유는 한 개의 쓰레드가 사용하는 결과들이 다른 쓰레드들에 의해 조용히 덮어써지기 때문이다.
이를 크게 2 가지 방법으로 대처할 수 있다.
옵션 1. 함수를 다시 작성하여 호출자가 결과를 저장하는 변수의 주소를 전달하도록 변환
이렇게 하면 모든 공유 데이터를 없앨 수 있지만, 이 방법은 프로그래머가 함수의 소스코드를 접근할 수 있다는 것을 가정해야만 한다.
옵션 2. lock-and-copy
만일 Thread-unsafe 함수가 수정하기 어렵거나 불가능하다면, 다른 옵션은 lock-and-copy 기술을 사용하는 것이다. 기본 아이디어는 뮤텍스를 Thread-unsafe 함수와 연계하는 것이다. 각각의 호출 위치에서 뮤텍스를 잠그고, 그 이후 thread-unsafe 함수를 호출하고, 함수가 리턴한 결과를 사적 메모리 공간에 복사하고, 그 이후에 뮤텍스를 풀어준다. 다음의 예시는 앞서 설명한 lock-and-copy를 코드로 표현한 것이다.
char *ctime_ts(const time_t *timep, char *privatep)
{
char *sharedp;
P(&mutex);
sharedp = ctime(timep);
strcpy(privatep, sharedp);
V(&mutex);
return privatep;
}- 클래스 4: Thread-unsafe 함수를 호출하는 함수들. 만일 어떤 함수 f 가 Thread-unsafe 한 함수 g 를 호출한다면, f는 때에 따라 Thread-unsafe 하다. 만일 g가 다수의 호출을 지나는 상태에 의존하는 클래스 2 함수라면 f는 Thread-unsafe 하다. 만일 g가 클래스 1, 3 함수일 경우, 뮤텍스를 적절히 활용한다면 f 는 여전히 Thread-safe 상태에 머물게 된다.
모든 표준 C 라이브러리는 Thread-safety를 보장한다. 또한 대부분의 Unix 시스템 콜 또한 Thread-safe 를 보장하지만 몇몇 예외가 존재한다.

'CS > OS' 카테고리의 다른 글
| 동기화 (4) Race (0) | 2022.12.07 |
|---|---|
| 동기화 (2) 세마포어 (0) | 2022.12.07 |
| 동기화 (1) (0) | 2022.12.07 |
| 쓰레드 (1) | 2022.12.07 |
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
동시성 프로그래밍의 개척자인 다익스트라는 서로 다른 실행 쓰레드를 동기화하는 문제에 대한 고전적인 해답을 세마포어라고 부르는 특별한 타입의 변수에 기초하여 제안하였다.
세마포어 s는 음수가 아닌 정수 값을 갖는 전역 변수로 두 개의 특별한 연산인 P와 V를 통해서만 조작이 가능하다.
- P(s): s가 0이 아닌 경우, P는 s를 감소시키고 즉시 리턴한다. 만일 s가 0이라면 쓰레드는 s가 0이 아닌 양의 정수가 될 때까지 기다렸다가, 이후 V 연산에 의해 s가 갱신된 이후에서야 다시 재시작한다. 재시작 이후에 P는 s를 감소시키고 제어권을 다시 호출자에게 돌려준다.
- V(s): V 연산은 s를 1 증가시킨다. 직전의 설명한 P의 반대라고 생각할 수 있다.
P에서 테스트와 감소 연산은 일단 세마포어 s가 0이 아니면 s의 감소가 중단 없이 일어난다는 의미에서 개별적으로 일어난다. 마찬가지로 V 또한 연산이 세마포어를 중단 없이 로드하고 증가하고 저장하기 때문에 개별적이라고 할 수 있다.
V의 정의가 기다리고 있는 쓰레드들이 재시작되는 순서를 정의하지 않는다는 것을 주목해야 한다. 앞서 세마포어의 유일한 요구사항은 V가 정확히 한 개의 대기하는 쓰레드를 재시작시켜준다는 것이였다.
그래서 여러 개의 쓰레드가 하나의 세마포어를 기다리고 있을 때, 어떤 쓰레드가 V의 결과로 재시작되는지는 예측이 불가능하다.
P와 V의 정의는 돌고 있는 프로그램에서 적절히 초기화된 세마포어가 음수 값을 갖는 상태로 절대 들어갈 수 없도록 보장해준다. 이 특성은 세마포어 불변성이라고 하며, 동시성 프로그램의 궤적을 제어하기 위한 강력한 도구를 제공한다.
P, V 이름의 기원
에드거 다익스트라는 네덜란드 사람으로, P()와 V()는 Proberen(테스트하기)와 Verhogen(증가시키기)라는 네덜란드어에서 유래되었다.
상호 배제를 위해 세마포어 이용하기
세마포어는 공유 변수들을 상호 배타적으로 접근하기 위한 편리한 방법을 제공한다. 기본 아이디어는 세마포어 s를 초기 값 1로 시작해서 각각의 공유 변수에 연계하고 그 후에 대응하는 크리티컬 섹션을 P(s)와 V(s)로 구성된 연산으로 둘러싸는 것이다.
이런 방법으로 공유 변수들을 보호하기 위해서 사용하는 세마포어를 바이너리 세마포어라고 한다. 그 이유는 이들의 값이 항상 0 또는 1이기 때문이다. 그 중에서 상호 배타성을 제공하는 목적으로 사용하는 바이너리 세마포어는 뮤텍스라는 이름으로 부른다. 뮤텍스에서 P 연산을 수행하는 것을 Locking이라고 부르며, 비슷하게 뮤텍스에서 V 연산을 수행하는 것을 unlocking이라고 부른다. 뮤텍스로 lock을 수행했지만 아직 unlock 하지 않은 쓰레드에 대해서는 뮤텍스를 holding 하고 있다고 표현한다.
위의 그림은 바이너리 세마포어를 이용해서 직전 글의 카운터 프로그램을 적절하게 동기화하는 지를 보여준다. 각각의 상태는 해당 상태에서 세마포어 값 s로 표현된다. 핵심 아이디어는 이와 같은 P와 V의 조합이 금지 구역이라고 불리는 상태들의 집합을 생성한다는 것이며, 금지 구역 내에서 s의 값은 음수가 된다.
앞서 설명하였듯 세마포어는 그 특성상 음수 값을 가질 수 없으며 해당 특성을 세마포어의 불변성이라고 소개하였다. 이때 금지 구역이 완전히 위험 구역을 감싸고 있다는 것에 주목해보자. 때문에 모든 가능한 궤적들은 위험 구역의 모든 부분을 지날 수 없다. 모든 가능한 궤적은 안전하고 런타임에 인스트럭션의 순서와 무관하게 정확히 카운터를 증가시킬 것이다.
이를 코드로 표현하면 다음과 같다. 먼저 뮤텍스라고 불리는 세마포어를 선언한다.
volatile int cnt = 0; /* Counter */
sem_t mutex; /* Semaphore that protects counter */그리고 그 후에 main 루틴에서 1로 초기화한다.
Sem_init(&mutex, 0, 1);마지막으로 쓰레드 루틴에서 P와 V 연산으로 공유 변수 cnt를 둘러싸서 이 변수의 갱신을 보호하며 동기화를 구현한다.
void *thread(void *vargp)
{
int i, niters = *((int *)vargp);
for (i = 0; i < niters; i++) {
P(&mutex);
cnt++;
V(&mutex);
}
return NULL;
}
다만 명심해야 할 점은 세마포어의 P와 V를 아무 곳에서나 남발해서는 안된다는 것이다. P와 V를 자주 사용한다면, 그만큼 동기화 측면에서 안정성을 보장받을 수는 있겠으나 앞서 설명했던 바와 같이 세마포어 연산들은 기존 흐름들을 중단시키는 작업을 포함할 수 밖에 없다. 시스템에 부하가 생겨 발생하는 오버헤드는 아니지만, 프로그램의 속도에 심각한 영향을 끼칠 수 있기에 반드시 필요한 적재적소의 라인에 작성해주는 것이 핵심이다.
'CS > OS' 카테고리의 다른 글
| 동기화 (4) Race (0) | 2022.12.07 |
|---|---|
| 동기화 (3) Thread Safety (0) | 2022.12.07 |
| 동기화 (1) (0) | 2022.12.07 |
| 쓰레드 (1) | 2022.12.07 |
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
쓰레드 메모리 모델
동시성 쓰레드의 풀은 한 개의 컨텍스트에서 돌아간다. 각각의 쓰레드는 자신만의 별도의 쓰레드 컨텍스트를 가지며, 여기에는 쓰레드 ID, 스택, 스택 포인터, 프로그램 카운터, 조건 코드, 범용 레지스터 값이 포함될 것이다. 각 쓰레드는 프로세스의 가상주소공간을 공유하며 여기에는 코드 섹션, 데이터 섹션, 힙, 공유 라이브러리 코드 등을 포함할 것이다.
각 쓰레드는 별도의 스택 저장소를 가지고 있으며 때문에 한 쓰레드가 다른 쓰레드의 스택에 접근하여 이를 읽거나 쓰는 등의 행동은 불가능하다. 또한 각자 고유한 레지스터를 참조하고 있기 때문에 다른 쓰레드의 레지스터에 접근하여 읽고 쓰는 것도 불가능해진다. 마지막으로 쓰레드들은 각자 고유한 PC 값을 가지고 분리된 형태의 논리 흐름으로 전개된다.
프로세스를 분기시켜 동시에 여러 논리 흐름을 전개하는 것은 이러한 쓰레드의 단점을 보완할 수 있다. 프로세스를 분기시키는 경우, 자식 프로세스는 부모 프로세스의 가상주소공간에 대한 사본을 얻는다. 때문에 자식 프로세스에서 부모 프로세스의 가상주소공간에 접근이 불가능하며, 반대의 경우도 마찬가지이다.
그러나 이는 또 다른 단점을 낳는다. 바로 데이터들의 공유가 어려워지는 것이다. 프로세스에서는 변수 값등을 공유하기 위해서 IPC(inter-process communication)라는 특별한 매커니즘을 거친다. IPC는 쓰레드의 방식보다 비싸다. 데이터를 공유하기 위해서 시간적으로 소모가 많이 발생하며 이를 다른 말로 오버헤드가 크다라고 부른다. 이때 IPC를 수행하는 방식에는 다양한 방식이 있는데, 이는 추후 글에서 다시 살펴보도록 하자.
쓰레드는 프로세스의 이러한 단점을 보완할 수 있다. 앞서 설명했듯 쓰레드는 프로세스와 달리 하나의 논리흐름을 가지되, 완전한 분리가 이뤄지진 않았다. 앞서 설명하였듯 일반적으로 쓰레드 풀 내에서는 쓰레드 컨텍스트들을 공유할 수 있으며 IPC와 같은 번거로운 작업 없이, 전역 변수를 통해서 데이터를 공유할 수 있다.
다만 이는 Race 라는 또 다른 문제를 낳는다. 만약 동시에 여러 쓰레드가 하나의 자원에 접근한다면? 하나의 쓰레드가 해당 자원을 사용하고 있는데 만약 다른 쓰레드가 해당 자원에 접근하고자 한다면? 등과 같은 문제가 발생한다. 해당 글에서는 이러한 문제를 보완하기 위한 동기화라는 개념을 설명한다.
변수들을 메모리로 매핑하기
쓰레드를 사용하는 C 프로그램의 변수들은 이들의 저장 클래스에 따라서 가상메모리에 매핑된다.
전역 변수. 전역 변수는 함수 밖에서 선언된 모든 변수를 말한다. 런타임에 가상메모리의 읽기/쓰기 영역은 쓰레드에 의해 참조될 수 있는 각각의 전역 변수의 정확히 한 개의 인스턴스를 포함한다.
지역 자동 변수. 지역 자동 변수는 함수 내에서 static 특성 없이 선언된다. 런타임에 각 쓰레드의 스택은 자신만의 지역 자동 변수의 인스턴스를 가진다. 이는 심지어 다수의 쓰레드가 동일한 쓰레드 루틴을 사용하는 경우에도 그렇다.
지역 정적 변수. 지역 정적 변수는 함수 안에서 static 특성으로 선언된 변수다. 전역 변수처럼 가상메모리의 읽기 쓰기 영역은 프로그램에서 선언된 각 지역 정적 변수의 정확히 한 개의 인스턴스를 가진다.
공유 변수
어떤 변수 v는 자신의 인스턴스 중의 한 개가 하나 이상의 쓰레드에 의해 참조되는 경우에만 공유되어 있다고 말한다.
동기화 오류
공유 변수들은 편리하지만 심각한 동기화 오류를 가져올 수 있다. 다음의 예제를 살펴보자
#include <ptrhead.h>
#include <stdio.h>
#include <stdlib.h>
void *thread(void *vargp); /* Thread routine prototype */
/* Global Shared variable */
volatile int cnt = 0; /* Counter */
int main(int argc, char **argv)
{
int niters;
pthread_t tid1, tid2;
/* Check input argument */
if (argc != 2)
{
printf("usage: %s <niters>\n", argv[0]);
exit(0);
}
niters = atoi(argv[1]);
Pthread_create(&tid1, NULL, thread, &niters);
Pthread_create(&tid2, NULL, thread, &niters);
Pthread_join(tid1, NULL);
Pthread_join(tid2, NULL);
/* Check result */
if (cnt != (2 * niters))
printf("BOOM! cnt=%d\n", cnt);
else
printf("OK cnt=%d\n", cnt);
exit(0);
}
void *thread(void *vargp)
{
int i, niters = *((int *)vargp);
for (i = 0; i < niters; i++)
cnt++;
return NULL;
}
위와 같은 코드는 실행마다 그 결과가 달라진다. 이는 공유 변수에 대한 접근 순서가 정해져있지 않기 때문이다. 우리는 코드를 한줄 한줄 문법에 따라 작성한다. 그러나 우리가 바라보는 코드와 달리 실제 컴퓨터가 해석하는 코드는 각 라인을 더욱 세분화하여 이를 여러 사이클에 수행할 수 있도록 변환한다. 때문에 우리가 보는 코드보다 실제 기계어 단의 명령어는 훨씬 길고 복잡하다.
사실 우리 눈에는 공유 변수의 동기화가 굳이 필요할까라는 의문이 드는 코드가 종종 있다. 위의 코드도 마찬가지이다. 쓰레드 핸들러는 간단하게 반복문을 특정 단위로 반복할 뿐이다. 반복에 사용되는 변수는 공유변수가 아니기에 반복문 자체는 문제 없이 당초 의도만큼 돌아갈 것이다. 다만 cnt가 문제가 된다. 이 부분이 다소 조금 헷갈리는데, cnt가 당초 정해진 반복문만큼 증가 연산을 했다면 문제가 없는 것 같은 착각이 든다.
그러나 그렇지 않다. 앞서 말했듯, cnt++ 라고 적힌 한줄의 코드는 사실 여러 줄의 기계어로 표현될 여지가 있다. 이는 CPU 아키텍쳐마다 다르며 하드웨어의 고유한 최적화 방식에 의존한다.
결국 이러한 코드는 앞서 말했던 동기화 오류를 발생시킨다.
진행 그래프 ( Progress Graph )
진행 그래프는 n 개의 동시성 쓰레드를 n 차원의 직교좌표 공간을 지나는 궤적으로 모델링한다. 이때 각각의 축 k는 쓰레드 k의 진행에 대응되며 각각의 점 I는 쓰레드 K가 특정 인스트럭션 I를 완료한 상태를 나타낸다.
진행 그래프를 작성하면 실제 쓰레드의 진행이 어떻게 되는지를 시각적으로 표현할 수 있다. 좀 더 구체적으로 쓰레드의 동기화 문제가 발생할 여지가 있는 가능성을 시각적으로 표현할 수 있다.
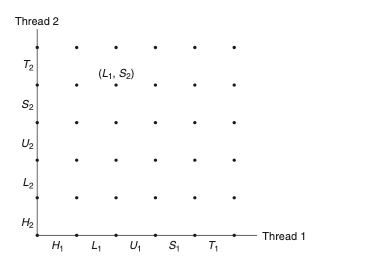
위의 그래프는 진행 그래프를 본격적으로 그리기 전의 초기화 상태를 보여준다. 해당 상태에서 그래프는 오로지 오른쪽과 위쪽만으로 진행을 하게 된다. 대각선과 왼쪽, 아래로의 이동은 불허한다.
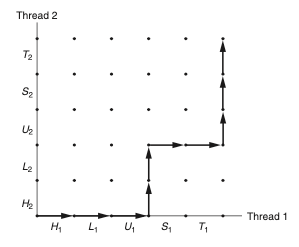
쓰레드 프로그래밍을 수행하면 특정 쓰레드 i에 대해서 공유 변수 cnt의 내용을 조작하는 인스트럭션들은 크리티컬 섹션을 형성한다. 크리티컬 섹션에서는 특정 공유 자원에 대해서 다른 쓰레드들로부터 상호 배타적으로 공유 변수를 접근하도록 보장받아야 한다. 만약 그렇지 않는다면, 앞서 발생했던 동기화 오류가 발생할 가능성이 존재한다. 일반적으로 이러한 현상을 상호 배제 (mutual exclusion)라고 하며, 이는 이후 동기화를 가능하게 하는 핵심 요소로 기능한다.
진행 그래프에서 두 개의 크리티컬 섹션의 교차점은 위험 구역이라는 상태 공간의 구역을 정의하는데, 만약 위험 영역에 침범한 궤적은 동기화 오류를 발생시킬 수 있다는 의미로 위험 궤적으로 불리게 된다. 이때 주의할 점은 위험 구역의 둘레에 접할 뿐인 궤적은 위험 궤적이 아니라는 점이다.
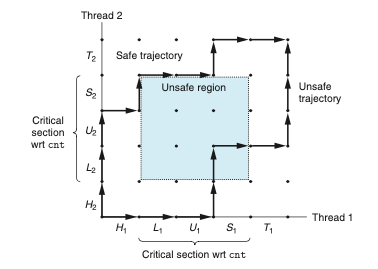
모든 안전 궤적은 공유 변수를 정확하게 갱신할 것이다. 쓰레드들은 어떤 방식으로든 동기화를 통해 이들이 항상 안전 궤적을 가지도록 해야 한다. 고전적인 방법은 세마포어 개념에 기초한 것으로 바로 다음 글에서 소개하고자 한다.
'CS > OS' 카테고리의 다른 글
| 동기화 (3) Thread Safety (0) | 2022.12.07 |
|---|---|
| 동기화 (2) 세마포어 (0) | 2022.12.07 |
| 쓰레드 (1) | 2022.12.07 |
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
| 프로세스 제어 (0) | 2022.12.07 |
동시성 논리 흐름을 생성하는 대표적인 방법으로 크게 3 가지가 존재한다.
먼저, 각각의 흐름에 대해 별도의 프로세스를 생성하는 프로세스 기반 동시성 프로그래밍이 있다. 커널은 각각의 프로세스를 자동으로 스케쥴링하여 각 프로세스는 자신만의 고유한 사적 주소공간을 가지며 이로 인해 흐름들이 데이터를 공유하기가 어려워진다.
두 번째 방법으로 우리 자신의 논리흐름을 생성하고 명시적으로 이 흐름들을 스케쥴링하기 위해 I/O 다중화를 이용한다. 이 경우 단 하나의 프로세스만이 존재하기 때문에 흐름들은 전체 주소공간을 공유한다.
해당 글에서는 동시성 프로그래밍을 수행하기 위한 세 번째 방법인 쓰레드라는 개념을 소개하고자 한다.
쓰레드는 프로세스의 컨텍스트 내에서 돌아가는 논리 흐름이다. 앞서 프로세스를 설명하는 글에서는 자연스럽게 프로세스마다 하나의 쓰레드를 가정하였다. 그러나 현대 시스템은 다수의 쓰레드가 하나의 프로세스에서 동시에 돌아가는 프로그램을 작성할 수 있도록 해준다. 쓰레드는 프로세스와 마찬가지로 커널에 의해서 자동으로 스케쥴되며, 각 쓰레드는 고유의 정수 쓰레드 ID(TID)를 갖는다.
또한 별도의 스택, 스택 포인터, 프로그램 카운터, 범용 레지스터, 조건 코드를 포함하는 자신만의 고유한 쓰레드 컨텍스트를 갖는다. 다만 기억해야 하는 점은 한 개의 프로세스 내에 돌고 있는 모든 쓰레드는 해당 프로세스의 전체 가상 주소를 공유한다는 것이다.
쓰레드의 기초한 논리흐름은 프로세스와 I/O 다중화에 기초한 흐름의 품질을 결합해준다. 프로세스와 같이, 쓰레드는 커널에 의해 자동으로 스케쥴되고 커널에 정수 ID로 알려진다. I/O 다중화에 기초한 흐름에서와 같이 다수의 쓰레드는 한 개의 프로세스의 컨텍스트에서 돌아가며 그러므로 이 프로세스 가상 주소 공간의 전체 내용을 공유한다.
이때 프로세스의 가상 주소 공간에는, 코드, 데이터, 힙, 공유 라이브러리, 파일 디스크립터 테이블 등이 포함된다.
쓰레드 실행 모델
다중 쓰레드에 대한 실행 모델은 다중 프로세스를 위한 실행 모델과 어떤 면에서는 비슷하다.
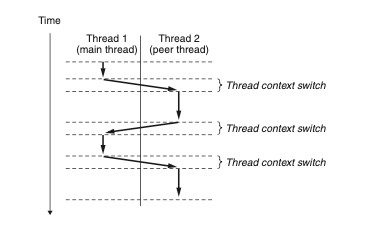
위의 그림에서 각 프로세스는 메인 쓰레드라고 부르는 한 개의 쓰레드로 실행을 시작한다. 어떤 시점에서 메인 쓰레드는 피어(Peer) 쓰레드를 생성하고 이때부터 두 쓰레드가 동시에 돌아간다. 결국 제어는 컨텍스트 스위치를 거쳐 피어 쓰레드로 전달되며, 그 이유는 메인 쓰레드가 read나 sleep과 같은 느린 시스템 콜을 실행했거나, 시스템의 인터벌 타이머에 의해 중단되었기 때문이다. 피어 쓰레드는 제어를 다시 메인 쓰레드로 돌려주기 전에 잠시 실행되는 식으로 실행이 진행된다.
쓰레드의 실행은 일부 중요한 부분에서 프로세스와 다른다. 쓰레드 컨텍스트가 프로세스 컨텍스트보다 훨씬 더 작기 때문에, 쓰레드의 컨텍스트 스위치는 프로세스의 컨텍스트 스위치보다 훨씬 빠르다.
또 다른 차이점은 쓰레드가 프로세스와 달리 엄격한 상위-하위 계층 구조로 구성되지 않는다는 것이다. 프로세스와 연결된 쓰레드는 피어 풀을 형성하며, 누가 해당 쓰레드를 생성하였다는 것을 구분하지 않는다. 즉, 프로세스에서 엄격하게 부모와 자식 프로세스를 나눴던 것과 달리 쓰레드에서는 이러한 부모-자식 계층 구조가 없다. 단지, 주 쓰레드는 프로세스에서 항상 처음 실행되는 쓰레드라는 점에서만 다른 스레드와 구별될 뿐이다. 이러한 피어 풀 개념을 굳이 사용하는 이유는 쓰레드가 피어를 죽이거나 피어가 종료될 때까지 기다릴 수 있다는 점에 있다. 또한 하나의 프로세스에 연결된 피어들은 프로세스의 가상 주소 공간 전체를 공유하게 된다.
Posix 쓰레드
posix 쓰레드(pthread)는 C 프로그램에서 쓰레드를 조작하는 표준 인터페이스이다. 이것은 1995년 채택되어 대부분의 Unix 시스템이 이를 공유하는 구조를 갖고 있다.
아래 프로그램은 간단한 Pthread 프로그램을 보여준다. Pthread는 데이터를 피어쓰레드와 안전하게 공유하기 위해서, 시스템의 상태 변화를 피어들에게 알리기 위해서 프로그램이 쓰레드를 생성하고, 죽이고, 청소하도록 하는 약 60개의 함수를 정의한다.
#include <pthread.h>
#incldue <stdio.h>
#include <stdlib.h>
void *thread(void *vargp);
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, thread, NULL);
pthread_join(tid, NULL);
exit(0);
}
void thread(void *vargp)
{
printf("Hello, world!\n");
}
프로그램 실행 자체는 간단하다. 해당 프로그램은 먼저, thread라는 쓰레드 루틴을 가지고 쓰레드를 생성한다(pthread_create). 각 쓰레드 루틴의 실행이 완료가 되면 pthread_join을 가지고 자원을 회수하게 된다.
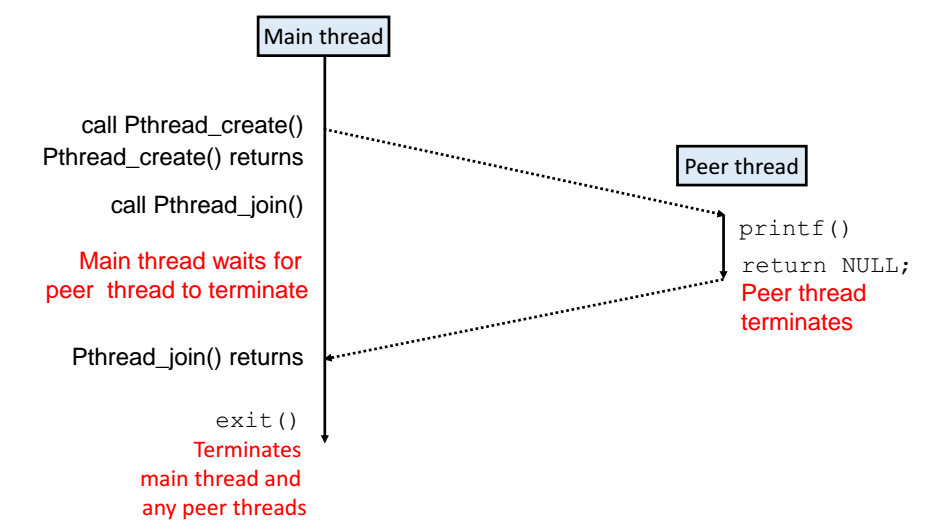
다만 함수에 익숙하지 않다면 이러한 쓰레드의 동작이 낯설 수 있다.
함수를 소개하자면 다음과 같다.
pthread_create: 쓰레드를 생성하는 함수
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);pthread_create 함수는 새 쓰레드를 만들고 쓰레드 루틴 start_routine을 새 쓰레드의 컨텍스트 내에서 수행한다. 이때의 입력인자는 arg로 전달된다.
attr 인자는 새롭게 만들어진 쓰레드의 기본 성질을 바뀌기 위해 사용될 수 있다.
pthread_exit: 쓰레드 명시적으로 종료
#include <pthread.h>
void pthread_exit(void *thread_return);만일 메인 쓰레드가 pthread_exit을 호출하면 다른 모든 쓰레드가 종료하기를 기다리고 그 후에 메인 쓰레드가 전체 프로세스를 thread_return 값으로 종료한다.
일부 피어 쓰레드는 Unix exit 함수를 호출하여 프로세스와 해당 프로세스와 관련된 쓰레드를 모두 종료한다.
다른 피어 쓰레드는 pthread_cancel 함수를 현재 쓰레드의 ID로 호출하여 현재 쓰레드를 종료한다.
pthread_cancel: 자기 자신 종료
#include <pthread.h>
int pthread_cancel(pthread_t tid);
pthread_join: 종료한 쓰레드 청소
#include <pthread.h>
int pthread_join(pthread_t tid, void **status);쓰레드는 pthread_join 함수를 통해 다른 쓰레드가 종료하기를 기다릴 수 있다.
pthread_detach: 쓰레드 분리하기
#include <pthread.h>
int pthread_detach(pthread_t tid);언제나 쓰레드는 연결가능하거나 분리되어 있다. 연결가능한 쓰레드는 다른 쓰레드에 의해 청소되고 종료될 수 있으며 자신의 메모리 자원(스택 등)은 다른 쓰레드에 의해 청소될 때까지는 반환되지 않는다. 반대로 분리된 쓰레드는 다른 쓰레드에 의해 청소되거나 종료될 수 없다. 자신의 메모리 자원들은 이 쓰레드가 종료할 때 시스템에 의해 자동으로 반환된다.
예를 들어 고성능 웹 서버는 웹 브라우저로부터 연결 요청을 수락할 때마다 새로운 피어 쓰레드를 생성할 수 있다. 각각의 연결이 별도의 쓰레드에 의해서 독립적으로 처리되기에 서버가 명시적으로 각각의 피어 쓰레드가 종료하기를 기다리는 것은 불필요하다.
이 경우에는 대신 각 피어 쓰레드는 요청을 처리하기 전에 자신을 메인 쓰레드가 속한 피어풀에서 분리하여 자신의 메모리 자원들이 종료 이후에 자동으로 반환될 수 있도록 한다.
쓰레드의 메모리 모델
동시성 쓰레드 풀은 한 개의 프로세스 컨텍스트에서 돌아간다. 각각의 쓰레드는 자신만의 별도의 쓰레드 컨텍스트를 가지며, 여기에는 쓰레드 ID, 스택, 스택 포인터, 프로그램 카운터, 조건 코드, 범용 레지스터 값들이 포함된다. 각 쓰레드는 나머지 프로세스 컨텍스트를 다른 쓰레드와 공유한다. 여기에는 해당 프로세스의 가상 주소공간이 포함되며, 앞서 설명하였듯 .code 와 .data, .bss, 힙, 공유 라이브러리 코드 등이 여기에 해당한다. 마지막으로 단일 프로세스 내의 쓰레드는 동일한 파일 디스크립터 테이블을 공유한다.
동작적인 측면에서 하나의 쓰레드가 다른 쓰레드의 레지스터를 읽거나 쓰는 것은 불가능하지만 모든 쓰레드는 공유 가상메모리 내의 모든 위치에 접근할 수 있다. 만일 어떤 쓰레드가 메모리의 위치를 수정하면 그 위치를 읽는 다른 모든 쓰레드는 이 변경 사항을 알 수 있다. 그래서 레지스터들은 공유되지 않지만, 가상 메모리는 항상 공유된다.
이는 장점이자 단점으로, 앞서 프로세스가 데이터를 공유하기 위해서 IPC를 거쳐 오버헤드가 발생했던 점을 생각하면 장점으로 작용하지만, 동시에 여러 프로세스가 별다른 규칙 없이 공유 자원에 접근할 수 있다는 점에서 여러 문제를 가져오게 되며 Synchronization 에 대한 필요성을 낳게 된다.
결론
쓰레드는 프로세스의 단점을 보완하는 한편, 고유한 단점도 존재한다. 쓰레드를 너무 크게 쪼개면 수행할 동시성 작업이나 병렬 처리의 장점이 잘 드러나지 않고, 쓰레드를 너무 잘게 쪼개면 쓰레드 오버헤드가 늘어나게 되어 실행 속도가 느려질 뿐만 아니라 쓰레드가 차지할 메모리 공간의 총합이 너무 방대해진다는 문제가 있다. 때문에 쓰레드를 사용하기에 앞서 쓰레드의 단위를 어떻게 설정할지 또한 프로세스 대신 쓰레드를 사용해야 하는 이유에 대해서 심도있는 고민이 필요할 듯 보인다.
'CS > OS' 카테고리의 다른 글
| 동기화 (2) 세마포어 (0) | 2022.12.07 |
|---|---|
| 동기화 (1) (0) | 2022.12.07 |
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
| 프로세스 제어 (0) | 2022.12.07 |
| 시스템 콜의 에러 처리 (0) | 2022.12.07 |
동시성 프로그램을 만드는 가장 간단한 방법은 프로세스를 사용하는 것이며, fork, exec, waitpid와 같은 친숙한 함수를 활용하여 주로 구현된다. 예를 들어 동시성 서버를 구현하는 자연스러운 방법은 부모에서 클라이언트 연결 요청을 수락하여, 이후 새로운 자식 프로세스를 생성하여 각각의 새로운 클라이언트를 서비스하는 것이 있다.
이것이 어떻게 동작하는지 알아보기 위해 두 개의 클라이언트와 listen 식별자에서 연결 요청을 기다리는 하나의 서버가 있다고 가정하자.
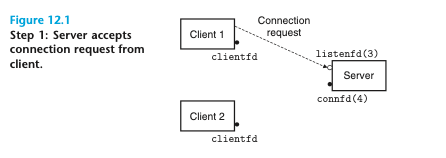
연결 요청을 서버가 수락하게 되면 해당 그림의 connfd(4) 처럼 연결 요청을 수락하게 된다. 서버는 자식을 fork 하고, 자식은 서버의 식별자 테이블 사본 전체를 가져오게 된다.
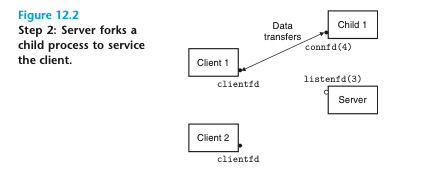
자식은 listenfd(3)의 자신의 사본을 닫고 부모는 connfd(4)에 대한 자신의 사본을 닫는데, 그 이유는 이들이 더 이상 필요하지 않기 때문이다. 이때 자식 프로세스는 클라이언트를 서비스하느라 바쁜 상태이다. 부모와 자식의 연결 식별자들은 각각 동일한 파일 테이블 엔트리를 가리키지 때문에 부모가 이 연결 식별자의 자신만의 사본을 닫는 것은 매우 중요하다. 그렇지 않으면 연결 식별자 4에 대한 테이블 엔트리는 절대로 반환되지 않으며, 이는 메모리 누수로 이어져 가용 메모리의 소모로 시스템을 죽게 만들 수 있다.
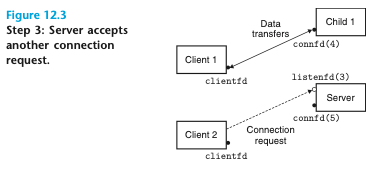
이후 부모는 클라이언트 1을 위한 자식을 만든 이후에도 클라이언트 2에 대한 연결 요청을 수락하고 새로운 연결 식별자 connfd(5)를 리턴한다. 부모는 계속해서 새로운 자식을 fork하고, 또 계속해서 다음 연결 요청을 기다리게 된다.
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_strorage clientaddr;
signal(SIGCHLD, sigchld_handler);
listenfd = open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = accept(listenfd, (struct sockaddr *)&clientaddr, &clientlen);
if (fork() == 0) {
close(listenfd); // 자식 프로세스는 listenfd를 닫는다.
echo(connfd); // 동작을 수행하고 종료
close(connfd);
exit(0);
}
close(connfd); // 부모 프로세스는 connfd를 닫는다.
}
}
프로세스 기반 동시성 서버의 특징은 다음과 같다.
- 서버들은 장기간 돌아가므로 좀비들을 처리하는 SIGCHLD 핸들러가 필수적이다. SIGCHLD 시그널들은 SIGCHLD 핸들러가 돌고 있는 동안 블록되고 Unix 시그널들은 큐에 들어가지 않기에 SIGCHLD 핸들러는 다수의 좀비 자식들을 청소할 준비를 해야한다.
- 부모와 자식은 connfd 사본을 닫아야 한다. 앞에서 말했듯, 이는 부모 쪽에서 특히나 더 중요하며 메모리 누수를 피하기 위해 자식으로 분기된 연결 식별자의 사본을 닫아야 한다.
- 마지막으로, 소켓의 파일 테이블 엔트리 내의 참조 카운트 때문에 클라이언트로의 연결은 부모와 자식의 connfd 사본이 모두 닫힐 때까지는 종료되지 않을 것이다.
프로세스의 장단점
프로세스는 부모와 자식 사이에 상태 정보를 공유하는 것에 대해 깔끔한 모델을 가지고 있다. 단적인 예로 사용자 주소 공간이 분리된다. 프로세스들이 분리된 주소 공간을 가지는 것은 장점이자 단점인데 한 프로세스가 우연히 다른 프로세스의 가상 메모리에 접근하는 것은 불가능하며, 이로 인해 많은 혼란을 제거할 수 잇다.
그러나 별도의 주소공간은 프로세스가 상태 정보를 공유하는 것을 어렵게 한다. 정보를 공유하기 위해서 IPC 매커니즘을 거쳐야만 하는데, 이는 프로세스 제어와 IPC를 수행하기 위해서 추가적인 오버헤드를 야기시킨다는 단점으로 작용한다.
'CS > OS' 카테고리의 다른 글
| 동기화 (1) (0) | 2022.12.07 |
|---|---|
| 쓰레드 (1) | 2022.12.07 |
| 프로세스 제어 (0) | 2022.12.07 |
| 시스템 콜의 에러 처리 (0) | 2022.12.07 |
| 컨텍스트 스위치 (0) | 2022.12.06 |
Unix는 C 프로그램으로부터 프로세스를 제어하기 위한 많은 시스템 콜을 제공한다. 해당 글에서는 프로세스를 제어하는 많은 함수들을 설명하고 이를 어떻게 사용하는지 예제를 통해 알아보고자 한다.
프로세스의 생성과 종료
프로그래머의 관점에서 프로세스는 다음의 세 가지 상태 중의 하나로 분류할 수 있다.
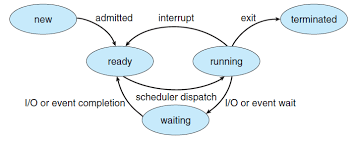
- 실행중(Running): 프로세스는 CPU에서 실행하고 있거나 실행을 기다리고 있으며, 궁극적으로 커널에 의해서 스케쥴될 것이다. 해당 그림에서 ready와 running을 묶은 개념이다.
- 정지(Stopped): 프로세스의 실행은 정지된 상태이고 스케쥴되지 않는다. 프로세스는 SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU 시그널을 바게되면 그 결과로 정지며, SIGCONT 시그널을 받을 때까지 정지 상태로 남아있으며, 이 시그널을 받은 시점에 다시 시작할 수 있다. (Waiting 상태라고 생각할 수 있다.)
- 종료(Terminated): 프로세스가 영구적으로 정지된 상태이다. 프로세스는 다음의 세가지 이유 중 하나로 종료된다. (1) 프로세스를 종료하는 시그널, SIGTERM, SIGINT 을 받았을 때, (2) 메인 루틴에서 리턴하여 정해진 동작이 끝났을 때, (3) exit 함수를 호출할 때
fork()
부모 프로세스는 fork 함수를 불러서 자식프로세스를 생성할 수 있다.
새롭게 생성된 자식 프로세스는 완벽히는 아니지만 부모와 동일하다. 자식은 텍스트, 데이터, bss 세그먼트, 힙, 사용자 스택을 포함하는 부모의 사용자 수준 가상 주소공간과 동일한 복사본을 갖는다.
자식은 또한 부모가 오픈한 파일 디스크립터에 대해서 동일한 사본을 갖는다. 이는 부모가 fork를 호출했을 때 자식이 부모가 오픈한 파일 모두를 읽고 쓸 수 있다는 것을 의미한다. 부모와 새롭게 생성된 자식 간의 중요한 차이는 PID가 다르다는 점이다.
1) fork 함수는 한 번 호출되지만 두 번 리턴된다. 이 부분이 fork를 가장 헷갈리게하는데. 사실 당연하지만 처음 들으면 한 번쯤 헷갈릴 만한 주제이다. fork를 호출하면 부모에서 자식의 PID를 리턴한다. 한편, 자식에서는 fork의 리턴 값으로 0을 받아 본인이 해당 fork로부터 생성된 프로세스라는 것을 알게 된다.
2) fork 함수에서 부모와 자식은 동시에 실행된다. fork는 부모와 자식 프로세스가 동시적으로 실행되게 한다. 이때 각각의 프로세스는 독립된 논리 흐름으로서 별도의 작업 없이는 어떤 작업이 먼저 수행될지 알 수 없다. 이는 전적으로 커널의 스케쥴러의 역할이다.
3) 자식은 부모의 사적 주소 공간을 복사한다. 만일 부모와 자식을 각 프로세스에서 fork 함수가 리턴한 직후에 중단할 수 잇다면, 각 프로세스의 주소공간이 동일하다는 것을 알 수 있을 것이다. 그러나 fork가 호출된 이후, 부모와 자식 프로세스는 각자의 진행에 따라 사적 주소 공간의 구조가 변화하게 된다. 이러한 변화는 본인의 컨텍스트에서만 확인할 수 있으며, 다른 프로세스의 메모리에서는 확인이 불가능할 것이다.
4) 파일 디스크립터 테이블은 공유된다. 자식은 부모가 오픈한 모든 파일을 상속받는다. 부모가 fork를 호출할 때를 기점으로 파일 디스크립터 테이블은 그대로 상속되어 복사되며, 분기 이후의 파일 디스크립터 테이블은 당연하게도 서로 독립적으로 관리된다.
자식 프로세스의 청소
프로세스가 어떤 이유로 종료할 때, 커널은 프로세스를 즉시 제거하지 않는다. 대신 프로세스는 부모가 청소할 때까지 종료된 상태로 남아 있는다. 부모가 종료된 자식을 청소할 때 커널은 자식의 exit 상태를 부모에게 전달하며 그 후 종료된 프로세스를 없애며 이 시점에서 프로세스가 사라지게 된다.
만약 청소 과정이 생략된 채 프로세스가 종료되었다면 이를 좀비 프로세스라고 부르며, 비록 좀비들은 실행되고 있지 않을 지라도 이들은 여전히 계속해서 시스템 메모리 자원을 점유하게 된다. 만일 부모 프로세스가 좀비가 된 자신의 자식 프로세스를 청소하지 않고 종료하면, 커널은 init 프로세스로 하여금 이들을 청소하도록 한다.
init 프로세스는 PID가 1인 프로세스이며, 시스템 초기화 시에 커널에 의해 생성되는 프로세스이다.
자식 프로세스를 청소하는 방법에는 두가지(wait, waitpid)가 있는데, 해당 글에서는 waitpid 를 활용하여 자식 프로세스를 청소하는 과정을 소개하고자 한다.
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
Returns: PID of child if OK, 0 if WNOHANG and no child ready, -1 on error
1) pid : 각각의 경우 waitpid에서의 처리가 다르다
- pid > 0 : pid 값이 동일한 child process를 기다린다.
- pid == 0 : group pid (gpid)가 같은 프로세스를 기다린다.
- pid == -1 : 임의의 child process를 기다린다.
- pid < -1 : pid와 절댓값이 같은 group pid를 가진 자식 프로세스를 기다린다.
2) status : waitpid에 의해 기다려진 프로세스의 정보를 담게 된다.
3) options : waitpid의 동작을 설정할 수 있다. 설정하지 않을 경우 0이다.
- WNOHANG : 기다리고자 pid의 프로세스에 대해 모두 종료되지 않았으나 기다리지 않고 waitpid 이후의 코드를 실행하고자 할 때 사용하는 옵션이다. 기다리지 않았을 경우 waitpid의 반환 값은 0이다. (NON-BLOCKING)
- WUNTRACED : Stop 된 proccess들에 대해서도 waitpid에서 처리를 한다.
- WCONTINUED : Continue 된 process들에 대해서도 waitpid에서 처리를 한다.
에러조건
호출하는 자식 프로세스가 없다면 -1 리턴, errno를 ECHILD로 설정. 어떤 시널에 의해 waitpid가 중단되었다면 -1을 리턴, errno를 EINTR로 설정
'CS > OS' 카테고리의 다른 글
| 쓰레드 (1) | 2022.12.07 |
|---|---|
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
| 시스템 콜의 에러 처리 (0) | 2022.12.07 |
| 컨텍스트 스위치 (0) | 2022.12.06 |
| 프로세스 (0) | 2022.12.06 |
Unix의 시스템 수준 함수가 에러를 만날 경우에는 대개 -1을 리턴하고 errno를 세팅해서 무엇이 잘못되었는지를 나타내게 된다.
예를 들어 fork 함수를 실행할 때는 다음과 같이 에러를 처리한다.
if ((pid = fork()) < 0)
{
fprintf(stderr, "fork error %s\n", strerror(errno));
exit(1);
}strerrno 함수는 errno의 특정 값과 연계된 에러를 설명하는 텍스트 스트링을 리턴한다. 이 코드를 다음과 같이 에러 리포트 함수를 정의해서 약간 단순화할 수 있다.
void unix_error(char *msg)
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
}unix_error 함수를 통해 직전의 fork 함수를 다음과 같이 줄일 수 있다.
if (pid = fork() < 0)
unix_error("Fork error");이 함수를 에러 핸들링 랩퍼를 통해 더 단순화할 수 있다. 랩퍼 함수는 기존 fork 와 동일한 인자를 받아 프로세스를 복제하지만 추가적으로 에러를 체크해서 만일 문제가 있다면 종료한다.
pid_t Fork(void)
{
pid_t pid;
if ((pid = fork()) < 0)
unix_error("Fork error");
return pid;
}이 랩퍼를 호출할 경우 fork로 호출하는 것이 하나의 합축된 라인으로 줄어든다.
pid = Fork();'CS > OS' 카테고리의 다른 글
| 프로세스를 이용한 동시성 프로그래밍 (0) | 2022.12.07 |
|---|---|
| 프로세스 제어 (0) | 2022.12.07 |
| 컨텍스트 스위치 (0) | 2022.12.06 |
| 프로세스 (0) | 2022.12.06 |
| Exception Control Flow 소개 (0) | 2022.12.06 |