
What are Protocol Buffers?
Protocol buffer는 structured data(구조화 데이터)를 seriailize(직렬화)하기위한 Google의 언어 중립적, 플랫폼 중립적이며 확장 가능한 메커니즘입니다.
XML보다 작지만, XML보다 빠르고 단순합니다.
IDL(Interface Definition Language)로서 data structure를 정의한 다음, .proto 파일을 protocol buffer compiler(protoc)를 이용해 compile 합니다. Complie된 소스 코드를 사용하여 다양한 데이터 스트림에서 다양한 언어로 다양한 구조의 데이터를 쉽게 읽고 쓸 수 있습니다.
프로토콜 버퍼는 현재 Java, Python, Objective-C 및 C ++에서 생성 된 코드를 지원합니다. 새로운 proto3 버전을 사용하면 proto2에 비해 더 많은 언어(Dart, Go, Ruby 및 C #)을 사용할 수 있습니다.
Proto3 Guide
Protocol buffers는 크게 proto2와 proto3가 있지만 grpc에선 최신 버전인 proto3를 사용하기에 proto3를 보겠습니다.
Defining 메세지 type
먼저 아주 간단한 예를 봅시다.
각 요청에 쿼리 문자열, 관심있는 특정 결과 페이지 및 페이지 당 여러 결과가있는 검색 요청 메시지 형식을 정의한다고 가정 해 보겠습니다. 메시지 유형을 정의하는 데 사용하는 .proto 파일은 다음과 같습니다.
//syntax가 없으면 자동으로 proto2로 인식됨
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}SearchRequest 메시지 정의는이 유형의 메시지에 포함하려는 각 데이터에 대해 하나씩 세 개의 필드 (이름 / 값 쌍)를 지정합니다. 각 필드에는 이름과 유형이 있습니다.
Specifying Field Types
위의 예시에서 나온 Field types은 모두 scalar types입니다.(int32, string)
하지만 scalar type 뿐만 아니라 enum과 같은 다른 field type도 선언 가능합니다.
Assigning Field Numbers
각 field는 unique number를 갖습니다.
이 field number는 메세지 binary format에서 field를 식별하는데 사용됩니다. 즉 field number가 key가 되고 field type이 value가 되는 해시 구조를 지닙니다.
Field numbers의 값이 1~15 사이면 1 byte로 encoding 됩니다.
Field numbers의 값이 16~2047이면 2 bytes로 encoding 됩니다.
그렇기에 Field numbers의 값을 1~15 사이로 encoding 하는것이 효율적입니다.
Specifying Field Rules
메세지 fields는 다음 중 한 가지를 따릅니다.
- singular: well-formed된 메세지는 0 or 1개를 가질 수 있습니다.
- repeated: 이 field는 0을 포함해 여러번 반복될 수 있습니다.
Adding 메세지 Types
하나의 .proto 파일안에 다중 메세지 type이 정의될 수 있습니다. 이러한 방식은 다양한 관계를 표현하는데 도움 됩니다.
// comment(주석)은 C, C++ 스타일
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
message SearchResponse {
...}What’s Generated From Your .proto?
.proto 파일을 protocol buffer compiler에 의해 complied되면, 메세지는 serializing되어 output stream으로 나가고 parsing되어 input stream으로 들어옵니다. 대표적인 3가지는 다음과 같습니다.
- C ++의 경우 컴파일러는 파일에 설명 된 각 메세지 type에 대한 class와 함께 각 .proto에서 .h 및 .cc 파일을 생성합니다.
- Java의 경우 compiler는 각 메세지 type에 대한 class와 메세지 class instance 작성을위한 builder class가있는 .java 파일을 생성합니다.
- Python은 조금 다릅니다. Python compiler는 .proto에 각 메세지 type의 static discriptor가 있는 모듈을 생성 한 다음, meta class와 함께 런타임에 필요한 Python data access class를 작성하는 데 사용됩니다.
Encoding
Protocol buffer compiler가 encoding하는 방식을 알아봅시다.
Base 128 Varints
Varints는 1 or 그 이상의 bytes를 사용해서 integer를 serializing하는 방법입니다. 작은 숫자는 작은 bytes로 encoding 됩니다. 1 bytes 중에서 7 bits만 숫자 표현에 사용되고 맨 앞의 숫자는 msb(most significant bit)로 사용됩니다.
예시로 보자면, 숫자 1을 encoding 하면 다음과 같으며, msb는 set되지 않습니다.
0000 0001숫자 300은 다음과 같습니다
1010 1100 0000 0010
-> 010 1100 000 0010 // msb 버림
-> 000 0010 010 1100 // 7bits의 두 그룹을 reverse함
-> 000 0010 ++ 010 1100 // 두 그룹 합침
-> 100101100
-> 256 + 32+ 8 + 4 = 300메세지 Structure
메세지는 key-value 쌍입니다. 메세지의 binary version은 field number를 key로 사용합니다. 각 field의 이름과 선언 된 type은 메세지 type의 정의를 참조하여 decoding 끝에서만 확인할 수 있습니다.
사용 가능한 유형은 다음과 같습니다.
TypeMeaningUsed For
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded 메세지s, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
자료형, 자료구조
Scalar Value Types
scalar 메세지 field는 다음 중 하나의 type을 가집니다.
.proto TypeNotesC++ TypeJava TypePython Type
| double | double | double | float | |
| float | float | float | float | |
| int32 | Uses variable-length encoding.Inefficient for encoding negative numbers – if your field is likely to have negative values, use sint32 instead. | int32 | int | int |
| int64 | Uses variable-length encoding.Inefficient for encoding negative numbers – if your field is likely to have negative values, use sint64 instead. | int64 | long | int/long |
| uint32 | Uses variable-length encoding. | uint32 | int | int/long |
| uint64 | Uses variable-length encoding. | uint64 | long | int/long |
| sint32 | Uses variable-length encoding.Signed int value. These more efficiently encode negative numbers than regular int32s. | int32 | int | int |
| sint64 | Uses variable-length encoding.Signed int value.These more efficiently encode negative numbers than regular int64s. | int64 | long | int/long |
| fixed32 | Always four bytes.More efficient than uint32 if values are often greater than 228. | uint32 | int | int/long |
| fixed64 | Always eight bytes.More efficient than uint64 if values are often greater than 256. | uint64 | long | int/long |
| sfixed32 | Always four bytes. | int32 | int | int |
| sfixed64 | Always eight bytes. | int64 | long | int/long |
| bool | bool | boolean | bool | |
| string | A string must always contain UTF-8 encoded or 7-bit ASCII text, and cannot be longer than 232. | string | String | str/unicode |
| bytes | May contain any arbitrary sequence of bytes no longer than 232. | string | ByteString | str |
Enumerations
메세지 type을 정의 할 때, enum type을 쓸 수 있습니다.
예를 들어, 각 SearchRequest에 대해 Corpus field를 추가하려고하는데, Corpus는 UNIVERSAL, WEB, IMAGES, LOCAL, NEWS, PRODUCTS, VIDEO field를 가집니다. 다음 예제에서는 가능한 모든 값과 Corpus라는 enum을 추가했습니다
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;예시에서와 같이 모든 eunum type의 시작 defulat value는 0입니다.
만약 default value를 겹쳐서 사용하고 싶다면 option에 allow_alias를 사용하면 됩니다.
message Mymessage1 {
enum EnumAllowingAlias {
option allow_alias = true;
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
}
message Mymessage2 {
enum EnumNotAllowingAlias {
UNKNOWN = 0;
STARTED = 1;
// RUNNING = 1; // Uncommenting this line will cause a compile error inside Google and a warning 메세지 outside.
}
}enum 타입의 field들은 int32를 사용해야 합니다. 왜냐하면 enum value들은 varint encoding을 따르기 때문입니다.
Nested Types
메세지 type을 정의할 때, nested(중첩된)하게 선언도 됩니다.
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}Packages
optional하게 package specifier를 추가할 수 있습니다. 이를 통해 메세지 type 간에 충돌을 피할 수 있습니다.
package foo.bar;
message Open
{ ... }Defining Services
만약 gRPC와 함께 사용하고 싶다면, service 구문을 사용하면 됩니다. protocol buffer compiler가 service interface code와 stubs를 언어에 맞게 자동으로 생성해 줍니다.
service SearchService {
rpc Search(SearchRequest) returns (SearchResponse);
}JSON Mapping
Proto3는 JSON으로의 canonical encoding도 지원합니다. 이를 통해 보다 쉬운 시스템 간의 통신 구현이 가능합니다.
Proto와 JSON
Person이라는 객체를 만들고, 그 객체를 JSON 포맷으로 만든다고 해봅시다.(UTF-8 인코딩 가정시)
{
"userName":"Martin",
"favouriteNumber":1337,
"interests":["daydreaming","hacking"]
}데이터 크기를 보면 공백을 빼도 총 80byte를 사용했습니다. 그렇다면 Protocol Buffer를 사용했을 때는 다음 그림과 같습니다.
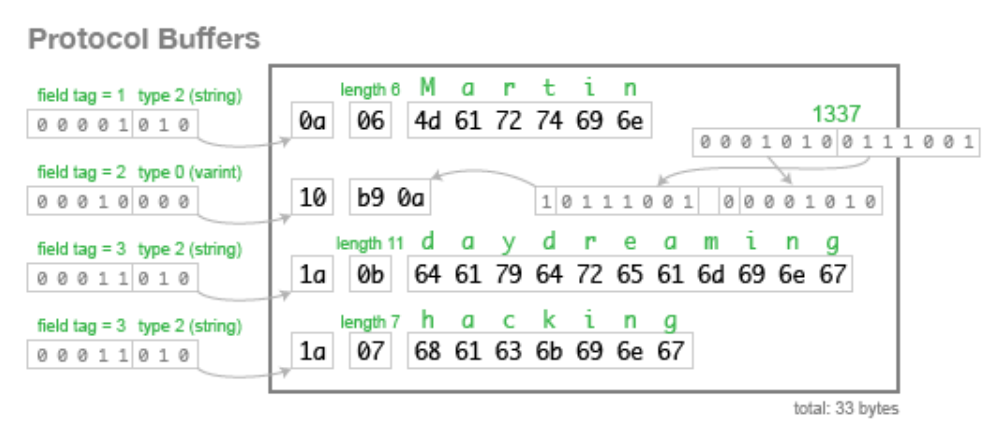
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}그림의 설명처럼 핵심은 userName과 같은 string을 field number로 대체한 것이 핵심 입니다. 따라서 proto를 이용해 데이터를 표현하게되면 같은 데이터여도 33byte만으로 표현할 수 있게 됩니다.
Proto의 장점
1. 통신이 빠름.
같은 데이터를 보낼시, 데이터의 크기가 작으니까 같은 시간에 더 많은 데이터를 보낼 수 있습니다.
2. 파싱을 할 필요가 없음
JSON 포맷으로 온 데이터를 다시 객체로 파싱해서 사용해야하지만, Protocol Buffer는 Byte Stream을 Proto file이 읽어 파싱할 필요 없습니다.
Proto의 단점
1. 인간이 읽기 불편함.
JSON 포맷의 경우, 사람이 읽기 편합니다. 반대로 protocol buffer가 쓴 데이터는 proto 파일이 없으면 아예 무슨 의미인지 모릅니다.이 문제 때문에 외부 API로 쓰이기에는 문제가 있습니다. (모든 클라이언트가 proto파일을 가지고 있어야 하기에)
그래서 내부 서비스간의 데이터 교환에서 주로 쓰입니다. (API Gateway를 이용해 REST API로 바꿔주는 방식도 존재)
2. proto 문법을 배워야 함
proto 파일 작성을 위한 문법을 배워야하며, proto파일을 한 번 정의했다 변경되면 proto파일을 쓰는 애플리케이션은 proto 파일이 다시 업데이트 되야한다는 단점이 있습니다.
'Programming Language > Go' 카테고리의 다른 글
| grpc 소개 (0) | 2022.11.15 |
|---|---|
| [go 모듈 소개 - 2. logrus] 더 자세한 로깅 모듈 (0) | 2022.11.15 |
| [go 모듈 소개 - 1. gorm] Golang을 위한 ORM 라이브러리 (0) | 2022.11.15 |