
캐시는 집합 S 당 캐시 라인의 수 E에 의해 서로 다른 클래스로 구분된다. 집합 당 정확히 1개의 라인을 갖는 경(E = 1)는 직접 매핑 캐시라고 알려져 있다. 직접매핑 캐시는 가장 이해하기 쉽고 구현하기 쉬워서 이 캐시를 사용해서 캐시가 동작하는 방법에 대한 일반적인 개념들을 설명하고자 한다.
우리에게 CPU, 레지스터 파일, L1 캐시, 메인 메모리를 갖는 시스템이 주어졌다고 하자. CPU가 메모리 워드 w를 읽는 인스트럭션을 실행할 때, 이 워드를 L1 캐시에서 요청한다. 만일 L1 캐시가 w의 복사본을 가지고 있다면 L1 캐시 적중이 되고, 캐시는 빠르게 w를 뽑아내서 CPU로 보낸다.
반대로 캐시 미스가 발생한다면 CPU는 L1 캐시가 메인 메모리로부터 w를 포함하고 있는 블록의 사본을 요청하는 동안 기다려야 한다. 요청한 블록이 메모리에서 도착하게 되면, L1 캐시는 이 블록을 자신의 캐시 라인 한 개에 저장하고 w를 추출해서 CPU로 보낸다. 캐시가 어떤 요청이 적중인지 미스인지 결정하고, 요청한 워드를 뽑아내기 위해 수행하는 작업은 다음 세 단계로 이뤄진다.
(1) 집합을 선택한다.
(2) 라인을 매칭한다.
(3) 워드를 추출한다.
직접 매핑 캐시에서 집합 선택
이 단계에서 캐시는 s개의 집합 인덱스 비트를 w 주소 중에서 뽑아낸다. 이 비트들은 집합 번호에 대응하는 비부호형 정수로 해석된다. 바꿔말하면, 만약 캐시를 집합들의 일차원 배열로 생각할 경우 집합 인덱스 비트들은 해당 배열의 인덱스를 구성한다고 생각할 수 있다.

위의 그림에서는 어떻게 집합이 선택되는지를 결정할 수 있다. 해당 그림에서는 000012의 값을 갖는 집합 인덱스 비트가 집합 1을 선택하는 정수 인덱스로 해석되는 것을 시각화하였다.
직접 매핑 캐시에서 라인 매칭
전 단계에서 집합 i를 선택했으므로, 다음 단계는 워드 w의 사본이 집합 i에 포함된 캐시 라인에 들어 있는지를 결정하는 것이다. 직접 매핑 캐시에서 집합 당 한 개의 라인만 있기 때문에, 이 작업은 쉽고 빠르게 할 수 있다. w의 사본은 유효비트가 설정되어 있고, 캐시 라인의 태그가 w의 주소에 잇는 태그와 일치하기만 한다면 사본이 해당 라인에 들어 있게 된다.

위의 그림에서는 직접 매핑 캐시에서 어떻게 라인 매칭이 작동하는지를 보여준다. 해당 예제에서는 직접 매핑 캐시를 사용하기에 각 집합 당 정확히 한 개의 라인만이 존재하게 된다.이 라인의 유효비트 valid가 1이고 이를 통해 태그와 블록의 비트들이 유효하다는 것을 알 수 있다. 캐시 라인의 태그 비트들이 주소의 태그비트들과 일치하기 때문에, 우리가 원하는 워드의 사본이 실제로 이 라인에 저장되어 있다는 것을 알 수 있다. 바꿔 말해 캐시가 적중되었다. 반면, 만일 유효 비트가 0이거나 태그가 일치하지 않는다면 캐시가 미스되었다는 응답을 받게 될 것이다.
캐시의 적중 여부는 Tag bits와 Valid bit을 보고 판단할 수 있다. (Block offset의 쓰임새는 그 이후이다)
직접 매핑에서 워드의 선택
일단 캐시 적중이 발생하면 w가 블록 내 어딘가에 있다는 것을 알게 된다. 마지막 단계는 원하는 워드가 블록 내 어디에서 시작하는지를 결정하는 것이다. 앞선 그림 2에서 나타난 것처럼, 블록 오프셋 비트는 원하는 워드의 첫 바이트 오프셋을 제공한다. 캐시를 라인들의 배열로 보는 방식을 다시 적용하면 블록을 바이트의 배열로 생각할 수 있으며, 바이트 오프셋은 배열 내 인덱스로 볼 수 있다. 예제에서 블록 오프셋 비트 1002는 사본이 블록 내 4번째 바이트에서 시작한다는 것을 나타낸다. (이때 워드의 길이는 4바이트라고 가정한다.)
미스 발생 시 라인의 교체
만일 캐시가 미스하면, 요청한 블록을 메모리 계층 구조 내 다음 레벨에서 가져와서 새 블록을 집합 인덱스 비트가 지시하는 집합의 캐시 라인 중 하나에 저장할 필요가 있다. 일반적으로 만일 이 집합이 유효한 캐시 라인들로 꽉 차 있다면, 기존 라인 중에 하나를 제거해야 한다. 각 집합이 정확히 한 개의 라인을 포함하고 있는 직접 매핑 캐시에서, 교체 정책replacement policy은 매우 단순하다.
: 현재 라인을 새롭게 선언한 라인으로 교체한다.
종합: 직접 매핑 캐시의 동작
캐시가 집합을 선택하고 라인을 식별하기 위해 사용하는 매커니즘은 상당히 간단하다. 그 이유는 하드웨어가 이들을 이들을 몇 나노초 내에 수행해야 하기 때문이다. 그러나 비트들을 이처럼 다루는 것은 사람에게 있어서는 다소 혼동을 가져올 수 있다. 실제 예제를 사용하면 이 작업을 명확하게 이해할 수 있다. 우리에게 다음과 같은 직접 매핑 캐시가 주어졌다고 하자.
(S, E, B, M) = (4, 1 , 2, 4)
다른 말로 설명하면 이 캐시는 4개의 집합, 집합 당 1개의 라인, 블록 당 2바이트, 4비트의 주소를 갖는다. 이와 별개로 각 워드는 1개의 바이트로 이뤄져 있다고 가정해보자. 물론 가정이 다소 비현실적이지만, 간단한 예제를 구성할 수 있다.

캐시에 대해서 학습할 때, 위의 그림 3에서 보인 것처럼, 전체 주소 공간을 모두 나열하고 비트들을 분리하는 것은 매우 바람직하다. 위의 그림에서 주요한 몇 가지 포인트들에 집중하여 살펴보자.
- Tag bits와 Index bits를 합치면 메모리 내의 각 블록을 유일하게 지정할 수 있게 된다. 예를 들어 블록 0는 주소 0과 1로 구성되며, 블록 1은 주소 2와 3, 블록 2는 주소 4와 5와 같은 방식이다.
- 총 8개의 메모리 블록이 있지만, 4개의 캐시 집합만 존재하므로, 여러 블록이 동일한 캐시 집합에 대응된다 (즉, 이들은 동일한 집합 인덱스를 갖는다). 예를 들어 블록 0과 4는 모두 집합 0에, 블록 1과 5는 모두 집합 1에 대응된다.
- 동일한 캐시 집합에 대응되는 블록들은 태그를 사용해서 유일하게 구별된다. 예를 들어 블록 0은 Tag bits 0, 블록 4는 Tag bits 1, 블록 1은 Tag bits 0을 가지며 블록 5는 Tag bits 1을 가진다.
CPU가 연속된 읽기 작업을 수행할 때 캐시의 동작을 시뮬레이션 해보자. 이 예제에서는 CPU가 1바이트 워드를 읽는 것을 가정한다.

초기에 캐시는 비어 있다. (즉, 각 유효비트는 0이다.)
표의 각 행은 캐시 라인을 나타낸다. 첫 번째 열은 라인이 속한 집합을 나타내지만, 이는 이해를 돕기 위해 추가적으로 붙어있을 뿐 실제 캐시에는 포함되지 않는 정보이다. 다음 4 개의 열은 실제 캐시 라인의 비트를 나타낸다.
이제 CPU가 일련의 읽기 작업을 수행할 때 어떤 일이 발생하는지를 살펴보자. (그림 3에서 계속 이어진다)
1. 주소 0에서 워드를 읽는다.
집합 0에 대한 유효비트가 0이기 때문에 이는 캐시 미스이다. 캐시는 메모리에서 블록 0을 선입해오고 (또는 그 하위 캐시로부터), 이 블록을 집합 0에 저장한다. 그리고 나서, 캐시는 m[0](메모리 0에 있는 내용)을 새로 선입한 캐시 라인의 block[0]에서 리턴해준다.

2. 주소 1에서 워드를 읽는다.
앞서 주소 0에서 워드를 읽으려던 시도로 인해 m[1]이 캐시 집합 0에 들어와 있는 상태이다. 현재 주소 1은 s index bits가 002이고 이를 통해 Set 0을 의미하는 것을 알게 된 상태이다. 이때, 유효 비트가 1이고 태그도 일치하기 때문에 사본이 존재한다는 것을 알게 된다.
결론적으로 b offset bits가 1이므로 해당하는 캐시 라인의 block[1]임을 알고 이를 리턴하게 되며 캐시 적중 상태이다. 캐시 상태의 변화는 없다.
3. 주소 13에서 워드를 읽는다.
주소 13의 s index bits는 10이다. 해당 캐시 집합에 접근하여 캐시 라인의 Valid 비트를 검사한다. 이때 유효하지 않으므로 이는 캐시 미스이다. 캐시는 해당 주소가 가져야 하는 블록 6번에 대한 데이터를 캐시 집합 2에 로드하고, 로드 이후 새 캐시 라인의 block[1]로부터 m[13]을 CPU에게 리턴하게 된다.

4. 주소 8에서 워드를 읽는다.
주소 8의 s index bits는 002이다. 앞서 주소 0을 읽으면서 해당 캐시 라인은 채워진 상태임을 기억하자.
해당 캐시 집합에 접근하는 경우, 먼저 유효 비트와 Tag 비트를 검사한다. 이때 유효 비트는 1이지만, 주소 8에게 기대되는 Tag 비트는 1인 것과 달리 캐시에는 0이 기록되어 있다. 이는 캐시 미스이다.
캐시는 블록 4를 메모리로부터 가져와 캐시 집합 0에 로드한다.
이때 주소 8의 b offset bits는 02이므로 새로운 캐시 라인의 block[0]을 리턴하여 CPU 혹은 상위 저장 장치 캐시에 전달한다.
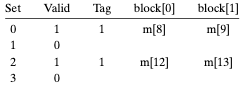
5. 주소 0에서 워드를 읽는다.
이때 다시 주소 0에서 워드 데이터를 읽는다면 다시 캐시 미스가 발생한다. 그 이유는 우리가 방금 주소 8을 참조하는 동안에 블록 0을 교체했기 때문이다. 캐시에는 여전히 공간이 많이 남아있지만 동일한 집합으로 매핑하는 블록들로 번갈아서 참조를 하는 이런 종류의 미스는 충돌 미스conflict miss의 한 예가 된다.

직접 매핑 캐시에서의 충돌 미스
충돌 미스는 실제 프로그램에서 일반적인 현상이며 어려운 성능 문제를 야기한다. 직접 매핑 캐시에서 충돌 미스는 일반적으로 프로그램들이 크기가 2의 제곱인 배열에 접근할 때 발생한다. 예를 들어 두 벡터의 내적을 계산하는 함수를 생각해보자.
float dotplot(float x[8], float y[8]) {
float sum = 0.0;
for (int i = 0; i < 8; i++)
sum += x[i] * y[i];
return sum;
}이 함수는 x와 y에 대해서 좋은 공간 지역성을 지님과 동시에 많은 캐시 적중이 가능하다고 기대할 지도 모르지만, 실제로는 충돌 미스가 발생할 가능성이 존재하는 코드이다.
Float은 4 바이트이고, x가 주소 0부터 시작하여 연속적인 32 바이트에 로드되어 있으며, y는 주소 32부터 x에 이어서 곧바로 시작한다고 가정하자. 간단하게 하기 위해 한 개의 블록은 16바이트이고 (4 개의 float을 저장할 수 있는), 캐시는 두 개의 집합을 가지고, 전체 캐시 크기는 32 바이트라고 가정한다. 변수 sum이 실제로는 CPU 레지스터에 저장될 것이며, 따라서 메모리 참조는 이뤄지지 않는다고 가정한다. 이러한 가정들 하에 각 x[i]와 y[i]는 동일한 캐시 집합에 매핑될 것이다:
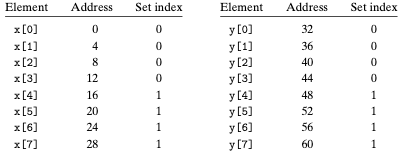
실행될 경우, 첫 번째 루프의 실행에서 x[0]을 참조하면 캐시 미스가 발생한다. 앞서 언급하였듯 한 블록의 크기는 16 바이트이므로, x[0]-x[3]을 포함하는 블록이 집합 0에 로드된다. 다음 참조는 y[0]인데 다시 미스가 되고, y[0]-y[3]을 포함하는 블록을 집합 0으로 복사하게 되는데, 이 과정에서 이전 참조에 의해 복사된 x의 값들이 지워진다. 다음 반복실행 동안에 x[1]에 대한 참조가 다시 미스가 되고, x[0]-x[3]에 해당하는 블록이 집합 0에 로드되고 y[0]-y[3] 블록은 지워진다. 따라서 우리는 충돌 미스를 갖게되며, 향후 발생하는 x와 y에 대한 모든 참조들은 블록 x와 y를 왔다갔다하며 thrash하는 충돌 미스를 발생시키게 된다. Thrashing은 캐시가 같은 집합의 캐시 블록들을 로드하고 축출하는 것을 반복하는 것을 의미한다.
다행히, thrashing은 일단 프로그래머가 무슨 일이 벌어지고 있는지를 인식한다면 수정이 그나마 용이하다. 한가지 해결책은 각 배열의 마지막에 B바이트의 패딩을 붙이는 것이다. 예를 들어 x를 float x[8]로 정의하는 대신 float x[12]로 정의한다. y가 메모리에서 x 바로 뒤에 시작한다고 가정하면 배여의 원소들이 집합에 다음과 같이 대응된다.
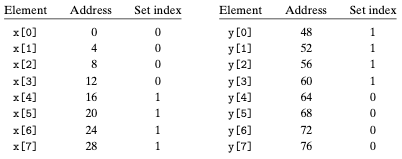
위의 그림에서는 x의 끝부분에 의도적으로 패딩을 넣어주어 x[i]와 y[i]가 서로 다른 집합에 매핑될 수 있도록 프로그래머가 조작을 가한 상황이다. 이를 통해 thrashing 충돌미스를 제거할 수 있다.
'CS' 카테고리의 다른 글
| Write 관련 캐시 이슈 (0) | 2022.11.29 |
|---|---|
| Set Associative Cache (집합결합성 캐시) (0) | 2022.11.28 |
| 기본 cache memory 구조 (0) | 2022.11.28 |
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
| Cache Memory 소개 (0) | 2022.11.28 |