
SageMaker Data Wrangler flow

이 중에서 New data flow 선택
로딩이 끝나고 나면, 기본값으로 Source와 함께 Transform이라는 항목이 보인다.
이때 활용하는 서비스는 Sagemaker 내의 Data Wrangler인데, Data Wrangler의 경우 미니멈으로 vCPU를 16개 RAM을 64GB나 사용하기 때문에 비용 정보에 신속하게 대응할 수 있어야 하고, 혹시나 켜놓고 놔두는 불상사가 발생하지 않도록 하자.
AWS에서 제공하는 Sample 소스를 추가하였다. 데이터는 타이타닉의 탑승자에 대한 정보이다.
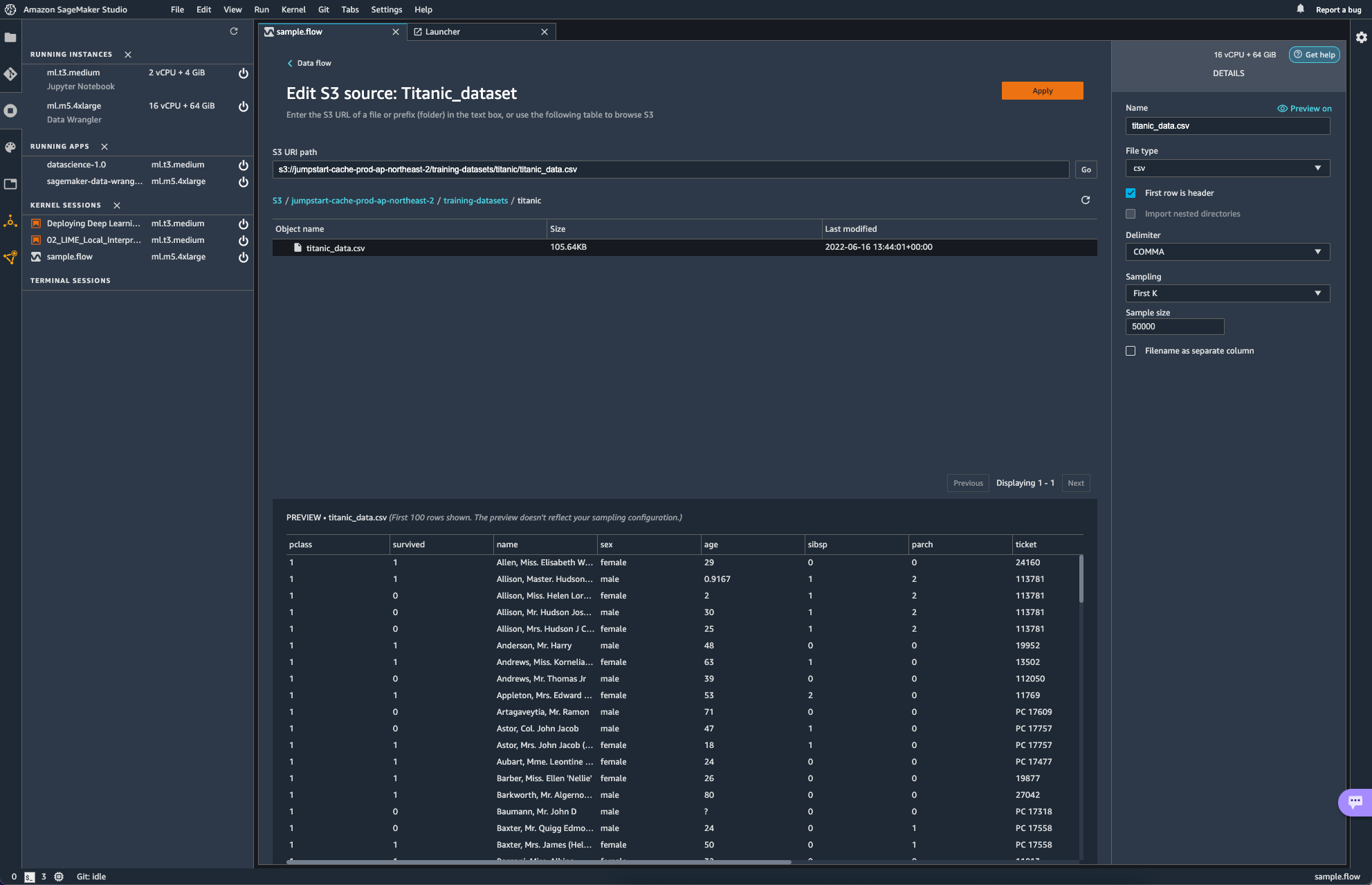
source를 edit하게 되면, 다음과 같은 화면이 보인다.
S3 URL을 통해 source를 지정하는 형식이다. Data Wrangler에서 유저는 파일 형식과, delimiter, 샘플링 방식과 크기를 지정해주게 된다.
이 외에도 쿼리 질의를 통해 데이터를 가져올 수 있는 Athena로부터도 데이터를 가져올 수 있다고 한다. snowflake로부터도 가져올 수 있다고 하는데, snowflake 사의 서비스를 아직 써본 경험이 없어 일단은 넘어가고자 한다.
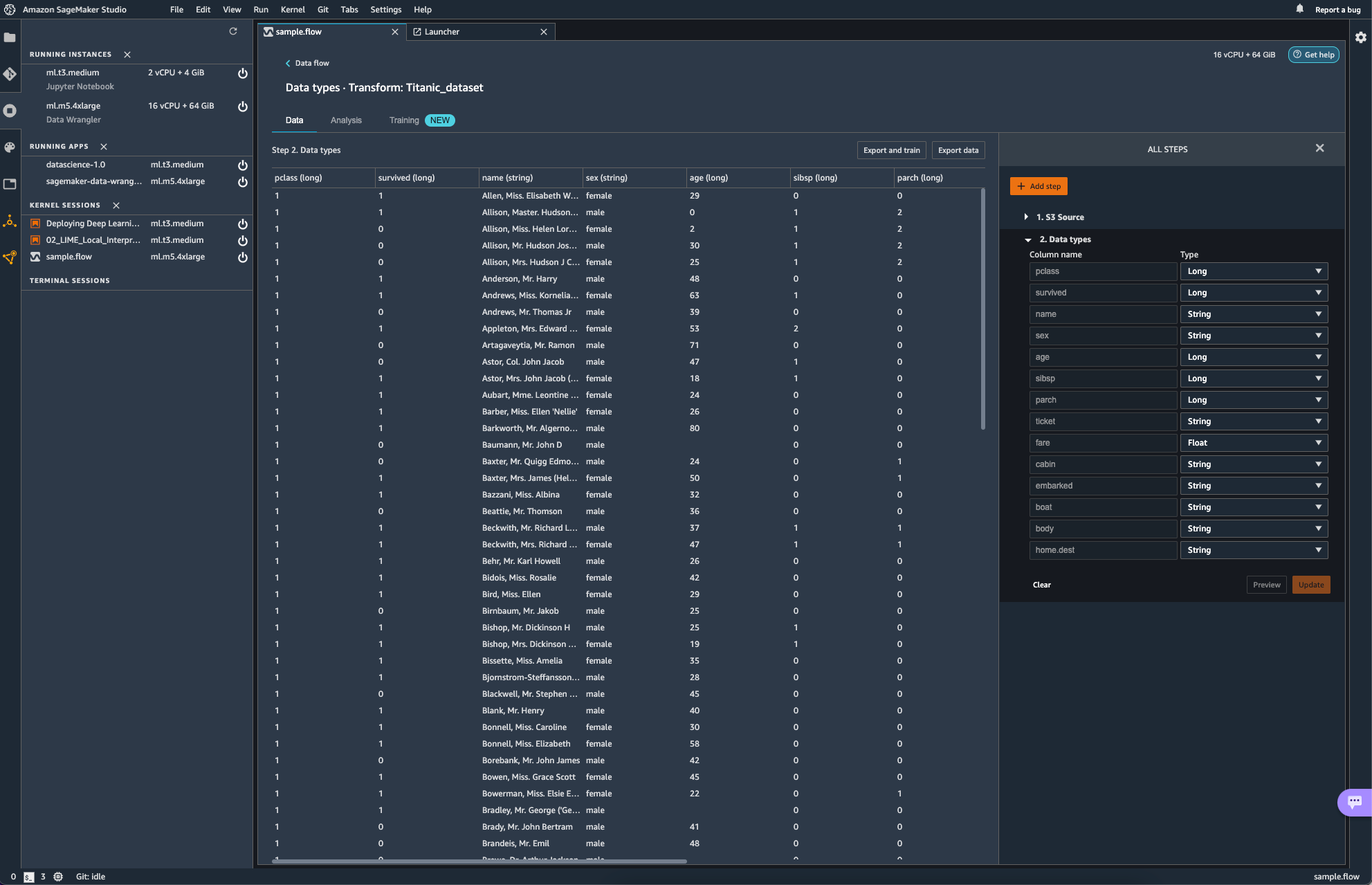
이미지 속에서는 작업은 Glue Studio에서 수행할 수 있는 ApplyMapping과 같은 역할을 수행한다. 일단은 신경 쓸 필요도 없이 자동으로 Mapping 되었다.
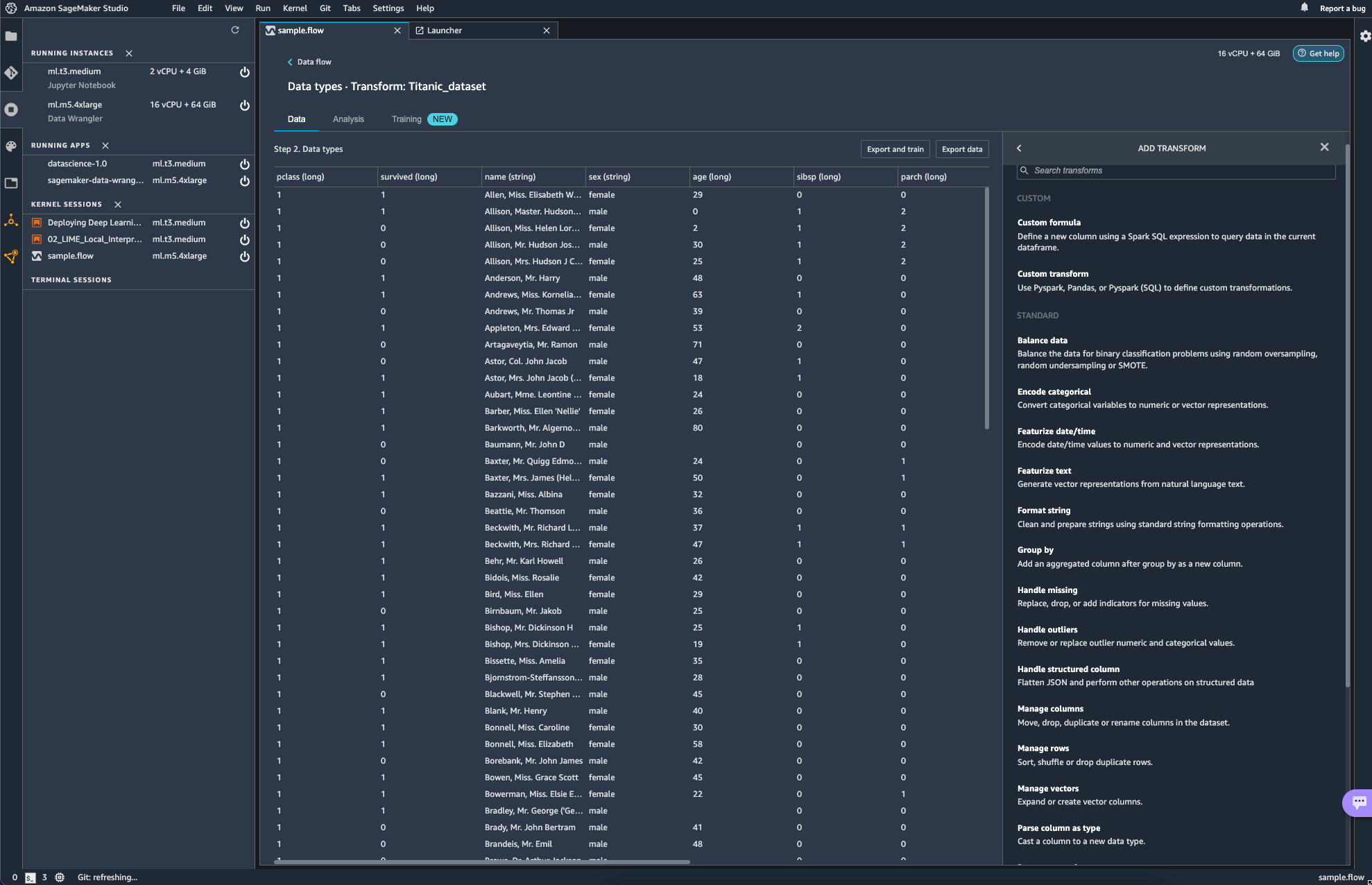
add step을 선택해보면 다양한 transform 작업들이 보인다. 해당하는 작업들이
transform에서는 glue studio에서 transform으로 적용할 수 있었던 항목들이 그대로 보여지는 듯 하다.
다만 이제 Glue에서 transform 했던 작업들의 성격이 ETL 측면에서의 transform의 느낌이였다면, sagemaker에서는 분석 직전에 데이터를 preprocessing하는 측면이라고 생각하면 되지 싶다.
Analysis를 통해 간단한 분석도 가능하다.
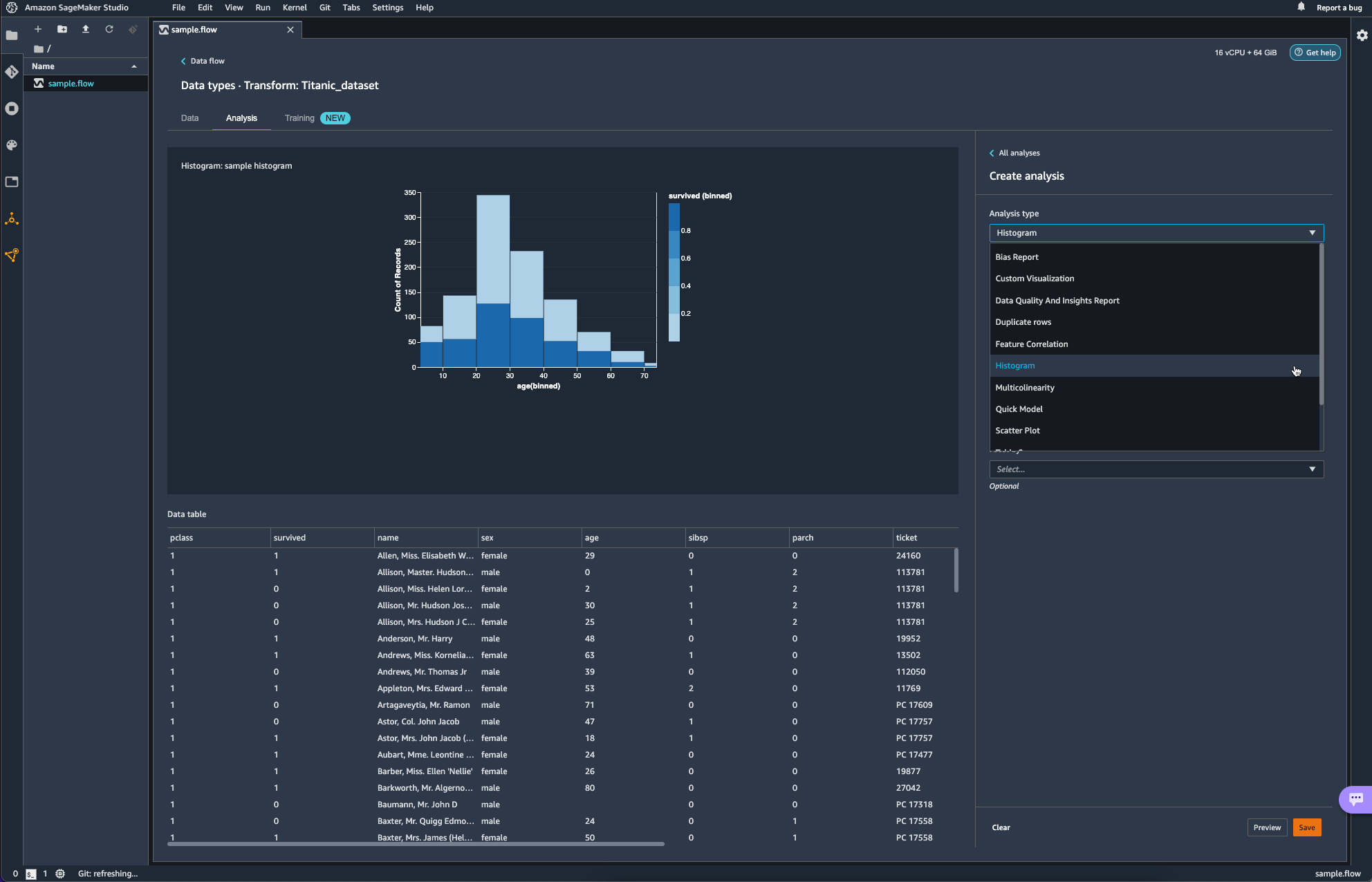
아래 항목은 Data Wrangler를 활용해 bias를 분석하는 작업이다. 타이타닉의 생존 여부(survived)를 target column으로 age에 대한 bias를 분석해보았다.
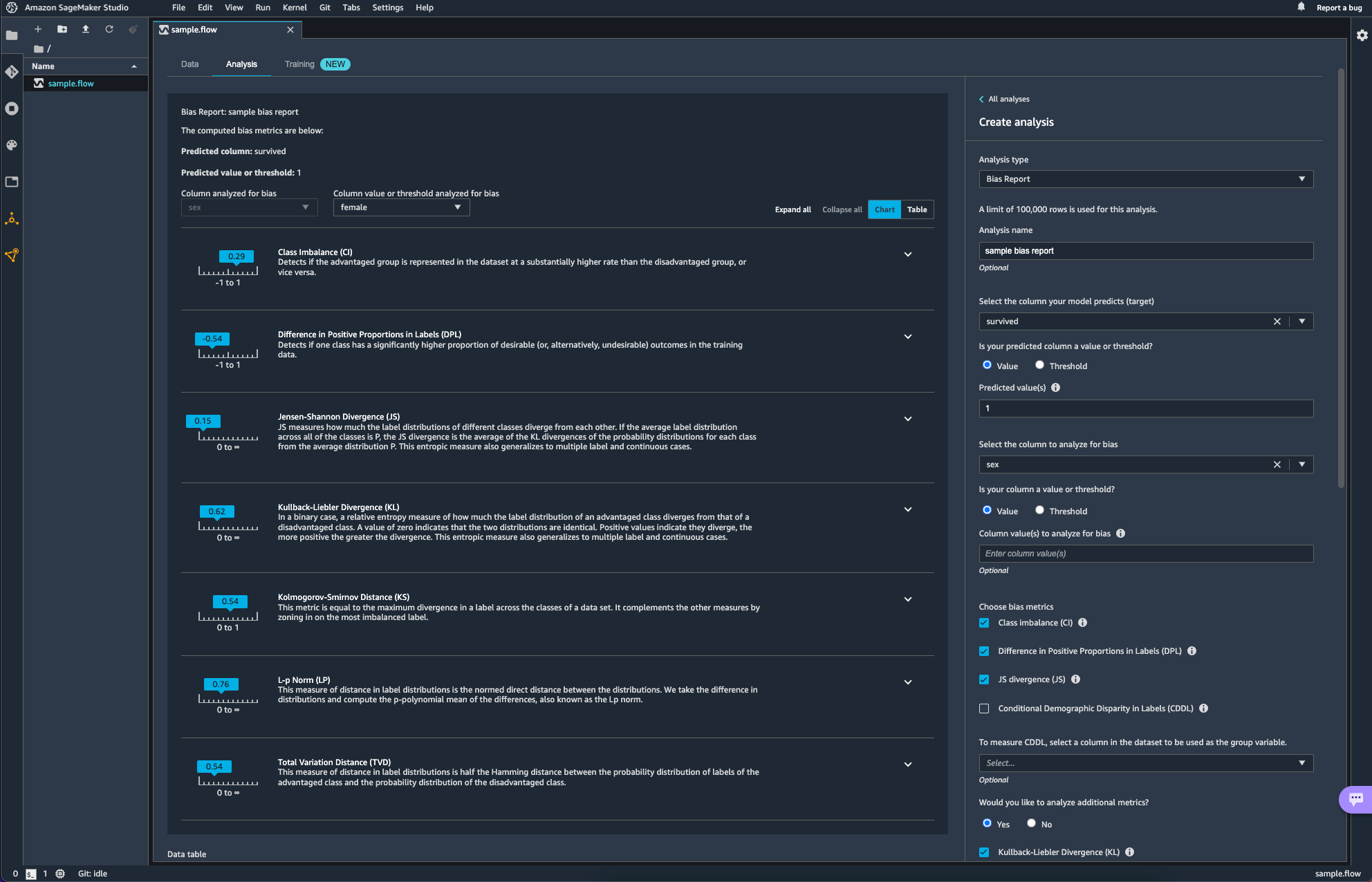
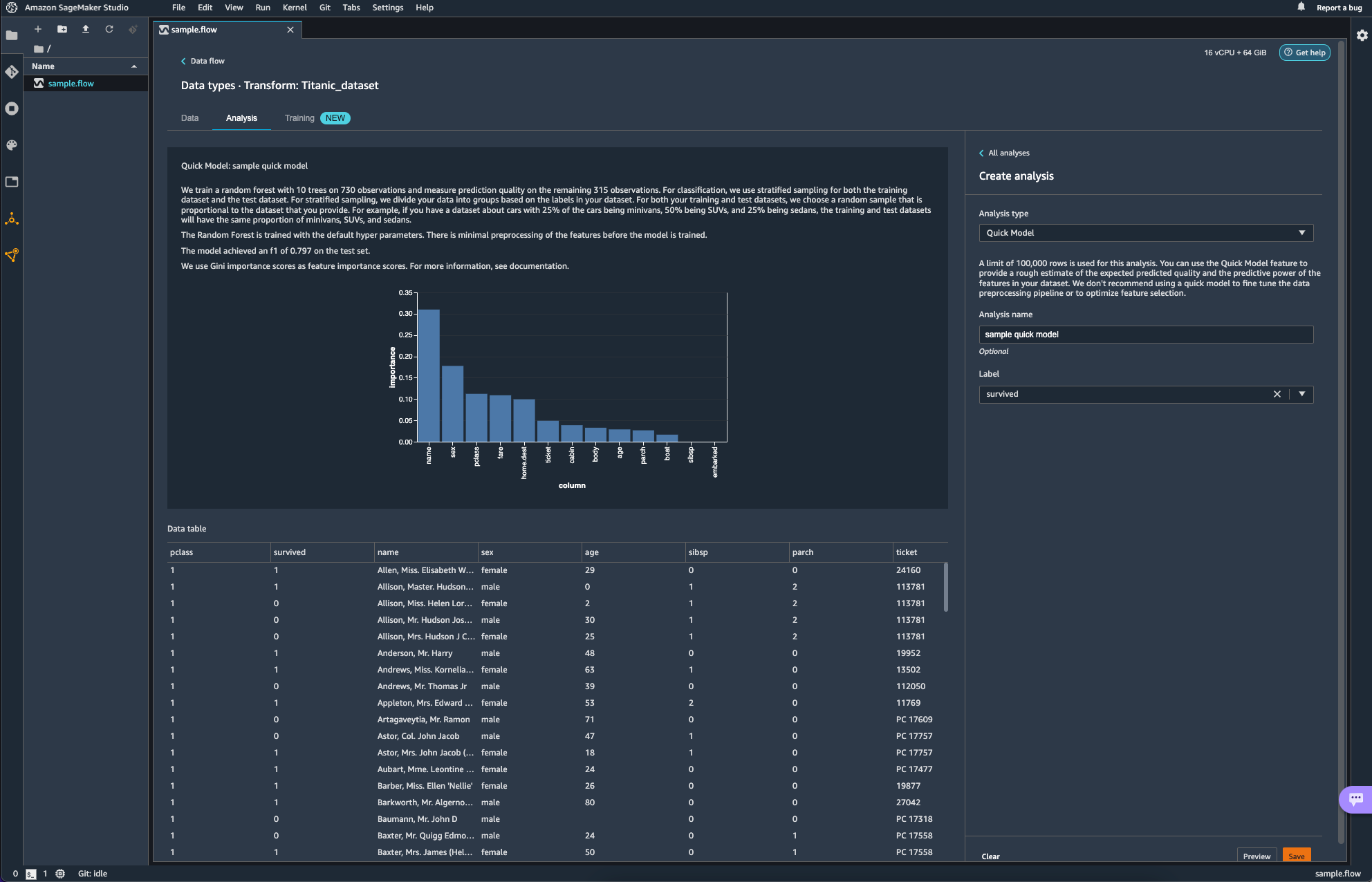
Quick Model이라는 항목도 있다. 빠르게 모델을 학습시켜 feature의 Importance를 매우 rough하게 보여주는 것 같다. 설명에도 쓰여있듯 fine tuning이나 feature selection optimization에도 활용하는 것을 추천하지는 않는다고 하니 대략적인 흐름을 잡는데에만 활용하면 될 듯하다.
위에 New라는 태그가 붙어있는 Training 항목의 경우, 사용하는 방법도 생소하고 AWS의 새로운 서비스를 활용해보려다 비용 폭탄을 맞은 경험이 있어 일단은 넘어가기로 하자. 나중에 조금 더 유명해지면 그때 가서 다시 살펴봐도 늦지 않을 듯 하다.
비용 폭탄이 발생하였던 서비스는 Canvas 라는 서비스이다. 심지어 서울 리전에는 서비스가 아직 제공되지 않아 도쿄 리전에서 실행해봤는데, codeless 한 ML/DL을 제공한다길래 눌렀더니, 아무것도 안해도 Launch App 클릭 한번에 비용이 계속 나가 3일에 대략 20만원 비스무리하게 나갔던 거 같다. 비용은 약간의 과장이 있을 수 있지만 그 비스무리하게 충격적이였다 ... ㅎ
파이프라인의 마무리 작업으로 S3 bucket에 업로드를 하며 data flow 쪽에서의 작업을 마무리하였다.
Destination이 추가된 모습이다.
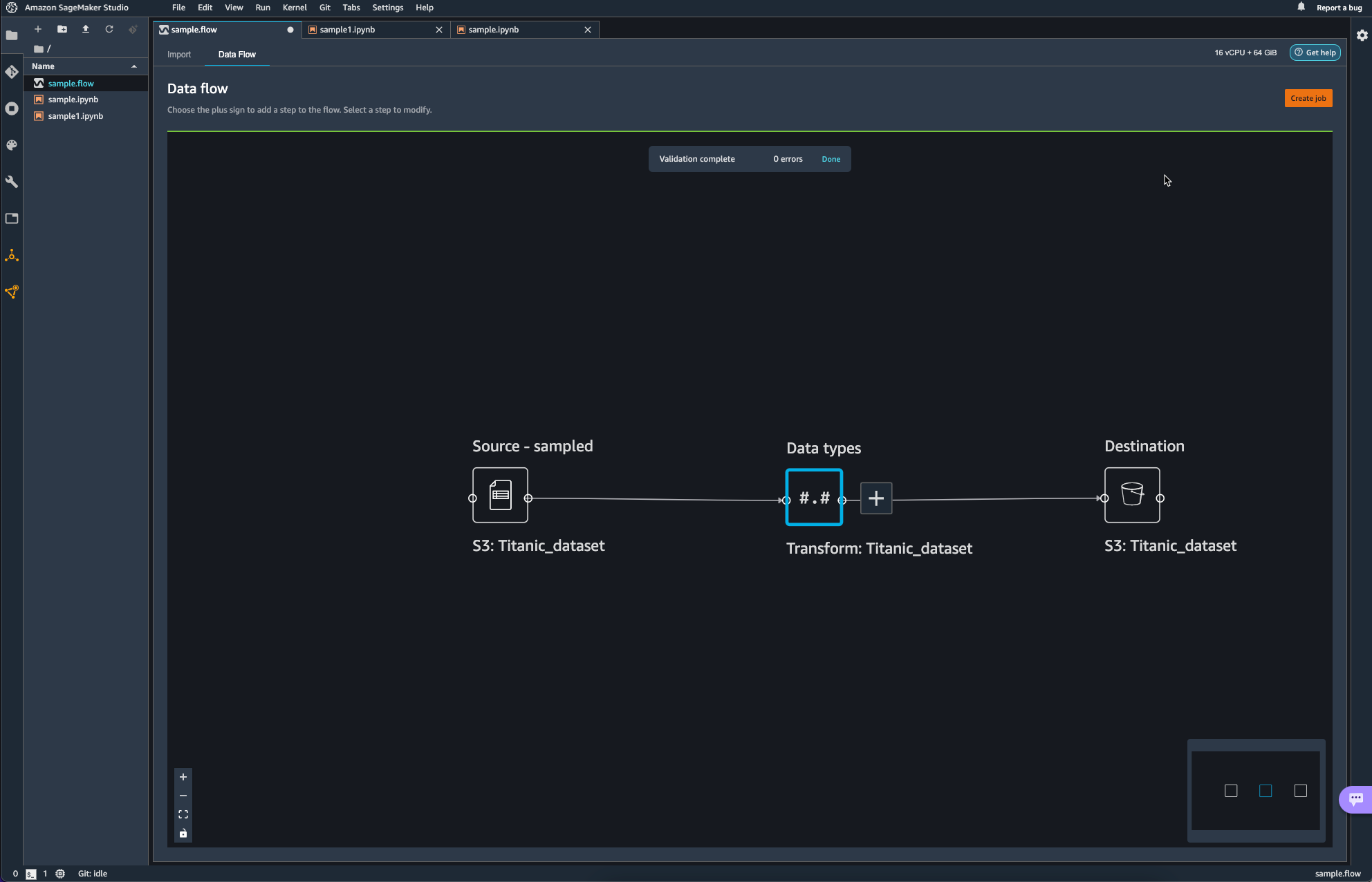
이제 Job을 생성하여 방금까지 생성하였던 Pipeline에 대해서 실제 작업이 일어나도록 해야한다.
오른쪽 상단의 Create Job을 통해 Pipeline Job을 Configure 한다.
이때 인스턴스는 여전히 ml.x5.4xlarge를 사용하는데, default는 2개를 사용하도록 되어 있다.
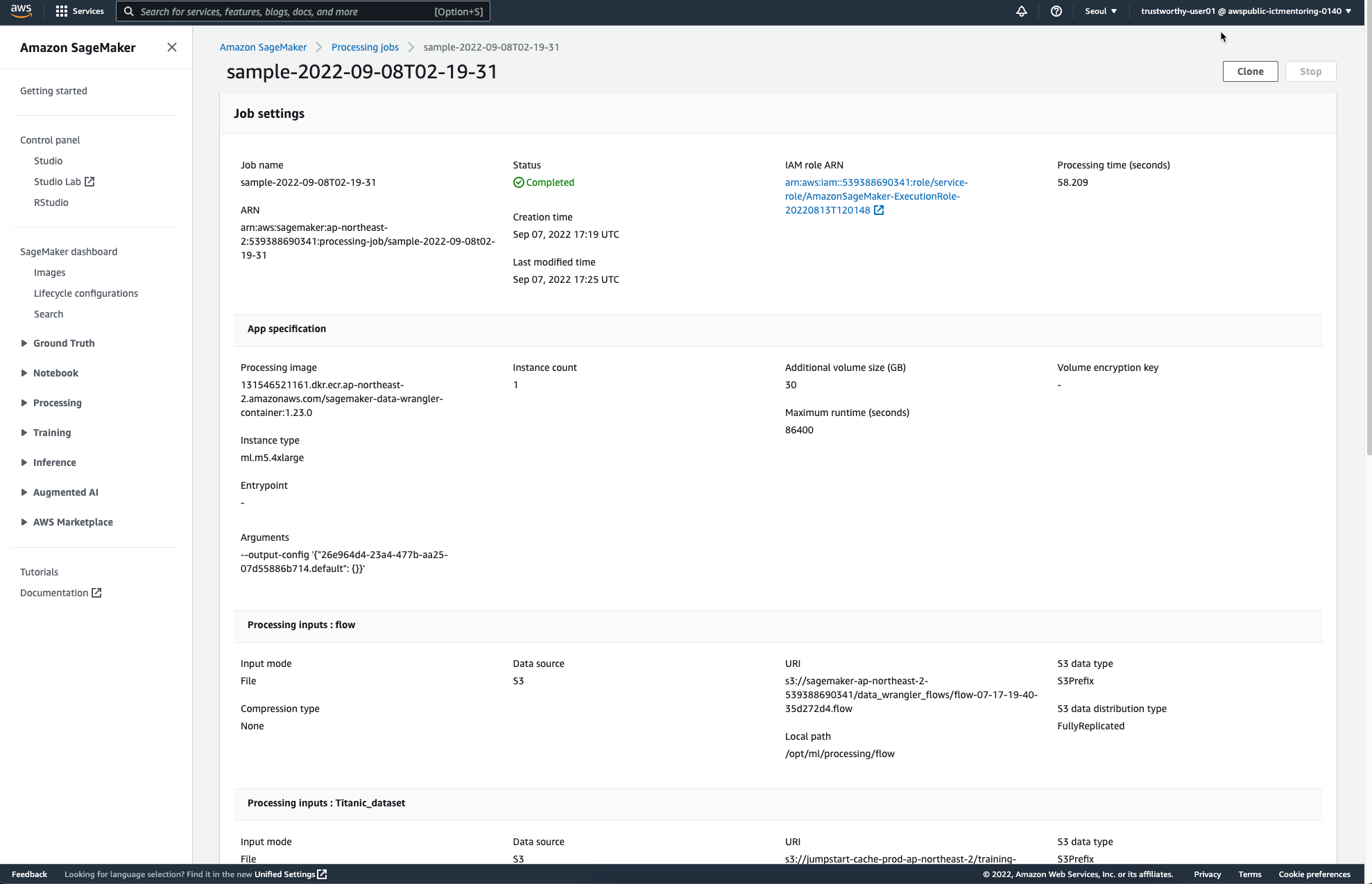
작업이 완료되면 다음과 같은 페이지를 통해 Completed를 안내받을 수 있다.
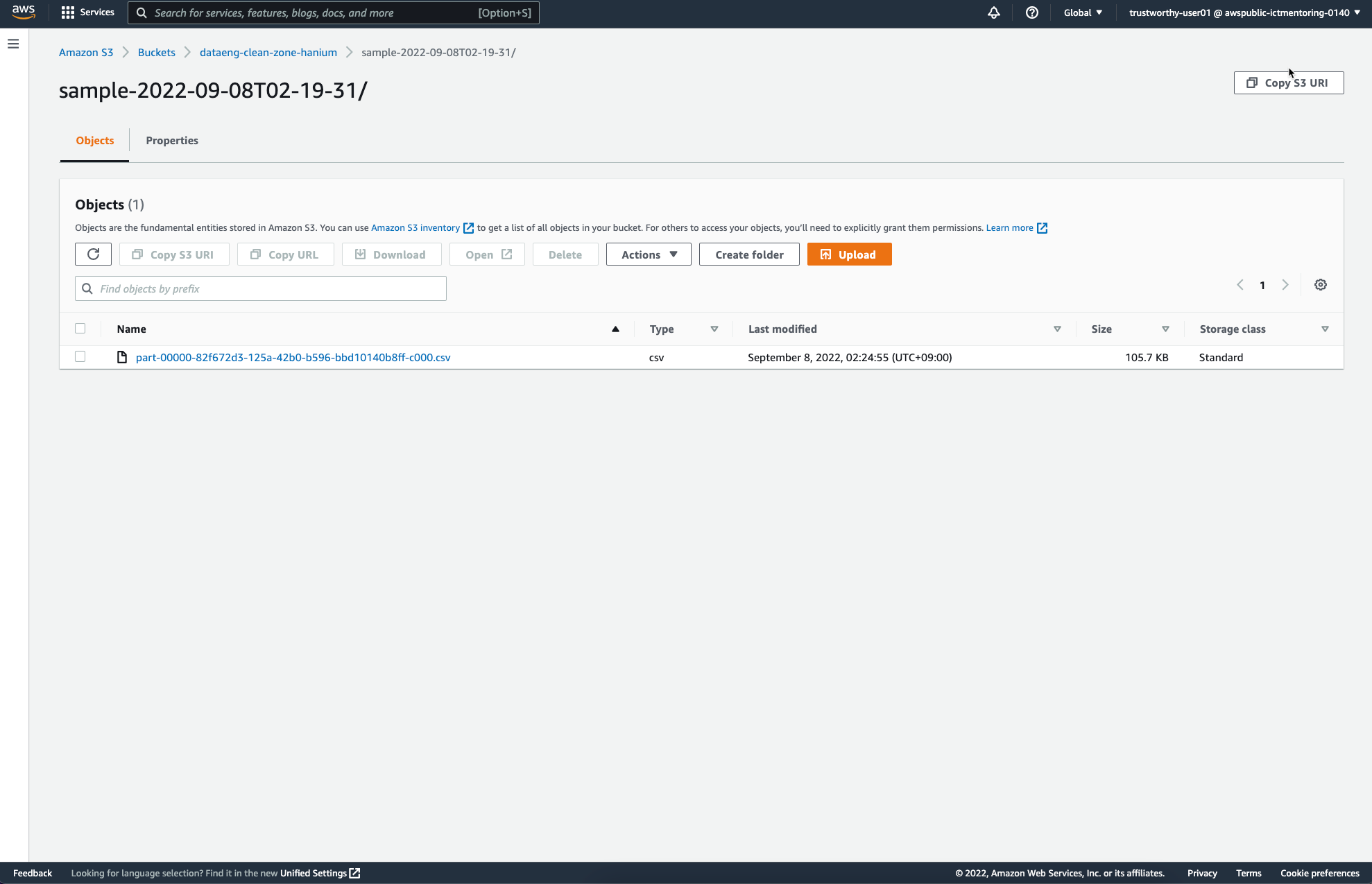
앞서 Job Configure를 통해 설정하였던 S3 Destination에는 다음과 같은 파일이 추가되었다.
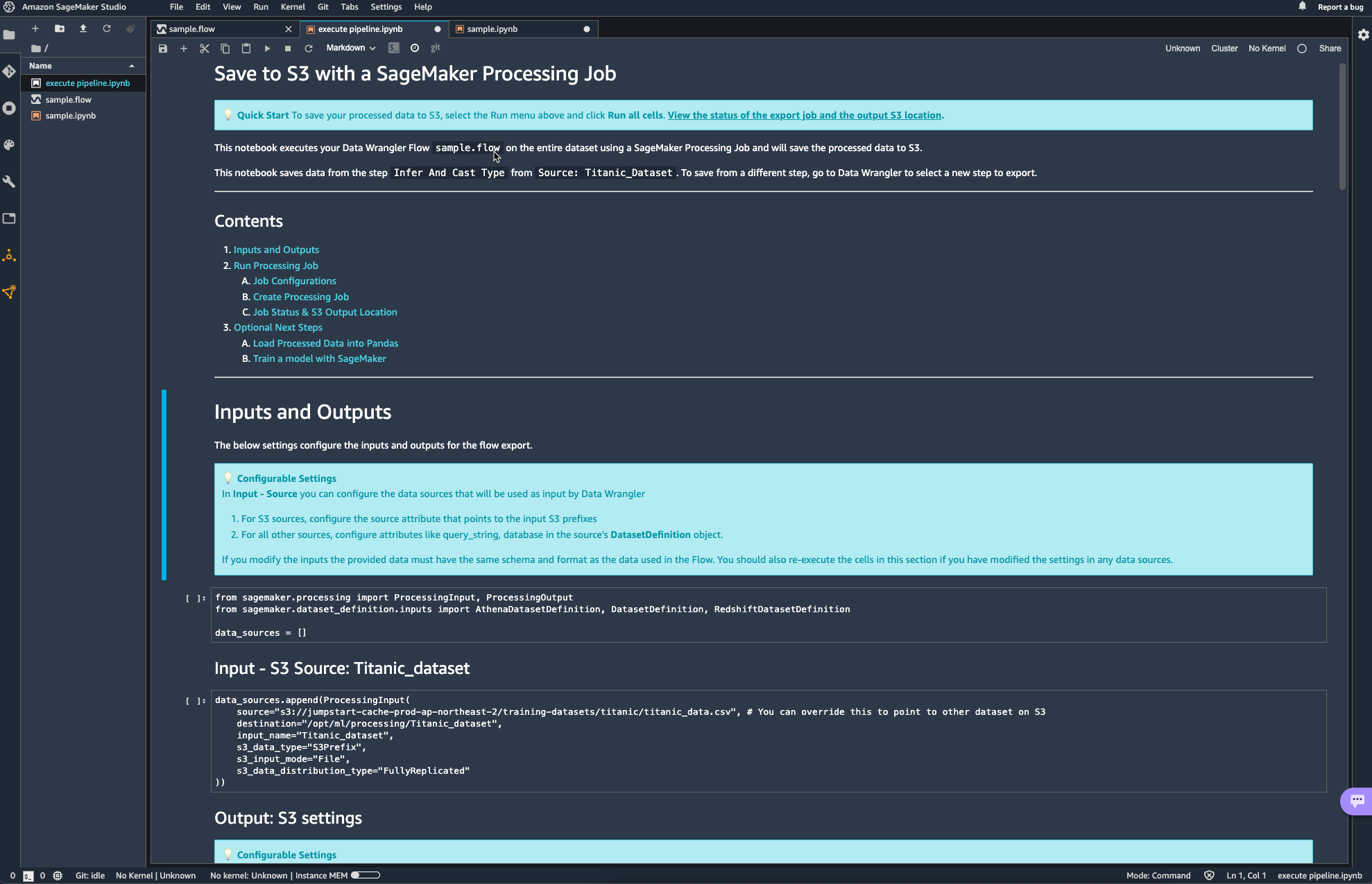
이 외에도 ipynb 노트북을 활용해서도 Data Wrangler flow를 실행할 수 있는데, 이때 자동으로 생성되는 노트북은 거의 대부분의 설정이 이미 되어있어 그냥 실행만 해도 되고, 버킷의 이름과 같은 사소한 정보들만 변경해주면 될 거 같다.
'DevOps > Cloud Service' 카테고리의 다른 글
| [Boto3] S3 bucket 생성 (0) | 2022.09.07 |
|---|---|
| [Boto3] S3 bucket 나열 (0) | 2022.09.07 |
| awscli 1.25.17 requires botocore==1.27.17, but you have botocore 1.27.66 which is incompatible. (0) | 2022.09.06 |
| [네이버 클라우드] 서버 생성 및 접근 (0) | 2022.05.28 |