
해당 글은 공룡책이라고 불리우는 Operation Systems Concepts를 기반으로 한다.
Chapter 1 Introduction
해당 챕터에서는 우리가 배우게 되는 OS가 정확히 무엇을 의미하는지를 설명함과 동시에 앞으로 배우게 될 내용들을 하나씩 가볍게 소개한다. Chapter 1의 경우 개인적으로 무겁게 마음의 준비를 하면서 보기보단 조금 내려놓고 이러이러한 내용들을 배운다 정도로만 알아도 괜찮다고 생각한다. 분명 Introduction이라고 써놨지만, 무겁게 읽다보면 Intro가 아니라 한참을 씨름하다 Chapter 1의 벽에 가로막혀 소위 시작부터 막혀버리는 불상사가 충분히 생길 수 있을 것 같다. 마음을 편하게 가지고 꾸준히 읽어 나가다보면 이후의 챕터에서 나오는 다시 등장하는 내용들이 많으니 너무 급하게 생각하지 말자.
1.1 What Operating Systems Do
세상에는 다양한 OS가 존재한다. PC하면 떠오르게 되는 WINDOW, 스타벅스 출입증과 같은 맥 OS, 쓰면 컴퓨터 엄청 잘해보이는 리눅스와 그 다양한 버전들 ... 해당 섹션의 주제는 그렇다면 우리가 OS라고 부르는 것들의 정의가 무엇이고 우리는 OS를 왜 쓰게 되는지이다. OS는 다양하다. 때문에 각각의 OS가 가지는 특성이 다르며, OS는 이를 만드는 이들과 설계하는 자들에 의해 다양한 형태로 표현된다. 때문에 모든 OS를 아우르는 공통된 정의를 말하기가 굉장히 조심스러워진다.
다만, OS라 함은 적어도 이 두 가지의 역할은 적어도 수행할 수 있어야 한다.
- 컴퓨터의 하드웨어를 제어할 수 있어야 한다.
- 프로그램의 실행을 제어할 수 있어야 한다.
동시에 OS는 프로그램이다. 때문에 우리는 OS를 다음과 같이 정의할 수 있겠다.
An operating system is a program that manages the computer hardware and also that controls the execution of programs
이때 주의해야할 용어가 있는데, 바로 execution of programs라는 표현이다. 뒤에서 다시 등장하겠지만, 우리가 프로그램을 실행한다는에는 표현에는 두 가지 해석이 가능하다.
- Execute the program
- Run the Program
해당 차이를 이해하기 위해서는 프로그램과 프로세스를 이해할 필요가 있다.
먼저, 프로그램이라고 함은 한마디로 말하자면 실행 가능한 파일을 의미한다. 핵심은 실행이 가능할 뿐, 실행 여부는 중요하지 않다는 것이다. 더 투박하게 표현하자면 일종의 실행 가능한 코드 덩어리를 우리는 프로그램이라고 부르게 된다.
프로세스는 해당 프로그램이 Execute되면 생성되는 인스턴스를 의미한다. 이게 무슨 말인고 하면, 우리가 프로그램 아이콘을 더블 클릭을 하게 되는 경우, 컴퓨터는 프로그램을 실행하고자 프로그램에 대한 정보들을 메인 메모리 상에 올리게 된다. 우리는 이를 프로그램이 Execute되었다고 표현하게 된다. 그런데 100GB 짜리 거대한 게임을 실행한다고 하자. 해당 게임이 뜨기까지는 어느정도의 딜레이가 발생한다(해당 주제에 대한 자세한 설명은 5장 Scheduling 단원에서 자세히 배운다.). 우리는 프로그램은 분명 Execute 하였지만 아직 우리가 원하는 동작이 수행된 상태는 아니다. 문제가 없다면 잠시 후에 게임창이 뜨게 되는데, 이때를 프로그램이 RUN되는 상태라고 이해할 수 있다.

즉, 다시 말하면 OS는 프로그램이며, 실행 가능한 코드 덩어리에 불과하다. 다만 코드 덩어리가 워낙 길고, 그 구조가 복잡하기 때문에 컴파일하는데만 한 세월이 걸릴 수도 있는 그런 프로그램이다. 동시에 적어도 두 가지의 행동이 가능해야 하는데, 첫 번째는 컴퓨터 하드웨어를 제어할 수 있어야하고, 두 번째 프로그램의 Execute를 제어할 수 있어야만 한다.
그렇다면 OS는 우리 컴퓨터 상에서 어디에서 위치하게 될까? 다음 그림을 살펴보자

그림 상에서 확인할 수 있듯, OS는 하드웨어와 애플리케이션 사이에 자리하고 있다. 우리가 메모장에 글을 쓰는 과정을 생각해보자. user로서 나는 키보드를 통해 메모장에 무엇인가를 적으려고 시도하였다(user -> application programs). 컴퓨터는 키보드를 인식하고 I/O 동작이 이뤄진다. 메모장이 요구한 일련의 요구사항을 효율적으로 하드웨어에게 접근할 수 있도록 OS가 이를 매개한 것이다. OS의 정의에서처럼 OS는 아래로는 하드웨어를 위로는 프로그램을 제어하는 또 다른 하나의 프로그램이다.
때문에 시스템에서 활용되는 system program과 우리가 소위 App이라고 부르는 application program 모두 직접적으로 하드웨어에 접근할 수 없으며, system call interface라는 OS에서 제공하는 API를 통해 하드웨어에 간접적으로 접근할 수 있게 된다. 이는 2장에서 더 자세하게 배우게 된다.
이를 다시금 생각해보면 OS를 다음과 같이도 정의할 수 있다.
- OS is a resource allocator (= manages the computer hardware)
- OS is a control program (= controls the execution of programs)
이때, resource라 함은 CPU, Memory Stroage, I/O Device와 같은 하드웨어를 의미한다. OS는 다양한 알고리즘을 통해 하드웨어에 대한 다른 프로그램들 요청을 잘 조율하게 된다. 컴퓨터의 자원은 무한할 수 없기에 언제나 자원의 한계라는 문제에 직면하게 된다. OS는 조율자로써 자원의 효율적인 분배를 통해 가능한한 최적의 방식을 통해 다양한 요청들과 하드웨어 간의 충돌을 효율적으로 처리한다.
또 프로그램은 에러나 시스템을 잘못 활용하는 프로그램 등을 방지하는 제어 프로그램으로서 기능한다. Segmentation fault, Bus Error 등이 그것이다. OS는 잘못된 프로그램의 버그에 대해서 적절한 에러 메세지를 통해 유효하지 않은 프로그램들에 대해서 제어자 역할을 수행한다.
또 책에는 다음과 같은 정의를 통해서도 OS를 표현할 수 있다고 한다.
A more common definition, and the one that we usually follow, is that the operating system is the one program running at all times on the computer - usually called the kernel
해석하자면, OS는 컴퓨터가 켜져있는 동안 항상 실행되는 하나의 프로그램으로, kernel이라고도 부른다는 의미이다. 이때, 걸리는 점이 있었는데 그렇다면 OS와 kernel를 같은 의미로 사용해도 되느냐이다. 결론부터 말하자면 반은 맞고 반은 틀리다.
우리가 소위 OS라고 부르는 것에는 앞서 말했던 두가지 기능이 존재한다. 1) resouce allocator, 2) control program 이 그것이다. 이 두가지 기능을 수행하는 프로그램을 우리는 Kernel이라고 부르게 된다. 다만, OS는 앞서 언급하였듯 종류가 다양하고, 각각 OS라고 정의하여 부르는 범위가 다양하다. 때문에 우리가 접하는 대부분의 상당 수의 OS는 해당 기능 외에도 추가적인 소프트웨어를 포함하는 경우가 많다. 즉, OS 중 코어가 되는 두가지 기능을 지닌 프로그램을 우리는 Kernel이라고 부르게 되며, 해당 기능 외에 추가적으로 내재되어있는 프로그램까지 우리는 OS라고 부르게 된다.
이에 대한 예시로, 안드로이드 OS를 생각해볼 수 있다. 우리가 소위 안드로이드라고 부르는 Android os를 살펴보자.

가장 하단의 Linux Kernel를 주목하자. 안드로이드는 Linux를 기저에 두는 OS이다. 그러나 안드로이드 개발자들은 평소에 개발하면서 Linux의 내부 구조에 능통하지 않아도 괜찮다. 상위 계층의 Andriod Framework가 이를 감싸주고 있기 때문이다. 우리가 안드로이드라고 부르는 OS는 가장 하단의 Linux Kernel만을 의미하지는 않게 된다. 이 외에도 그림에서 볼 수 있는 Libraries, Runtime, Framework ... 같은 주요 프로그램들이 OS 내부에 함께 존재한다. 혹시나 후에 둘의 차이가 혼동된다면 Android os 내부에 Linux Kernel이 있음을 상기해보자.
핵심은 Application 영역에서 컴퓨터의 하드웨어로의 직접적인 접근이 불가능하며, 언제나 OS 내부의 Kernel을 거쳐 Kernel이 제공하는 API를 통해서만 하드웨어와 커뮤니케이션이 가능하다는 것이다. read(), write() 함수를 C언어에서 호출하는 경우를 생각해보자. 해당 함수는 프로그램으로써 스토리지에 저장이 되어있을 것이다. 우리는 OS에서 제공하는 read / write 함수를 통해 스토리지에 접근할 수 있게된다. 또 다른 예시로 malloc() 함수를 들 수 있겠다. 일반적으로 알려져 있듯, C언어에서 힙 영역을 사용하기 위해 우리는 malloc() 함수를 사용한다. 다만, 그 자세한 내부 원리까지는 우리가 알지 못하며, 알 필요가 없다. 다만 C언어를 통한 프로그램을 작성하면서 이만큼의 데이터를 저장하기 위해, 공간을 할당해달라는 요청을 할 뿐, 그 하위의 동작은 OS가 전담한다. 즉, 일반적인 웹의 API와 그 철학을 대부분 공유한다.
그러나 해당 함수를 API라고 하진 않는다. API는 해당 함수가 호출된 이후의 일종의 약속된 신호 즉, System Call을 의미한다. 해당 챕터와 다가오는 Chapter 2에서 다시금 다루겠지만, 일반 Application program, System program 모두 OS를 거쳐 하드웨어와의 상호 작용을 하게되는데, 이때 항상 System Call 이라는 약속된 신호를 통해 커뮤니케이션을 하게 된다. 그러니까, 앞서 그림 1-2에서 살펴보았던 컴퓨터 구조도에서 OS layer와 System and Application program Layer 사이에 System call Layer가 중간을 매개한다고 생각할 수 있겠다.
1.2 Computer-System Organization
OS 는 앞서 언급하였듯이 하드웨어 부분의 다양한 부품 / 기기들과 커뮤니케이션을 하게 된다. 뿐만 아니라 각 하드웨어끼리는 서로 맡은 바 역할에 따라 수행하는 역할이 분화되어 있어, 같은 하드웨어 시스템 내에 다른 부품 / 기기들과 긴밀하게 연결되어야 한다.
해당 섹션에서는 이러한 커뮤니케이션이 어떻게 이뤄지는지 그 간단한 원리를 살펴본다.
이를 설명하기 위해 그림을 하나 가져왔다. 아래 그림은 우리가 컴퓨터 하드웨어 시스템이라고 부를 수 있는 기기들의 조합을 보여준다.

OS는 다양한 기기들이 긴밀하게 연결될 수 있도록 동작한다. 대표적인 예시로 프로그램을 Execute하는 경우가 있을 것이다. OS는 하드웨어 위에서 유저의 요청을 받아 프로그램을 Execute 해야 한다. 그러기 위해선 우선 CPU가 프로그램을 시작할 수 있도록 명령을 내려야 할 것이다. 이때 해당 프로그램의 코드는 디스크에 존재한다. 다만, 우리가 Disk에 있는 데이터를 그대로 쓸 수 없기에 이를 메모리에 올리게 된다(소위 로딩이라고 부르는 과정). 동시에 키보드나 모니터와 같은 I/O 기기로 부터 들어오고 나가는 신호들이 있을 것이다. 이러한 데이터 또한 마찬가지로 메모리에 올린 다음에야 우리가 원하는 동작을 수행할 수 있다.
이때 데이터는 bus라는 형태의 와이어를 거쳐 이동한다. 간단하게 말해서 데이터가 이동하는 통로라고 생각하면 될 것 같다. 이처럼 다양한 하드웨어가 bus라는 데이터 통로로 서로 연결되어 서로의 데이터를 교환한다.
조금만 더 깊게 들어가보자. 먼저 메모리의 중요성에 대해서 언급하고자 한다. 먼저 지르고 가자면 메모리가 중요한 이유는 CPU와 Interaction을 주고 받을 수 있는 유일한 데이터 저장소이기 때문에 그렇다. 앞서 프로그램을 Execute할 때도, 디스크는 CPU와 직접적으로 작용하는 대신 메모리에 로딩을 거쳐 해당하는 데이터를 사용하였다. I/O 기기도 마찬가지이다. 키보드에서 값이 쓰여질 때도, 모니터가 현재의 화면을 출력하고 싶을 때에도 항상 메모리를 거쳐 CPU와 상호작용을 주고 받을 수 있다. I/O의 경우에도 I/O 컨트롤러라고 하는 하드웨어 장치를 가지고 있으며, 해당 장치에도 작은 메모리 저장소를 가지고 있다. 디스크와 마찬가지로 해당 저장소 또한 CPU와 직접적으로 데이터를 주고 받을 수 없다. 오직 메모리만이 CPU와 데이터를 주고 받는다. 때문에 bus의 구조를 살펴보면 모든 bus의 중앙에 메모리가 위치하는 것을 볼 수 있다. 메모리는 일종의 데이터 교환의 핵심으로써 프로그램의 실행과 데이터 교환에 중간에서 매우 중요한 역할을 수행한다. 그래서 CPU와 I/O 기기들의 경우 mermory의 접근 권한을 얻기 위해서 서로 경쟁하게 된다고 가볍게 알아두자.
그렇다면 우리가 I/O를 수행한다고 하는 의미에 대해서 집중적으로 들어가보고자 한다. 앞서 bus를 통해 데이터가 이동한다는 사실을 잠깐 언급하였다. 그렇다면 도대체 어떤 과정을 거쳐 데이터가 이동한다는 것인지에 대해서 이야기해보자. 로딩을 하는 상황을 생각해보자. CPU는 데이터를 가져오기 위해서 최초로 I/O를 실행한다는 의미에서 I/O initiation을 I/O Device에 보낸다. 컨트롤러는 이를 인지하고 필요한 데이터를 메모리에 전송한다. 이후 데이터가 필요할 때마다 CPU는 디스크에 요청을 보내고 해당하는 데이터를 그때마다 메모리에 계속 올릴 수 있다. 이 방식은 물론 동작 자체에는 문제가 없지만, I/O 과정에 CPU가 계속해서 데이터가 필요할 때마다 데이터 요청을 보낸다는 측면에서 비효율적이다. 때문에 이러한 방식은 현재 사용되지 않는다.
I/O 기기 혹은 디스크와 메모리의 Interaction, 즉 데이터가 왔다갔다하는 것을 I/O라고 부른다.
관련해서 I/O transaction은 I/O 버스를 통해 데이터가 이동하는 것을 의미하는데, 때문에 I/O transaction은 I/O 과정에서 반드시 수행될 수 밖에 없다.

대신 대부분의 OS에서는 DMA라는 방식을 사용하여 CPU의 개입을 최소화한다. DMA의 원리는 다음과 같다. CPU는 최초의 I/O initiation을 I/O Device에 보낸다. 그리고 이에 따라 원하는 데이터를 전송한다. 여기까지는 앞선 방식과 동일하다. 다만, 이 이후로는 I/O에 CPU가 개입하지 않는다. 그러다보니 CPU는 I/O가 이뤄지는 동안 다른 작업을 수행할 수 있게 된다(execute tasks concurrenctly).
그림으로 보면 다음과 같다.

CPU는 I/O initiation을 Disk Controller에게 알린다. 이에 따라 Disk가 응답을 CPU에게 보내준다. 이어서 CPU의 요청에 따라 데이터를 메모리에 올리게 된다. 그렇다면 이제 CPU가 메모리 상에 모든 데이터가 올라왔다는 것을 알아야하지만, 해당 요청은 CPU의 개입이 더이상 이뤄지지 않았기 때문에 CPU는 이를 알 방법이 없다. 이를 해결하는 방법이 바로 Interrupt의 존재이다. Disk는 모든 데이터를 메모리에 다 올리게 되면, CPU에게 Interrupt라는 매커니즘을 통해 신호를 주게 된다. CPU는 이를 인지하고 아까 전에 Initiation으로 요청하였던 I/O 작업이 완료되었음을 확인할 수 있게 된다. 교수님께서는 해당 과정에 대해서 고등학생 과외를 하는 예시를 들어주셨는데, 과외 선생님이 문제를 20번 까지 풀라고 학생에게 지시한 다음에 본인은 다른 일을 하는 경우, 학생이 문제를 다 풀고 나서 "선생님 저 다 풀었는데요"라고 Interrupt를 통해 선생님에게 알려준다고 생각하면 쉽게 이해할 수 있다. 대표적인 Interrupt로 timer interrupt가 있다.
정리하자면,
- I/O Transaction은 버스를 통해 이뤄진다.
- 이때의 버스는 주소, 데이터, 시그널 등을 나를 수 있도록 Parallel하게 연결된 와이어의 집합이다.
- 버스는 그 위치와 용도에 따라 다양하게 분화될 수 있다.
- 시스템 버스는 CPU와 I/O bridge를 연결한다. (I/O bridge는 위의 그림에서 볼 수 있듯, 일종의 하드웨어 상에서 I/O의 중간 매개자 역할을 수행한다.)
- 메모리 버스는 I/O bridge와 메모리를 연결한다.
- I/O 버스는 다양한 기기들의 컨트롤러 위에 붙어, 해당 기기들과 I/O bridge를 연결한다.
- DMA는 기기에서 Read / Write와 같은 동작을 수행하고자 할때, 이를 CPU의 개입없이 데이터를 보내는 것을 의미한다.
- 때문에 DMA로 인해 CPU는 해당 transfer의 시작을 알릴 뿐, 이후에는 계속해서 다른 일을 수행할 수 있게 된다.
알고리즘을 살펴보자면 다음과 같다.

CPU의 입장
- 기기의 드라이버가 I/O를 시작한다. I/O 드라이버에게 신호를 보낸 상태이다. -> I/O 컨트롤러의 1번으로 진입한다.
- 신호를 보낸 이후, Interrupt를 감시하도록 check를 계속 진행한다. 이 사이에는 다른 작업이 계속해서 수행된다.
- Interrrupt를 받으면, Interrupt Handler에게 이를 처리하도록 한다.
- Interrupt Handler는 데이터를 처리하고, 적합한 동작을 처리한 후 Interrupt를 리턴한다.
- CPU는 다시 Interrupt를 받기 이전의 작업을 다시 실행한다. (엄밀히 말해서, save state, return state 모두 Handler의 역할이다)
- 이후 다시 I/O가 요구되면 1로 돌아간다.
*Interrupt Handler( = interrupt Service Routine, ISR)는 인터럽트가 들어왔을 때 수행되는 특정 기계어 코드 루틴이다. 이때 루틴은 명령어의 집합으로 이해하면 되는데, 결국에는 해당 명령어들이 위치한 코드 덩어리라고 생각하면 되겠다.
I/O 컨트롤러의 입장
- 대기 상태에 있다가 Initiation 신호를 받으면, I/O를 시작한다.
- I/O를 위한 준비를 마치고, 관련 작업을 모두 수행한 이후 CPU에게 Interrupt를 보낸다. -> CPU의 3번으로 들어간다.
현대의 OS는 Interrupt Driven이다.
현대의 OS에서는 User의 요청으로부터 시작되는 Interrupt나 운영체제상에서의 커널에 의한 시스템 Interrupt, 그 외의 Trap으로 대표되는 Exception이나 System Call에 의해서만 작업을 시작한다. 하나의 Interrupt에는 Table에 의해 제공된 하나의 ISR이 존재하게 된다.
Interrupt 가 수행되는 과정을 자세히 살펴보자.
CPU는 Interrupt가 들어오면 해당 Interrupt가 어떤 역할을 수행하는지를 알아야 한다. 이를 통해 Interrupt Vector Table을 조사하여 해당 Interrupt가 어떤 Handler와 연결되어 있는지를 알 수 있게 된다.
2장에서 더 자세히 배우겠지만, Interrupt Vector는 source는 두가지 컬럼을 반드시 갖는다. 하나는 source이고 또 다른 하나는 ISR 주소이다. source에는 이것이 어떤 Interrupt인지, ISA 주소에는 즉 해당하는 Interrupt Handler의 주소가 들어있어 Interrupt가 들어오면 적절한 서비스 루틴 코드가 실행될 수 있도록 안내한다.


결국 Interrupt Vector를 살펴봄으로써 해당 Interrupt가 위치한 source의 칼럼을 뒤진 후에, 해당 source와 같은 로우에 위치한 ISR routine의 주소를 찾게 되는 것이다.

대표적인 Interrupt로 Timer Interrupt를 들 수 있다. CPU의 수많은 동작에서 Timer Interrupt는 중요한 역할을 한다. 바로 중간 중간 딜레이를 주는 역할이다. Timer Interrupt가 들어오면 CPU는 하던 일을 멈추고 작업의 주소를 저장해놓고, Interrupt Vector를 참조하여 source가 Time Interrupt인 ISR 주소를 찾게 된다. 이를 따라서 ISR이 실행되고 Interrupt에 해당하는 코드가 실행된다. 코드가 수행된 이후 CPU는 다시 중지했던 작업의 주소를 참조하여 기존 작업을 이어서 수행한다.

해당 그림에서의 IRQ는 Interrupt ReQuest 를 의미한다.
이어서 PIC는 Programmable Interrupt Controller의 약자로 인터럽트 처리에 관련된 세부 기능을 프로그래밍할 수 있는 컨트롤러이다.
PIC에 Interrupt가 수신되면, 이를 CPU의 INTR 핀에 보낸다. PIC는 CPU가 받았다는 신호를 주는 기다리게 되고, CPU 프로세서는 해당 Interrupt를 받았다는 것을 PIC 핀에게 알린다. 이후는 앞서 여러번 언급했다 싶이, Interrupt Vector Table과 ISR(Handler Routine)을 거쳐 해당 Interrupt가 수행되게 된다.
여담으로 앞서 언급했던 주소를 왔다 갔다하는 것은 Program counter register라는 것을 통해 가능하다. 프로그램 카운터는 현재 실행 중인 명령의 주소(위치)를 포함하는 컴퓨터 프로세서의 레지스터이고, 컴퓨터 구조 MIPS의 J-type과 같은 명령어를 통해 해당 주소로 이동한다.
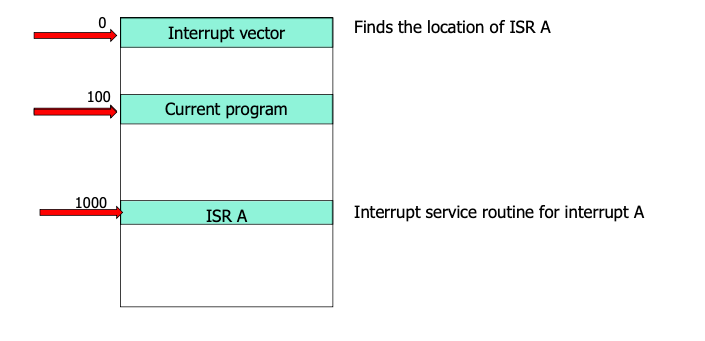
먼저, CPU가 100이라는 주소에서 프로그램을 실행하고 있다고 하자. 그러다가 Interrupt가 딱 들어온다. CPU 입장에서는 Interrupt Vector를 참고하여 해당하는 ISR 주소가 어디있는지를 찾아야 한다. 이는 0의 주소에 위치한다. 0에 가서 ISA 주소를 찾고 봤더니 해당하는 ISA 주소는 1000에 위치한다. 그래서 1000으로 Jump하게 되는데, 바로 이때 주소의 Jump는 Program counter register를 통해 가능하게 된다.
Interrupt vs Trap
Interrupt와 가장 혼동되는 개념이 Trap이다.
앞에서 봤던 Interrupt의 개념을 잘 기억하자. 한편, 이러한 신호를 소프트웨어에서도 줄 수가 있다. 이를 바로 Trap이라고 한다. 예를 들어보자. C 프로그래밍을 하다가 Bus Error, Seg fault와 같은 문제가 발생하면 CPU에게 이를 알려야한다. 이를 Exception이라고 한다. 또한 OS에서 하드웨어 자원에 접근하고자 하는 경우, 혹은 Application에서 하드웨어 자원이 요구되어 이를 접근하고자 하는 경우, System Call이 발생한다. 이와 같은 경우를 Trap이라고 명명한다.
Trap과 Interrupt를 더 명확히 구분하려면 Asynchronous와 synchronous의 개념을 이해해야 한다. 앞서 CPU가 계속해서 Interrupt가 들어오는지를 check하는 것을 떠올려보자. CPU 입장에서는 언제 Interrupt가 들어오는지를 모르기 때문에 계속해서 체크를 할 수 밖에 없다. 이것이 Asynchronous이다. 반대로 Trap의 synchronous는 다르다. Trap의 경우 프로그램이 시작된 이후 발생한다. 때문에 특정 명령을 실행한 결과로써 나오는 결과물이다. Trap의 대표적인 예시인 System Call은 2장에서 더 자세히 다루게 된다.
다음으로는 Storage structure에 대한 내용이다.
여기에서 중요하게 다루는 메모리는 역시 Main memory이다. 그 외에도 HDD, SSD와 같은 Secondary Storage가 등장한다. 그 외에도 우리가 Teriary Storage라는 대개 백업을 위한 Storage도 존재한다.

위 그림은는 Storage의 계층도를 나타낸다. 위로 올라갈 수록 CPU에 가까우서 Speed가 빨라진다. 그러나 Cost가 높아 많은 용량을 확보할 수가 없다. 때문에 모든 데이터를 레지스터와 캐시에 저장할 수 없기에 우리는 HDD나 SSD와 같은 magnetic disk, 즉 보조 기억장치를 활용하게 된다. optical disk와 magnetic tapes들의 경우 최근들어 보기가 매우 귀해졌다고 하며, 그런 것이 있구나 정도만 하고 넘어가자. 추가적으로 cache는 SRAM이라고도 부르며, main memory는 DRAM이라고도 부른다.
결국 Cost와 Performance간의 Trade-Off가 이뤄진다는 점을 이해하고 넘어가면 되겠다. 이때의 속도를 좌우하는 핵심으로써 Caching Decision(대표적으로 LRU 캐싱)이 등장하게 되는데, 이는 추후 다시 등장할 때 자세히 다루도록 하자.
1.3 Computer-System Architecture
앞선 그림 1-4에서는 하나의 CPU가 등장하여 다양한 부품 혹은 장비들과 상호작용을 이룬다. 그러나 현실의 실제 컴퓨터는 조금 다르다. CPU는 꼭 한 개일 필요는 없으며, 그 이상일 수 있다. 이러한 구조를 Multi-processing 구조라고 한다. Multi-processing의 경우 여러개의 프로세서가 서로 협력하여 작업을 수행한다. 해당 구조는 다음과 같은 장점을 갖는다.
- Increased Throughput
- Economy of scale
- Increased reliability
1. Increased Throughput의 경우에는 작업을 여러명이서 수행한다고 생각하면 당연하다. 이후 등장하는 개념인 쓰레드와 달리, 프로세서의 증가는 작업을 할 수 있는 실제 자원량의 증가를 의미한다. 다만 우리는 N개의 CPU를 추가하며 N배의 성능 향상은 실질적으로 어렵다(서로 간의 커뮤니케이션에도 오버헤드가 발생한다).
2. Economy of scale도 발생한다. 만약 CPU 내의 여러 개의 프로세스가 Shared Memory를 가지고 이를 활용할 경우, 각 데이터를 해당하는 프로세서에게 별도의 할당없이 하나의 공간에 데이터를 모두 저장한 후 이를 공유한다면, 비용이 절약되게 된다.
CPU
3.Increased reliability, CPU가 여러 개라는 점은 곧 fault tolerance가 높다는 것을 의미한다. 하나의 CPU가 실패하더라도 다른 CPU가 이를 대신 처리할 수 있기 때문이다.
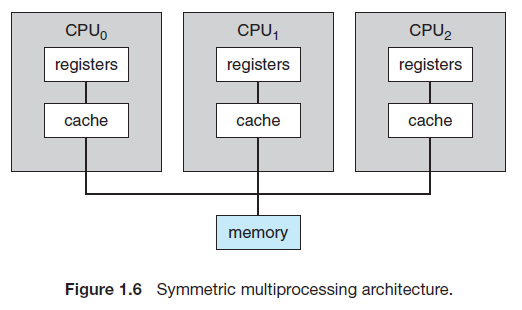
Multi-processing 구조의 분류
Multi-processor는 다음과 같이 총 두 종류로 나눠진다.
- Asymmetric multiprocessing(ASMP)
- Symmetric multiprocessing(SMP)
분류의 기준은 CPU들간의 상하 관계가 존재하는지의 여부이다. 먼저 ASMP의 경우, processor(CPU)들간의 상하 관계가 존재한다. 하나의 Master processor가 나머지 Slave relationship을 조율하게 되는데, 이때 master processor는 오직 slave processor의 조율자로서 역할을 수행하며, 나머지 slave processor가 실제 작업을 수행한다.
반대로, SMP의 경우 master-slave 관계가 존재하지 않는다. 모든 processor가 slave로써 작업을 수행한다고 보면 되겠다.

메모리 접근 방식에도 두 가지가 있다.
- UMA, 메모리 엑세스 타입이 언제나 일정하다
- NUMA, 메모리 엑세스 타입이 CPU마다 다를 수 있다.
UMA는 Uniform memory access의 줄임말로, 언제나 일정한 메모리 엑세스 타입을 보장하는 메모리 접근 방식을 의미한다. NUMA는 Non-Uniform memory access의 줄임말로, 메모리 엑세스 타입이 CPU마다 상이할 수 있는, 즉 메모리의 일정한 접근이 보장되지 않는 형태의 접근 방식이다. 개인적으로 NUMA의 경우 Private storage 접근이 Common storage보다 접근이 빠를 수 밖에 없다고 생각하니 잘 와닿았다 .
Multi-core vs Multi-processing
앞서 Multi-processing를 살펴보았다. 그렇다면 Multi-processing와 Multi-core의 차이는 무엇일까?
간단하다. 단일 컴퓨터의 프로세서가 여러 개 존재하면 Multi-processing이고, 여러 개의 코어가 하나의 프로세서에 있다면 Multi-core이다.
현재 우리가 주위에서 보는 컴퓨터는 주로 Multi-core 구조를 표방한다. 왜그럴까? 정답은 Multi-process보다 Multi-core 구조가 발열과 전력 소모 측면에서 훨씬 우월하기 때문이다. single core 구조에서 10GHz를 커버하면 성능을 확 올릴 수 있다. 그럼에도 4개의 코어를 사용하는 코어에서 각각 2.5GHz를 커버한다면 훨씬 발열과 전력 문제에서 더욱 효과적이게 된다.
1.4 Operating-System Operation

Multiprogramming
관련하여 Multiprogramming이라는 개념도 등장한다. 이후 5장에서 다시 배우겠지만, CPU는 하나의 단일 작업을 수행하는 대신 여러 개의 작업을 스케쥴링하며 진행한다. 스케쥴링을 통해 CPU는 쉬지 않고 작업을 계속 연속적으로 수행할 수 있게 된다. 특정 작업에서 딜레이가 발생하면 OS는 바로 다른 작업을 수행하도록 CPU를 바쁘게 유지한다.이때 Multiprogramming은 단일 프로세서가 단일 프로세스를 처리하는 동안 다른 프로세스에도 접근하도록 하는 것을 의미한다. 즉, 작업 중인 특정 프로세스의 완료를 기다리는 것 대신, 그 동안 다른 프로세스를 처리할 수 있도록 해주는 것이다. 이는 이후에 배우게 되는 Context-switch에 기반한 개념임을 가볍게 기억하고 넘어가자.
Swapping
swapping이라는 개념도 등장한다.메모리의 경우에는 CPU 자원이 한정되어 있는 상황이기에, 효과적인 메모리 자원 할당이 요구된다. '어떤 Job을 메모리에 올려야하나', 'CPU 자원을 어디에 쓰는 것이 효율적인가?' 등 고려해야할 상황이 많다.
기존 메모리에 있는 것을 걷어내고 새로운 것을 메모리에 올릴 수도 있다. 이를 swapping이라고 한다(메모리에 올리는 것을 swap-in, 걷어내는 것을 swap-out이라고 한다). swap-in, swap out이 연속적으로 이뤄지면서 마치 사용자들은 계속해서 메모리에 Job이 계속 위치한 것처럼 느끼게 된다.
Multitasking
여기서 또 헷갈리는 용어가 등장한다. 바로 Multitasking이다. 직전의 Multi-programming이 단일 기기에서 여러 프로그램을 돌리는 것이였다면, Multitasking은 여러 CPU를 사용하는 동일한 컴퓨터에서 한 사용자가 여러 프로세스를 동시에 실행하는 것을 의미한다. 즉, 스케쥴링을 통해 다수의 작업을 번갈아가면서 수행한다. 다수의 작업을 스케쥴링을 통해 번갈아가며 수행하기 때문에 유저는 다양한 작업을 동시에 수행하는 것과 같은 느낌을 받는다. 때문에 Multitaking은 Multiprogramming을 구현하는 방식의 하나라고 이해할 수 있겠다. 이 외에도 Real-time(RTMOS), Time sharing 방식등을 통해 Multiprogramming을 구현할 수 있다.

Virtual Memory 기법

Virtual Memory는 메모리를 관리하는 방법의 하나로, 각 프로그램에 실제 메모리 주소가 아닌 가상의 메모리 주소를 주는 방식을 말한다. Virtual Memory는 실제 메모리 공간이라기보단 지금 DISK에서 참조하고 있는 주소를 의미하게 된다. 반대로 Physical Memory의 경우 실제 Memory에 쓰여있는 값을 의미한다는 점에서 두 개념의 차이가 도드라지는 것을 볼 수 있다.
Virtual Memory의 동작을 이해하기 위해서는 Swapping을 이해해야 한다. 앞서 잠깐 언급하였듯이 CPU에서는 Job Scheduling을 통해 수행하는 작업을 최대한 효율적으로 처리하기 위해 다양한 작업을 계속해서 Context-Switch하게 된다. 이때, 이 과정이 매우 빠르게 일어난다면, 유저는 마치 동시에 여러개의 작업을 수행하는 것과 같은 느낌을 받게 된다. 메모리가 사용되는 과정에서도 마찬가지이다. 우리의 메모리 자원은 한정적이다. 때문에 이를 효과적으로 수행하기 위해서 Swapping을 수행한다. swapping in이 되면 메모리에 올라온다. 다만, 메모리의 한계로 인해 모든 작업을 한 번에 swapping in 할 수는 없다. 대신 swapping in, swapping out을 매우 빠르게 수행하며 마치 여러 개의 작업을 동시에 메모리에 Load하는 것과 같은 효과를 줄 수 있다. 이때 Virtual Memory Address에서는 Swapping에 곧바로 참여할 수 있도록 Disk에 특정 부분을 가리키고 있는데 이를 Virtual Memory 기법이라고 한다.
Dual Mode operation
Dual이라는 단어에서 유추할 수 있듯이, 해당 용어는 OS가 지원하는 두 가지의 모드에 대한 내용이다. OS에서는 User mode와 Kernel mode라는 두 가지 모드를 지원한다. 구분하는 근거는 특정 시점을 딱 집었을 때, 실행하고 있는 코드의 종류를 기준으로 한다. 예를 들어, 어떤 특정 시점을 딱 잡았는데 해당 시점에서 유저의 애플리케이션 코드를 실행한다면, 해당 시점을 user mode로 판단한다. 반대로, 어떤 특정 시점을 딱 잡았는데 해당 시점이 kernel code를 실행한다면 해당 시점을 kernel mode로 판단한다. Kernel mode는 System Call이 발생하거나, Interrupt가 발생하는 경우에 진입하게 된다. 이 외에도 시스템이 부팅될 때 Kernel mode로 실행이 되어 이후 user mode로 전환된다는 점도 알아두면 좋을 것 같다.

위의 그림은 System Call이 발생한 경우, user mode에서 kernel mode로 전환되는 과정을 보여준다. 먼저, user 프로그램이 실행됨에 따라 user process가 실행된다. 그러다가 하드웨어 자원이 필요하여 system call을 하게 되는 경우, trap이 발생하여 mode bit를 1 에서 0으로 바꾸게 된다. 이후 system call에서 파생된 작업이 모두 종료가 되면 mode bit를 다시 1로 바꾸며 user mode에 복귀하게 된다.
이렇게 모드를 분리하는 이유는 간단하다. OS를 보호하기 위함이다.
OS의 특정 작업들은 기기에 치명적인 영향을 줄 수 있다. 정말로 위험한 작업들은 유저가 아닌 커널만 수행할 수 있도록 하여, OS를 잠재적인 위협으로부터 보호한다.
kernel mode에서 수행되는 대표적인 작업(Privilleged Instructions)은 다음과 같다.
- H/W access
- I/O access
- mode transition
때문에 user mode에서 Privilleged Instructions을 수행하려고 하는 경우, 접근이 차단되게 된다.
책에 잠깐 언급되는 내용으로 Intel processor의 protection rings라는 개념이 등장한다. 이론은 간단하다. 두 개의 모드로 관리되는 것을 넘어 총 4 단계로 모드를 구분하여 앞의 Dual-Mode를 더욱 세분화한다. virtual machine manager(VMM)라는 개념도 등장한다. 별건 아닌데, VMM의 경우 가상 머신을 만들고 관리할 수 있도록 CPU의 State를 변경할 수 있기에 user mode보다는 권한이 많은, kernel mode보다는 권한이 적은 것으로 책에 소개된다.
여기까지 1장의 내용을 마무리하고자 한다. 뒤에 더 많은 내용이 나오지만, 원론적인 내용이 많을 뿐 뒤에서 자세하게 다루는 내용의 개요이기에 너무 자세히 들어가지는 않고자 한다. 2장에서는 System Call에 대한 내용이 등장한다. 많은 부분을 위에서 다뤘지만, 2장에서는 이를 더 자세하게 파고 들어가보려고 한다.
'CS' 카테고리의 다른 글
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
|---|---|
| Cache Memory 소개 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
| [리눅스 프로그래밍] Kernel 개요 (1) | 2022.09.23 |
| [리눅스 프로그래밍] 리눅스 계보 (2) | 2022.09.23 |