




일단 링커가 심볼 해석 단계를 완료하면, 코드 내 각 심볼 참조는 정확히 한 개의 심볼 정의에 연결되게 된다. (즉, 입력 목적 모듈 중 하나의 심볼 테이블 엔트리에 대응되게 된다). 이 시점에 링커는 입력 목적 모듈 들 안에 코드와 데이터 섹션들의 정확한 크기를 알고 있다. 이제 재배치 단계를 시작할 준비가 되었다. 해당 단계에서는 입력 모듈들을 합치고 각 심볼에 런타임 주소를 할당하게 된다.

재배치는 두 단계로 구성된다.
1. 섹션과 심볼 정의를 재배치한다.
이 단계에서 링커는 같은 종류의 모든 섹션들을 하나의 새로운 통합된 동일한 타입의 섹션으로 합친다. 예를 들어, 입력 모듈들의 .data 섹션들은 출력 실행 목적파일을 위한 한 개의 .data 섹션으로 합쳐진다.
이후 링커는 런타임 메모리 주소를 새로운 통합된 섹션들, 입력 모듈들에 의해 정의된 각 섹션들, 입력 모듈들에서 정의된 각 심볼들에 할당한다. 이 단계가 마무리될 경우 프로그램 내의 모든 인스트럭션과 전역변수들은 유일한 런타임 메모리 주소를 가진다.
2. 섹션 내 심볼 참조를 재배치한다.
이 단계에서 링커는 코드와 데이터 섹션 내의 모든 심볼 참조들을 수정해서 이들이 정확한 런타임 주소를 가리키게 한다. 이 단계를 수행하기 위해서 링커는 재배치 엔트리라고 알려진 재배치 가능 목적 모듈들 안의 자료구조에 의존하게 된다.
심볼 참조의 재배치
typedef struct {
int offset; // offset of the field in the structure
int symbol:24; // symbol index
type: 8; // type of the field
} Elf32_Rel;foreach section s {
foreach relocation entry r {
ref = s + r.offset;
if (r.type == R_386_PC32)
refaddr = ADDR(s) + r.offset;
*refptr = ADDR(r.symbol) + *refptr - refaddr;
if (r.type == R_386_32)
*refptr = ADDR(r.symbol) + *refptr;
}
}
해당 코드는 링커의 재배치 알고리즘을 위한 의사코드를 보여준다. 두 번의 foreach 구문은 각 섹션와 각 섹션에 연결된 재배치 엔트리들에 대해 반복 실행된다.
설명의 편의성을 위해 각 섹션은 바이트들의 배열이고, 재배치 엔트리 r은 Elf32_Rel 타입의 구조체라고 가정한다. 또한 알고리즘이 실행될 때, 링커가 이미 각 섹션과 심볼[ADDR(r.s)]들을 위한 런타임 주소[ADDR(r.symbol)]를 선택했다고 가정한다.
이때 3 번째 줄의 ref = s + r.offset에서는 재배치될 필요가 있는 4 바이트 참조의 배열 s 내의 주소를 계산한다. 만일 이 참조(ref)가 PC-상대 주소 방식을 사용한다면, 이것은 아래 첫 번째 조건문에 해당하여 재배치된다. 만일 이 참조가 절대 주소방식을 사용한다면 이는 그 아래의 조건문에 의해 재배치된다.
앞서 자세히 설명하지는 않았지만 심볼 참조의 재배치를 수행하는 방법에는 여러 가지 방법이 존재한다. 해당 글에서 다루는 범위를 초과하여 담지는 못하였으나 대신 참조할 수 있는 링크를 첨부하며 마무리하고자 한다.
https://www.intezer.com/blog/malware-analysis/executable-and-linkable-format-101-part-3-relocations/
'CS > OS' 카테고리의 다른 글
| 공유 라이브러리로 동적 링크하기 (load-time linking) (0) | 2022.12.05 |
|---|---|
| 링커가 정적 라이브러리를 통해 참조를 해석하는 방법 (0) | 2022.12.05 |
| 심볼과 심볼 테이블 (0) | 2022.12.02 |
| Linker의 역할 - 1. Symbol Resolution (0) | 2022.12.02 |
| 정적 링킹과 목적 파일 (0) | 2022.12.02 |
각 재배치 가능 목적 모듈 m은 m에 의해서 정의되고 참조되는 심볼들에 대한 정보를 포함하는 심볼 테이블을 가지고 있다. 링커의 문맥 내에서 세 가지 서로 다른 종류의 심볼이 존재한다.
- 모듈 m에 의해 정의되고 다른 모듈에 의해서 참조될 수 있는 전역 심볼. 전역 링커 심볼은 non-static C 함수와 C의 static 타입 선언 없이 정의된 non-static 전역변수들에 대응된다.
- 모듈 m에 의해 참조되지만 다른 모듈에 의해 정의된 전역 심볼. 이러한 심볼은 external이라고 부르며, 다른 모듈 내에서 정의된 변수들과 C함수들에 대응된다.
- 모듈 m에 의해서 배타적으로 참조되고 정의된 지역 심볼. 일부 지역 링커 심볼들은 static 타입으로 정의된 C함수와 전역변수들에 대응된다. 이 심볼들은 모듈 내 어디에서나 접근이 가능하지만, 다른 모듈에 의해서는 참조가 불가능하다. 어떤 목적 파일 내의 섹션들과 모듈 m에 대응하는 소스 파일의 이름은 또한 지역 심볼이 많다.
지역 링커 심볼들이 지역 프로그램 변수와는 같지 않다는 점을 인식하는 것이 중요하다.
.symtab에 있는 심볼 테이블은 local non-static 프로그램 변수들에 대응되는 심볼을 전혀 포함하지 않는다. 이들은 런타임 시에 스택에 의해 관리될 뿐 링킹 단계와는 어떠한 관련도 없다.
대신 C의 static 타입 선언으로 정의된 지역 프로시저 변수들은 스택에서 관리되지 않고 대신 컴파일러가 .data나 .bss에서 각 정의에 대해 공간을 할당한다. 이 경우 심볼 테이블 내의 지역 링커 심볼로서 각 지역 프로시져 변수들은 유일한 이름을 갖게 된다.
예를 들어 다음의 코드에서 같은 모듈의 두개의 함수가 정적 지역변수 x를 정의한다고 하면
int f()
{
static int x = 0;
return x;
}
int g()
{
static int x = 1;
return x;
}해당 경우 컴파일러는 .data에 두 개의 정수를 위한 공간을 할당하고, 두 개의 유일한 지역 링커 심볼을 어셈블리어에 보낸다. 각각의 지역 링커 심볼로서 x.1은 함수 f 내에서만 사용하고 x.2는 함수 g 내에서만 사용한다.
'CS > OS' 카테고리의 다른 글
| 공유 라이브러리로 동적 링크하기 (load-time linking) (0) | 2022.12.05 |
|---|---|
| 링커가 정적 라이브러리를 통해 참조를 해석하는 방법 (0) | 2022.12.05 |
| Linker의 역할 - 2. Relocation(재배치) (0) | 2022.12.03 |
| Linker의 역할 - 1. Symbol Resolution (0) | 2022.12.02 |
| 정적 링킹과 목적 파일 (0) | 2022.12.02 |
컴파일러와 어셈블러를 거쳤다면 각각의 재배치 목적파일과 라이브러리들을 가지고 링커는 실제 실행이가능한 목적파일을 만들어낸다.
해당 글에서는 실행가능한 목적파일을 만드는 과정 중 링커가 수행하는 2가지 작업 중, 첫 단계인 Symbol Resolution(심볼 재해석)을 살펴보고자 한다.
Symbol Resolution (심볼 해석)
링커는 자신에게 입력된 재배치가능 목적파일들의 심볼 테이블로부터 정확히 한 개의 심볼 정의에 각 참조를 연결시켜서 심볼 참조를 해석한다. 심볼의 해석은 동일한 모듈 내에 정의된 지역 심볼들로 참조를 한 경우에 대해서는 간단하다.
컴파일러는 모듈 당 단 하나의 지역 심볼 정의만을 허용한다. 컴파일러는 또한 지역 링커 심볼들을 갖게 되는 정적 지역변수들이 유일한 이름을 갖도록 보장한다.
그러나 전역 심볼들에 대한 참조를 해석하는 것은 그보다 까다롭다. 컴파일러가 현재 모듈에서 정의되지 않은 변수나 함수 이름 등의 심볼을 만나면, 이것이 다른 모듈에서 정의되어 있다고 가정하고 링커가 심볼 테이블 엔트리를 생성하며, 링커가 이것을 처리하도록 남겨둔다.
만일 링커가 자신의 입력 모듈 중에 어디에서라도 참조된 심볼을 위한 정의를 찾을 수 없다면 에러 메세지를 출력하고 종료된다. 예를 들어 다음과 같은 소스 파일을 리눅스 머신에서 컴파일하고 링크하려고 한다면 컴파일러 단에서는 문제없이 동작하지만 링커는 foo에 대한 참조를 찾을 수 없기에 에러 메세지를 출력하고 종료한다.
void foo(void);
int main()
{
foo();
return 0;
}
또한 동일한 심볼이 다수에 목적 파일에서 정의되는 경우 문제가 된다. 이 경우 링커는 에러를 출력하거나 하나의 정의를 선택하고 나머지를 무시해야 한다. Unix 시스템에서 채택하는 방법은 컴파일러, 어셈블러, 링커가 함께 협력해서 부주의한 프로그래머에게 다소 혼란스러운 버그를 야기하는 문제가 있을 수 있다.
링커가 중복으로 정의된 전역 심볼을 해석하는 방식
컴파일 시에 컴파일러는 각 전역 심볼을 어셈블러로 Strong과 Weak 두 가지 형태의 심볼로 분류하고, 어셈블러는 이 정보를 재배치가능 목적 파일의 심볼 테이블에 묵시적으로 인코딩한다.
이때 함수들과 초기화된 전역 변수들은 Strong 심볼로 분류되며, bss (초기화되지 않은 전역 변수) 쪽은 Weak 심볼로 분루된다.
링커는 이와 관련해서 중복으로 정의된 심볼을 처리하기 위해 다음과 같은 규칙을 사용한다.
규칙 1: 복수로 정의된 Strong 심볼은 허용되지 않는다.
규칙 2: Strong 심볼과 중복 정의된 Weak 심볼들이 있으면 Strong 심볼을 선택한다.
규칙 3: 다중 정의된 약한 심볼이 있다면 어떤 Weak 심볼을 사용해도 상관 없다.
관련해서 몇가지 예제를 살펴보고자 한다.
예제 1. Strong 심볼 두 개가 중복되는 경우
/* foo2.c */
int x = 15213;
int main()
{
return 0;
}
/* bar2.c */
int x = 15213;
void f(){};위의 코드는 두 개의 파일을 의미한다.
이 경우 Strong 심볼인 x가 두 파일에서 중복되어 나타나므로 링킹 단계에서 에러 메세지와 함께 종료된다.
예제 2. 초기화된 전역 변수와 초기화되지 않은 전역 변수
/* foo3.c */
#include <stdio.h>
void f(void);
int x = 15213;
int main()
{
f();
printf("x = %d\n", x);
return 0;
}
/* bar3.c */
int x;
void f()
{
x = 15212;
}
런타임에 함수 f는 x 값을 15213에서 15212로 변경하며, 프로그램은 Strong 심볼과 Weak 심볼로 정의된 전역 변수들이 각각의 파일에 존재하므로 문제가 되지 않는다.
예제 3. Weak 심볼 두 개가 중복되는 경우
/* foo4.c */
#include <stdio.h>
void f(void);
int x;
int main()
{
x = 15213;
f();
printf("x = %d\n", x);
return 0;
}
/* bar4.c */
int x;
void f()
{
x = 15212;
}
전역 변수가 초기화되지 않았기에 두 전역 변수 모두 Weak 심볼이다. 앞서 설명하였듯 Weak 심볼이 두 개인 경우 우리는 어떤 심볼을 선택할지 알 수 없다. 때문에 Weak 심볼이 중복되어버린다면 예기치 못한 런타임 버그가 발생할 수 있다.
예제 4. Weak 심볼 두 개가 중복되는 경우 (데이터 타입이 다른 경우)
/* foo5.c */
#include <stdio.h>
void f(void);
int x = 15213;
int y = 15212;
int main()
{
x = 15213;
f();
printf("x = 0x%x y = 0x%x \n", x, y);
return 0;
}
/* bar5.c */
double x;
void f()
{
x = -0.0;
}
Weak 심볼이 중복되면서, 데이터 타입이 다른 경우이다. 이러한 케이스는 특정 환경에서 심각한 문제를 야기할 수 있다.
IA32/Linux 머신에서 double은 8 바이트이고 int는 4바이트이다. 그래서 bar5.c의 x를 -0.0으로 할당하는 부분은 x와 y가 위치한 메모리 영역에 음수 0의 이중정밀도 부동 소수점 표시로 덮어 쓰게 된다. 이러한 종류의 버그는 컴파일 시스템으로부터 아무런 경고도 없이 프로그램의 훨씬 뒤에서 문제가 발생하기 때문에 상당히 번거롭다. 이러한 종류의 의문이 있다면 -fno-common 플래그를 통해 여러번 정의된 전역 심볼이 있다면 에러를 명시적으로 발생시켜줄 수 있다.
'CS > OS' 카테고리의 다른 글
| 공유 라이브러리로 동적 링크하기 (load-time linking) (0) | 2022.12.05 |
|---|---|
| 링커가 정적 라이브러리를 통해 참조를 해석하는 방법 (0) | 2022.12.05 |
| Linker의 역할 - 2. Relocation(재배치) (0) | 2022.12.03 |
| 심볼과 심볼 테이블 (0) | 2022.12.02 |
| 정적 링킹과 목적 파일 (0) | 2022.12.02 |
링킹
링킹은 여러 개의 코드와 데이터를 모아 연결하여 메모리에 로드될 수 있고 실행될 수 있는 하나의 파일로 만드는 작업이다. 링킹은 컴파일 시에 수행될 수 있으며, 이때 소스 코드는 기계어로 변환된다. 프로그램이 메모리에 로드되고, 로더에 의해 실행될 수 있을때에는 로드 타임에, 응용 프로그램에 의해서 심지어 실행 시에도 수행될 수 있다. 초기 컴퓨터 시스템에서는 주로 수동으로 링킹이 이뤄졌지만, 현대의 시스템에서는 링커라고 부르는 프로그램에 의해 자동으로 수행된다.
다음의 예시를 통해 링커를 이해해보자.
/* main.c */
void swap();
int buf[2] = {1, 2};
int main()
{
swap();
return 0;
}/* swap.c */
extern int buf[];
int *bufp0 = &buf[0];
int *bufp1;
void swap()
{
int temp;
bufp1 = &buf[1];
temp = *bufp0;
*bufp0 = *bufp1;
*bufp1 = temp;
}앞서 작성된 프로그램은 두 개의 소스파일 main.c와 swap.c로 구성된다. main 함수는 두 원소를 갖는 int의 배열을 초기화하고, 이들을 교환하는 swap 함수를 호출한다.
해당 파일들을 메모리에 로드가 가능한 프로그램으로 변환하기 위해서는 컴파일러를 활용하여 먼저 각각의 소스파일을 .o 형태의 목적파일로 변환하고 이를 링커를 사용하여 하나로 묶는 작업이 필요하다. 그림으로 표현하면 다음과 같다.
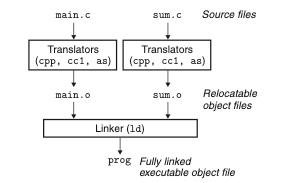
링킹의 장점
링킹의 장점을 나열하자면 다음과 같다.
모듈화
- 하나의 거대한 소스코드 대신에, 각각의 모듈로서 파일을 분리하므로 모듈화의 장점 (더 작은 단위로 관리, 라이브러리를 통해 반복된 코드 재사용 가능)을 얻을 수 있다.
효율성
- 하나의 소스 파일에 변경이 되었다면, 굳이 모든 소스를 다시 컴파일하는 대신, 해당 소스 파일만 다시 컴파일하고 이를 다시 re-link하면 된다.
- 라이브러리를 사용하기 때문에, 공통된 파일에 여러 함수들을 담아 둘 수 있으며, 실제 파일을 작성할 경우 라이브러리 함수를 가져와서 실제 사용될 라이브러리 함수와 본인 소스 코드만이 코드에 포함되게 된다.
'CS' 카테고리의 다른 글
| 정적 라이브러리 (0) | 2022.12.05 |
|---|---|
| 실행가능한 목적파일 (0) | 2022.12.03 |
| 시간 지역성을 위한 캐시 재배치 (0) | 2022.12.01 |
| 공간 지역성을 높이기 위한 루프 재배치 (2) | 2022.12.01 |
| 캐시 친화적 코드 작성하기 (0) | 2022.11.29 |
C언어에서 자주 사용하는 함수들을 패키징(하나로 묶음)하고 싶다면 어떻게 해야할까?
이를 수행하는 방법으로는 정적 라이브러리를 활용한 정적 링킹, 동적 라이브러리를 활용한 동적 링킹이 있다.
정적링킹
Unix ld와 같은 정적 링커들은 재배치 가능한 목적파일들과 명령줄 인자들을 입력으로 받아들여서 로드될 수 있고 실행될 수 있는 완전히 링크된 실행가능 목적파일을 출력으로 생성한다. 입력인 재배치가능 목적파일들은 다양한 코드와 데이터 섹션들로 이뤄져있다. 인스트럭션들은 한 개의 섹션에, 초기화된 섹션은 다른 섹션에, 초기화되지 않은 변수들은 또 다른 섹션에 들어 있다.
실행 파일을 만들기 위해서 링커는 다음의 두 가지 주요 작업을 수행해야 한다.
심볼 해석 symbol resolution
목적 파일들은 심볼들을 정의하고 참조한다. 심볼 해석의 목적은 각각의 심볼 참조를 정확하게 하나의 심볼 정의에 연결하는 것이다.
재배치 Relocation
컴파일러와 어셈블러는 주소 0번지에서 시작하는 코드와 데이터 섹션들을 생성한다. 링커는 이 섹션들을 각 심볼 정의와 연결시켜서 재배치하며, 이 심볼들로 가는 모든 참조들을 수정해서 이들이 이 메모리 위치를 가리키도록 한다.
이후에 오는 내용들은 앞서 설명한 두 가지 작업을 이해하기 위해 좀 더 상세하게 각 요소들을 설명한다.
다만 링커에 대해서 몇 가지 기억해야할 지점이 있는데, 목적파일들은 단지 바이트 블록들의 집합이라는 것이다. 이 블록들 중 일부는 프로그램 코드를 포함하고, 다른 블록들은 프로그램 데이터를, 또 다른 블록들은 링커와 로더를 안낸하는 데이터 구조를 포함한다. 링커는 블록들을 함께 연결하고 이 연결된 블록들을 위한 런타임 위치를 결정하며, 코드와 데이터 블록 내에 여러 가지 위치를 수정한다. 링커는 타켓머신에 대해 최소한의 지식과 함께 앞서 설명한 심볼 해석과 재배치 작업을 수행한다. 목적파일을 생성하는 컴파일러와 어셈블러는 이미 대부분의 작업을 마친 상황임을 기억하자.
목적 파일
목적 파일에는 세 가지 형태가 있다.
- 재배치가능 목적파일 Relocatable object file (.o)
포맷에 컴파일 시에 실행 가능 목적파일을 생성하기 위해 다른 재구성가능 목적파일들과 결합될 수 있는 바이너리 코드와 데이터를 포함한다. - 공유 목적파일 Shared object file (a.out)
로드타임 또는 런타임 시에 동적으로 링크되고 메모리에 로드될 수 있는 특수한 유형의 재배치가능 목적파일이다. - 실행가능 목적파일 Executable object file (.so)
메모리에 직접 복사될 수 있고 실행될 수 있는 형태로 바이너리 코드와 데이터를 포함한다.
컴파일러와 어셈블러는 재배치가능 목적파일을 생성한다(공유 목적 파일을 포함). 이후 생성된 재배치가능 목적파일을 가지고 링커는 실행가능한 목적파일을 생성한다. 기술적으로 하나의 목적 모듈은 바이트의 배열이며, 목적파일은 디스크에 파일로 저장된 목적모듈이다. 이 둘을 엄격하게 구분하여 표현하며 링커를 설명하는 경우도 있으나, 해당 글에서는 두 용어의 구분이 크게 의미가 없다고 판단하여 해당 용어들을 적절히 혼용할 예정이다.
목적파일의 포맷은 시스템에 따라 다른다. Bell Lab에서 개발된 최초의 Unix 시스템은 a.out 포맷을 사용한다. 리눅스에서 gcc을 통해 실행 파일을 생성해보면 해당 이름의 실행파일을 얻을 수 있는데 앞서 설명한 이유가 있었음을 알 수 있다. System V Unix는 초기 COFF(Common Object File Format)라는 포맷을 사용하였고, 윈도우 NT는 COFF의 변형인 PE(Portable Execution file)라는 포맷을 사용했다고 한다. 이 모든 것을 지나서 System V의 후기 버전, BSD Unix의 변종, 솔라리스는 ELF(Execuatble and Linkable Format)라는 포맷을 사용하며 현재 대부분의 OS에서 해당 파일 포맷을 따라 설계가 되어있다.
재배치가능 목적파일

앞선 그림은 전형적인 ELF 재배치가능 목적 파일의 포맷을 보여준다. ELF 헤더는 이 파일을 생성한 워드 크기와 시스템의 바이트 순서를 나타내는 16바이트 배열로 시작한다. ELF 헤더의 나머지는 링커가 목적파일을 구문분석하고 해석하도록 하는 정보가 포함된다. 여기에는 ELF 헤더의 크기, 목적파일 타입(ex. 재배치가능, 공유, 실행가능), 머신명령어타입(ex. IA32), 섹션 헤더 테이블의 파일 오프셋, 섹션 헤더 테이블이 크기와 엔트리 수가 들어 있다. 여러가지 섹션들의 위치와 크기는 섹션 헤더 테이블로 나타내며, 이 테이블은 목적 파일의 각 섹션에 대해 고정된 크기의 엔트리를 갖는다.
ELF헤더와 섹션헤더 테이블 사이에는 섹션 컨텐츠가 들어있는데, 전형적인 ELF 재배치가능 목적파일에는 다음과 같은 섹션들을 포함한다.
.text: 컴파일된 프로그램의 머신코드
.rodata: printf 문장의 포맷 스트링, switch문의 점프테이블과 같은 읽기-허용 데이터
.data: 초기화된 C 전역변수 (지역 변수는 런타임 시에 스택에 저장되어 별도의 섹션에 저장되지 않는다)
.bss: 초기화되지 않은 전역변수 (해당 섹션은 실제로 데이터를 저장하지는 않고 그러한 데이터가 위치한 공간의 위치를 나타내기만 한다. 굳이 초기화되지 않은 전역변수까지 목적파일에서 실제 디스크공간을 차지할 필요는 없다)
.symtab: 프로그램에서 정의되고 참조되는 전역변수들과 함수에 대한 정보를 가지고 있는 심볼 테이블. 일부 프로그래머들은 심볼 테이블 정보를 얻기위해 -g 옵션을 통해 컴파일을 해야한다고 잘못 이해해고 있으나 사실 모든 재배치가능 목적파일은 .symtab에 이미 심볼 테이블을 가지고 잇다. 그러나 컴파일러 내부에 위치한 심볼 테이블과 달리 링커 쪽의 심볼 테이블은 지역변수에 대한 엔트리를 가지고 있지 않다.
.rel.text: 링커가 이 목적 파일을 다른 파일과 연결할 경우 수정되어야 하는 .text 섹션 내의 위치들의 리스트. 일반적으로 외부 함수를 호출하거나 전역변수를 참조하는 인스트럭션은 모두 수정이 되어야 한다. 반면 지역 함수를 호출하는 인스트럭션은 수정될 필요가 없다. 재배치 정보는 실행 가능 목적파일에는 포함하지 않으며, 사용자가 링커에게 이것을 명시적으로 포함할라고 지시하기 전에는 대개 해당 정보는 빠진다는 점에 유의해야 한다.
.rel.data: 해당 모듈에 의해 정의되거나 참조되는 전역변수들에 대한 재배치 정보.
.debug: 프로그램 내에서 정의된 지역변수들과 typedef, 프로그램과 최초 C 소스 파일에서 정의되고 참조되는 전역변수들을 위한 엔트리를 갖는 디버깅 심볼 테이블. 컴파일러 드라이버가 -g 옵션으로 불린 경우에 생성된다.
.line: 최초 C 소스 프로그램과 .text 섹션 내 머신 코드 인스트럭션 내 라인 번호들 간의 매핑. 컴파일러 드라이버가 -g 옵션으로 불린 경우에만 생성된다.
.strtab: .symtab과 .debug 섹션 내에 있는 심볼 테이블과 섹션 헤더들에 있는 섹션 이름들을 위한 스트링 테이블. 스트링 테이블은 널 문자로 종료된 스트링의 배열이다.
왜 초기화 되지 않은 데이터는 .bss라고 불리는가?
이는 본래 IBM 704 어셈블리 언어의 "Block Storage Start" 인스트럭션에 대한 약어였으며 이 약어가 굳어진 것이다. .data와 .bss 섹션들의 차이를 기억하는 간단한 방법으로 "bss"를 "Better Save Space"에 대한 약어로 생각해도 좋다.
'CS > OS' 카테고리의 다른 글
| 공유 라이브러리로 동적 링크하기 (load-time linking) (0) | 2022.12.05 |
|---|---|
| 링커가 정적 라이브러리를 통해 참조를 해석하는 방법 (0) | 2022.12.05 |
| Linker의 역할 - 2. Relocation(재배치) (0) | 2022.12.03 |
| 심볼과 심볼 테이블 (0) | 2022.12.02 |
| Linker의 역할 - 1. Symbol Resolution (0) | 2022.12.02 |
c = (double *) calloc(sizeof(double), n*n);
/* Multiply n x n matrices a and b */
void mmm(double *a, double *b, double *c, int n) { int i, j, k;
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
for (k = 0; k < n; k++)
c[i*n + j] += a[i*n + k] * b[k*n + j];
}다음의 코드가 있다고 가정하자.
그리고 이해의 편의를 위해 추가적으로 다음도 가정한다.
- 각 배열은 double의 n x n 배열이며, sizeof(double) == 8 이다.
- 32바이트 블록 크기를 갖는 (B = 32) 단일 캐시를 가지고 있다.
- 배열 크기 n은 매우 커서 단일 행렬의 행은 L1 캐시에 들어가지 않는다.
- 컴파일러는 지역변수를 레지스터에 저장하고, 따라서 루프 내 지역변수에 대한 참조는 load나 store 연산을 사용하지 않는다(지역 변수의 load에는 메모리의 개입이 없다).
이때 A는 행 우선으로 stride-1 접근 패턴을 통해 스캔이 이뤄지는 반면, B는 열 우선으로 stride-n 접근 패턴으로 캐시의 의미가 퇴색된다.
때문에 A는 n / 8의 miss rate를 갖게 되며, B는 1의 miss rate를 갖게 된다. 총 9/8의 miss rate를 갖는다.
대신 내부적으로 mini block을 만들어서, 시간적으로 더 근처에 접근될 수 있도록 구성한다.
c = (double *) calloc(sizeof(double), n*n);
/* Multiply n x n matrices a and b */
void mmm(double *a, double *b, double *c, int n) {
int i, j, k;
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
for (k = 0; k < n; k++)
for (i1 = 0; i1 < i + B; i1++)
for (j1 = 0; j1 < j + B; j1++)
for (k1 = 0; k1 < k + B; k1++)
c[i1 * n + j1] += a[i1 * n + k1] * b[k1 * n + j1];
}
이렇게 되면 총 mini block이 n / B개가 생긴다. 또한 각각의 블록이 B / 8 * B 번의 miss가 발생하여 B^2 / 8 번의 miss가 발생한다.
최초 루프에서 (2n / B) * (B^2 / 8) 해서 nB/4의 miss rate가 나온다. 이후 second block iteration에서도 nB / 4 가 나오고 이는 블록의 수만큼 반복된다.
블록의 수는 (n / B) * (n / B) 이므로 최종적으로 블록의 수 x 초기 반복의 miss rate 해서 n^3 / 4B가 최종 miss rate가 된다.
'CS' 카테고리의 다른 글
| 실행가능한 목적파일 (0) | 2022.12.03 |
|---|---|
| Linking(링킹) 소개 (0) | 2022.12.02 |
| 공간 지역성을 높이기 위한 루프 재배치 (2) | 2022.12.01 |
| 캐시 친화적 코드 작성하기 (0) | 2022.11.29 |
| 캐시 성능 지표 (0) | 2022.11.29 |
행렬의 곱셈을 구하는 함수는 대개 세 개의 중첩된 루프를 사용하여 구현하며, 이들은 각각 인덱스 i, j, k로 식별된다. 이 루프들의 순서를 바꾸고 일부 코드를 수정하면, 하나의 동일한 행렬 곱을 수행하는 코드라고 하더라도 여러가지 코드 형태를 보일 수 있다. 이때 각각의 버전은 루프 순서에 의해 구분할 수 있다. 해당 글에서는 총 6가지의 버전을 비교하며 작성되었다.
상위 레벨에서는 어떤 버전으로 코드가 작성되었든 비슷하다. 만일 덧셈의 결합성이 성립한다면 각 버전들은 동일한 결과를 낼 것이다. (부동소수점 덧셈은 교환성은 성립되지만, 결합성이 성립되지 않는다는 점을 기억하자) 각 버전은 O(n^3)의 전체 연산을 수행하며, 동일한 수의 덧셈과 곱셈을 수행한다. A와 B의 n^2 개의 원소들은 n번 읽히게 될 것이며, C의 n^2개의 원소 각각은 n개의 값들을 더해서 계산될 것이다. 그러나 가장 안쪽 루프의 동작을 분석할 경우 접근 횟수와 지역성에 있어서 차이가 있음을 발견할 수 있다. 이 해석을 위해서 다음의 가정을 한다.
- 각 배열은 double의 n x n 배열이며, sizeof(double) == 8 이다.
- 32바이트 블록 크기를 갖는 (B = 32) 단일 캐시를 가지고 있다.
- 배열 크기 n은 매우 커서 단일 행렬의 행은 L1 캐시에 들어가지 않는다.
- 컴파일러는 지역변수를 레지스터에 저장하고, 따라서 루프 내 지역변수에 대한 참조는 load나 store 연산을 사용하지 않는다(지역 변수의 load에는 메모리의 개입이 없다).
들어가기에 앞서서
C의 array는 row-major하게 할당되어 있다.
때문에 column base로 접근하느냐 row base로 접근하느냐에 따라 Miss rate가 극단적으로 변화한다.
먼저 column이 변화하고 한 줄의 column을 다 읽었을때 새로운 row로 루프가 진행되는 경우를 살펴보자
for (i = 0; i < n; i++)
sum += a[0][i];이 경우에는 연속적인 원소에 접근하게 된다. 이 경우에 Miss rate가 가장 커지려면 블록의 사이즈가 원소의 사이즈보다 커서 공간 지역성을 활용할 수 있다. 이 경우의 miss rate는 다음과 같다.

전체 B 바이트를 읽을 때마다 (단일 매핑 캐시의 전체), sizeof(aij) 만큼의 캐시 미스가 발생하였다. 이때 sizeof(aij)는 모든 원소가 같은 크기라고 가정하였다.
반면, row를 가장 깊은 루프에서 변화시키며 한줄의 row를 다 읽었을 때 다음과 같이 새로운 column으로 루프가 진행될 경우, C의 배열 설계와 정반대로 가서 동떨어져 있는 배열 원소에 계속해서 접근하게 된다.
for (i = 0; i < n; i++)
sum += a[i][0]그리하여 공간 지역성이 성립이 되지 않아 Miss rate가 1이 되어 캐시를 사용하지 않는 것과 같은 역할을 수행한다.
# Case 1 (i- j-k)
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++) {
sum = 0.0
for (k = 0; k < n; k++)
sum += a[i][k] * b[k][j];
c[i][j] = sum;
}
}해당 케이스는 클래스 AB로 분류된다. (가장 안쪽의 루프에서 [i][k] -> [k][j] 로 이어지기 때문)
이때, a는 stride 1으로서 sizeof(a) / B의 miss rate 를 갖게 되고, 앞서 가정하였듯 블록의 크기가 32 바이트이므로 각각의 원소가 double(8 bytes)라는 점에서 0.25의 miss rate를 갖게된다.
b의 경우에는 stride n으로 스캔이 이뤄지기 때문에, 1의 miss rate를 갖는다.
총 1.25 번의 미스가 도출되었다.
# Case 2 (j- i-k)
for (j = 0; j < n; i++)
{
for (i = 0; i < n; j++) {
sum = 0.0
for (k = 0; k < n; k++)
sum += a[i][k] * b[k][j];
c[i][j] = sum;
}
}해당 코드는 직전의 Case #1과 동일한 클래스 AB로 분류된다. 앞서 a가 0.25의 miss rate를 갖던 것과 마찬가지로 stride 1으로 스캔이 이뤄져 0.25의 miss rate를 갖는다.
b의 경우도 앞의 이유에서처럼 stride n을 가지므로 1의 miss rate를 갖는다.
총 1.25 번의 미스가 도출되었다.
# Case 3 (j- k-i) 와 # Case 4 (k-j-i)
for (j = 0; j < n; j++)
{
for (k = 0; k < n; k++) {
r = B[k][j];
for (i = 0; i < m; i++)
C[i][j] += A[i][k] * r;
}
}for (k = 0; k < n; j++)
{
for (j = 0; j < n; k++) {
r = B[k][j];
for (i = 0; i < m; i++)
C[i][j] += A[i][k] * r;
}
}클래스 AC이다.
다음의 연산에는 두가지 문제가 있다. 앞서 클래스 AB가 load 연산만을 2번 사용했던 것과 달리 해당 코드에서는 store 연산 2번, load 연산 2번을 사용하고 있다.
또한 내부 루프에서 A와 C의 열들을 stride n으로 실행한다(가장 깊은 루프에서 i가 바뀌면서 루프 진행). 그 결과는 매 load마다(A와 C) 한 번의 미스(miss rate = 1)가 발생하여 총 2번의 미스가 매 실행마다 발생한다.
# Case 5 (i- k-j) 와 Case 6 (k-i-j)
for (i = 0; i < m; i++) {
for (k = 0; k < n; k++) {
r = A[i][k];
for (j = 0; j < n; j++)
C[i][j] += r * B[k][j];
}
}for (k = 0; k < n; k++)
{
for (i = 0; i < n; i++) {
r = A[k][i];
for (j = 0; j < n; j++)
C[i][j] = r * B[k][j];
}
}클래스 BC이다.
직전의 클래스 AC와 동일하게 2번의 load, store 연산이 각각 수행되고 있으나, 가장 깊은 루프에서 C와 B가 행우선으로 stride-1 접근 패턴을 적용하기 때문에 각각의 load 연산에서 0.25의 miss rate를 갖는다.
총 0.5의 miss rate를 갖는다.
'CS' 카테고리의 다른 글
| Linking(링킹) 소개 (0) | 2022.12.02 |
|---|---|
| 시간 지역성을 위한 캐시 재배치 (0) | 2022.12.01 |
| 캐시 친화적 코드 작성하기 (0) | 2022.11.29 |
| 캐시 성능 지표 (0) | 2022.11.29 |
| 실제 캐시 계층 구조의 해부 (0) | 2022.11.29 |
foo = "bar"
bar = $(foo) foo # dynamic (renewing) assignment
foo := "boo" # one time assignment, $(bar) now is "boo foo"
foo ?= /usr/local # safe assignment, $(foo) and $(bar) still the same
bar += world # append, "boo foo world"
foo != echo fooo # exec shell command and assign to foo
# $(bar) now is "fooo foo world"Magic variables
ut.o: src.c src.h
$@ # "out.o" (target)
$< # "src.c" (first prerequisite)
$^ # "src.c src.h" (all prerequisites)
%.o: %.c
$* # the 'stem' with which an implicit rule matches ("foo" in "foo.c")
also:
$+ # prerequisites (all, with duplication)
$? # prerequisites (new ones)
$| # prerequisites (order-only?)
$(@D) # target directory
Command prefixes
| - | Ignore errors |
| @ | Don’t print command |
| + | Run even if Make is in ‘don’t execute’ mode |
build:
@echo "compiling"
-gcc $< $@
-include .depend
Find files
js_files := $(wildcard test/*.js)
all_files := $(shell find images -name "*")
Substitutions
file = $(SOURCE:.cpp=.o) # foo.cpp => foo.o
outputs = $(files:src/%.coffee=lib/%.js)
outputs = $(patsubst %.c, %.o, $(wildcard *.c))
assets = $(patsubst images/%, assets/%, $(wildcard images/*))
More functions
$(strip $(string_var))
$(filter %.less, $(files))
$(filter-out %.less, $(files))
Building files
%.o: %.c
ffmpeg -i $< > $@ # Input and output
foo $^
Includes
-include foo.make
Options
make
-e, --environment-overrides
-B, --always-make
-s, --silent
-j, --jobs=N # parallel processing
Conditionals
foo: $(objects)
ifeq ($(CC),gcc)
$(CC) -o foo $(objects) $(libs_for_gcc)
else
$(CC) -o foo $(objects) $(normal_libs)
endif
Recursive
deploy:
$(MAKE) deploy2'CS > Linux OS' 카테고리의 다른 글
| malloc 처음부터 작성해보기 (0) | 2022.11.29 |
|---|