






해당 글은 malloc을 실제로 작성해보고 실제 할당이 이뤄지는 원리에 대해서 더욱 깊은 이해를 해보고자 하는 목적으로 작성되었습니다.
바로 본론으로 들어가봅시다.
malloc의 함수 프로토타입은 다음과 같습니다.
void *malloc(size_t size);
입력으로 바이트 수를 요구하고, 해당 크기의 메모리 블록에 대한 포인터를 반환합니다.
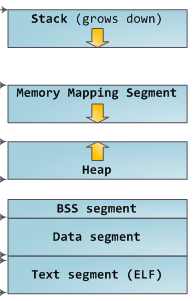
이를 구현할 수 있는 방법에는 여러가지가 있는데 해당 글에서는 sbrk를 사용하도록 하겠습니다. OS는 프로세스를 위한 스택 및 힙 공간을 예약하고, 이후 sbrk를 사용함으로써 유저는 힙을 조작할 수 있게 됩니다.
malloc을 가장 단순하게 구현한다면 다음과 같은 코드가 가능할 것입니다.
#include <assert.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
void *malloc(size_t size) {
void *p = sbrk(0);
void *request = sbrk(size);
if (request == (void*) -1) {
return NULL; // sbrk가 실패한 경우
} else {
assert(p == request); // thread-safe 하지 않은 경우
return p;
}
}
프로그램이 malloc에 공간을 요청할 때 malloc은 sbrk에게 힙 크기를 늘리도록 요청하고 힙으로부터 새 영역의 시작에 대한 포인터를 반환받게 됩니다.
이렇게 힙에 할당된 메모리는 메모리의 할당해제를 수행하는 free 함수를 통해 반환됩니다. free의 프로토타입은 다음과 같습니다.
void free(void *ptr);
free가 수행되면 앞서 malloc으로 반환된 포인터의 공간이 비워져야 합니다. 그러나 malloc에 의해 할당된 무언가에 대한 포인터가 주어지면 어떤 크기의 블록이 해당 할당과 연관되어 있는지는 알 수 없습니다. 해당 문제는 우리가 반환하는 포인터 바로 아래에서 멀리 떨어져 잇는 일부 공간에 메모리 영역에 대한 메타 정보를 저장함으로써 해결됩니다.
예를 들어 각 블록에 대해서 다음의 정보를 저장할 수 있을 것입니다.
struct block_meta {
size_t size; // 블록의 크기
struct block_meta *next; // 다음 블록의 위치
int free; // 할당 해제 여부
}
또한 연결된 블록에 대한 Head도 정의되어야 합니다.
void *global_base = NULL;
malloc 의 경우 가능하면 여유 공간을 재사용하고 기존 공간을 재사용할 수 없는 경우에만 공간을 할당합니다. 우리가 연결 리스트 구조를 가지고 있다는 점을 감안하면, 빈 블록이 있는지 여부를 확인하고 반환하는 것은 간단합니다. 어느 정도 크기의 요청을 받으면 연결된 목록을 반복하여 충분히 큰 여유 블록이 있는지를 확인합니다.
struct block_meta *find_free_block(struct block_meta **last, size_t size) {
// last: 마지막으로 참조된 블록 정보
// size: 할당하고자 하는 사이즈
struct block_meta *current = global_base;
while (current && !(current->free && current->size >= size)) {
*last = current;
current = current->next;
}
return current;
}
만약 사용가능한 블록을 찾지 못한다면 sbrk를 사용하여 OS에 공간을 요청하고 새 블록을 연결 목록 끝에 추가해야 합니다.
#define META_SIZE sizeof(struct block_meta)
struct block_meat *request_space(struct block_meta *last, size_t size) {
struct block_meta *block;
block = sbrk(0);
void *request = sbrk(size + META_SIZE);
assert((void *)block == request); // thread sagfe 하지 않은 경우
if (request == (void *) -1) {
return NULL; // sbrk를 통한 블록 할당 실패
}
if (last) {
last->next = block; // 만약 마지막 블록 정보가 매개변수로 들어왔다면, 이어 붙어줌
}
block->size = size; // 블록의 메타데이터에 size 정보를 저장
block->next = NULL; // 블록의 메타데이터에 마지막 블록임을 표시
block->free = 0; // 블록의 메타데이터에 할당되었음을 표시
return block;
}
앞서 작성한 함수들을 종합하게 되면 여유 공간이 있는지를 확인하고 공간을 요청할 수 있게 되어 malloc을 작성할 준비가 완료되었습니다. 만약 HEAD 포인터인 global_base가 NULL인 경우 공간을 요청하고 기본 포인터를 새 블록으로 설정해야 합니다.
반대로 HEAD 포인터가 실제 블록의 메타데이터를 가리키고 있다면 기존 공간을 재사용할 가능성이 있는지를 검사해야 합니다. 이떄 재사용이 가능하다면 재사용을 할 것이고, 그렇지 않다면 새로운 공간을 할당하게 될 것입니다.
void *malloc(size_t size)
{
struct block_meta *block; // 블록의 메타데이터를 저장할 구조체 포인터
if (size <= 0) // 할당하려는 블록의 크기가 0보다 작다면 NULL 반환
return NULL;
if (global_base == NULL) { // global_base가 NULL이라면, 즉 처음 malloc을 호출했다면
block = request_space(NULL, size); // request_space를 통해 블록 할당
if (!block) { // 할당에 문제가 있었다면
return NULL; // 종료
}
global_base = block; // global_base에 할당된 블록의 메타데이터를 저장
} else {
struct block_meta *last = global_base;
block = find_free_block(&last, size); // global_base부터 시작하여, size만큼의 빈 블록을 찾음
if (!block) { // 빈 블록을 찾지 못했다면
block = request_space(last, size); // request_space를 통해 블록 할당
if (!block) { // 할당에 문제가 있었다면
return NULL; // 종료
}
} else { // 빈 블록을 찾았다면
block->free = 0; // 블록의 메타데이터에 할당되었음을 표시
}
}
}
'CS > Linux OS' 카테고리의 다른 글
| Makefile cheatsheet (0) | 2022.11.30 |
|---|

가상현실(VR)
VR은 Virtual Reality의 약자로 가상현실이라고 한다. 우리가 살고 있는 물리적인 공간이 아닌 컴퓨터로 구현한 가상 환경 또는 그 기술 자체를 말한다. 사용자의 주변 환경을 차단해 새로운 세계로 들어간 것처럼 몰입감을 주는 것이 핵심이라서 머리에 쓴는 디스플레이 디바이스 HDM을 활용해 현실 세계와 차단하는 콘텐츠가 주를 이룬다. 일상생활은 물론 IT, 의료, 제조, 자동차, 음악, 쇼핑, 게임 분야 등 다양한 부문에서 기술적인 성장을 이어나가고 있다.
증강현실(AR)
AR은 Augumented Reality의 약자로 증강현실이라고 한다. VR과 달리 위치, 지리정보를 송수신하는 GPS 장치 및 중력 그리고 자이로스코프에 따른 위치정보 시스템을 기반으로 우리가 경험하는 현실 세계에 가상의 물체나 정보가 합성되어 실제 현실을 가상현실과 상호작용이 이뤄지는 공간으로 만들어주는 기술이다. 사용자가 보고 있는 실사 영상에 3차원 가상 영상을 중첩함으로써 현실과 가상의 구분이 모호한 것이 특징이다. 최근에는 산업용 증강현실이라는 이름으로 제조, 유통, 의료현장 등에서도 많이 활용되고 있고 앞서 얘기한 포켓몬 게임이나 구글 글라스가 대표적이다. 증강현실을 적용한 네비게이션의 경우 실제 도로장면에 주행 정보를 추가해서 보여주기도 하고, 의류 매장에서 직접 옷을 입어보지 않고도 화면 상에서는 입은 것 같은 시스템을 구현해준다. 또한 스마트폰 앱으로 많이 사용하고 있는 스노우는 증강현실 기술을 활용한 대표적인 카메라 앱이다.
혼합현실(MR)
MR은 VR이나 AR보다 한 단계 더 나아간 기술인데 Mixed Reality의 약자로 혼합현실을 말한다. VR과 AR 두 기술의 장점만을 합친 기술로 MR은 현실과 가상의 정보를 융합해 조금 더 진화된 가상세계를 구현하고 냄새 정보와 소리 정보를 융합하여 사용자가 상호작용할 수 있는 기술을 말한다. VR과 AR은 시각에 전적으로 의존하지만 MR은 시각 외에 청각, 촉각 등 인간의 오감을 접목시킬 수 있다는 점이 다르다.
마이크로소프트에서 나온 홀로랜즈는 자신이 위치한 현재의 공간을 3차원 스캔할 수 있고 스마트폰이나 PC와 연결할 필요없이 단독 구동이 가능하다. 홀로랜즈를 착용하면 먼 거리에 떨어져있는 사람과도 한 자리에 있는 것처럼 자연스럽게 회의를 진행할 수 있다. 현재 MR 기술은 사람의 귀가 아닌 다른 방법을 통해 소리를 전달하는 기술도 개발되고 있으며 촉각을 활용한 햅틱과 팁톡의 기술도 나오고 있다. 국내의 경우 SK 텔레콤이 혼합현실 제작소 점프 스튜디오를 가동, 온라인 라이브 공연에 처음으로 활용하기도 했다.
확장현실(XR)
ER 혹은 XR이라고도 불리는 확장현실은 Extended Reality의 약자로 컴퓨터 기술로 인한 현실-가상 세계의 결합과 인간-기계의 상호 작용을 말한다. 가상현실과 증강현실, 혼합현실을 포괄적으로 XR이라고도 한다. XR은 MR에서 확장된 개념으로 볼 수도 있다. 현실과 가상 간의 상호 작용을 강화해 현실 공간에 배치된 가상의 물체를 손으로 만질 수 있다. 코로나19와 같은 상황 하에 글로벌 원격 회의를 할 때 각 국가나 회사 출근 여부에 상관없이 XR은 하나의 디지털 공간에 자료를 띄워서 공유할 수 있다. 따라서 XR은 위험에 빠질 수 있는 상황이나 재료의 낭비없이 교육이나 훈련을 시뮬레이션으로 할 수 있는 의료, 제조 및 군사산업 등에서 활용할 수 있다.
'etc' 카테고리의 다른 글
| Digital Twin (디지털 트윈) (0) | 2022.11.29 |
|---|

디지털 세계와 물리적 제품 사이의 경계가 모호해짐에 다라 4차 산업 혁명의 최전선에서는 빅데이터, 머신러닝, 가상 현실과 같은 "스마트" 기술 애플리케이션이 등장하였다. 일반적으로 디지털 트윈은 물리적 자산, 시스템 또는 프로세스를 소프트웨어로 표현하는 것을 의미하며, 실시간 분석을 통해 대상을 감지 예방, 예측 및 최적화하여 비즈니스 가치를 제공하는 역할을 수행한다. 즉 가상의 공간에 '진짜 세상'의 복제를 만드는 것을 의미한다.
Digital Twin의 예시 ( 항공기 제작 및 정비)
실제 항공기에서는 실제 제품 환경 및 작동 조건의 다양한 측면을 모니터링하는 센서의 데이터를 사용하여 지속적으로 학습하고 업데이트되며, 이전에 담아두었던 데이터를 활용하여 실제 물리적인 요소의 개선을 이뤄낸다.
만약 엔지니어링 측면에서 Digital Twins를 사용하면 확률 기반 기술에 의존하여 엔진 유지 보수 또는 수리가 필요한 시기를 결정할 필요성이 줄어들게 된다. 대신 앞서 소개한 다양한 4차 산업 기술을 활용하여 디지털 트윈의 개념을 도입, 실제 제품의 정확한 가상 사본인 엔진의 디지털 트윈을 생성하게 된다면 실제 엔진이 날개를 펼침과 동시에 가상 세계에서도 이를 인지하고 엔진 작동 방식을 결정하게 된다. 또한 데이터를 활용하게 되어 유지보수가 필요한 시기를 미리 예측할 수 있게되어 예방적인 엔진 유지 보수를 할 수 있ㄷ어 항공기의 가동 중지 시간을 크게 줄이고 항공기 운항 측면에서의 안정성을 높일 수 있게 된다.
또한 항공기 부품에 대한 이해와 조작에 대해서도 디지털 트윈을 활용한다면 훨씬 고수준의 접근이 가능하다. 항공정비를 배우는 학생에게는 이러한 디지털 트윈은 본인 기술을 향상시킬 수 있는 기회로 작용한다. 실제 비행기 모델을 통해 학습을 진행할 수도 있지만, 이는 비용이 많이 들 뿐만 아니라 실제 코어한 부분까지 알기는 쉽지 않다. 물론 부분부분 각 요소가 어떻게 생겼는지는 구경할 수 있을지는 모르지만 전체적으로 어떤 구조로 이뤄져있는지 이해하는 것은 기존 교육만으로는 한계가 있다. 디지털 트윈은 항공기 내부를 그대로 디지털 세계로 옮겨 물리적인 한계를 넘어서게 할 수 있다. 교육생들은 디양한 조작법을 활용하여 실제 사이즈의 비행기를 가상 환경을 통해 접할 수 있을 것이다.
실제 정비 또한 디지털 트윈에서 사용하는 데이터 분석을 활용하여 물리적 엔진 테스트가 허용하는 것보다 더 많은 잠재적 시나리오를 모델링할 수 있으므로 더 많은 이해가 가능해진다.
'etc' 카테고리의 다른 글
| VR의 발전과 분류 (0) | 2022.11.29 |
|---|
지역성
잘 작성한 컴퓨터 프로그램은 좋은 지역성을 보여준다. 즉 이들은 다른 최근에 참조했던 데이터 아이템 근처의 데이터 아이템이나 최근에 자신이 참조했던 데이터 아이템을 참조하려는 경향이 있다. 지역성의 원리라고 알려진 이러한 경향은 하드웨어와 소프트웨어 시스템의 성능과 설계에 엄청난 영향을 주는 지속적인 개념이다.
지역성은 일반적으로 두 개의 서로 다른 형태를 가지는 것으로 설명된다.
시간 지역성
좋은 시간 지역성을 갖는 프로그램에서는 한번 참조된 메모리 위치는 가까운 미래에 다시 여러 번 참조될 가능성이 높다.
공간 지역성
좋은 공간 지역성을 갖는 프로그램에서는 만일 어떤 메모리 위치가 일단 참조되면, 이 프로그램은 가까운 미래에 근처의 메모리 위치를 참조할 가능성이 높다.
캐시 친화적 코드 작성하기
앞서 소개한 지역성 개념에 따르면 더 나은 지역성을 갖는 프로그램들은 더 낮은 미스 비율을 갖게 되며, 더 낮은 미스 비율을 갖는 프로그램들은 높은 미스 비율을 보이는 프로그램보다 더 빨리 실행되는 경향을 보인다. 따라서 좋은 프로그래머란 항상 캐시 친화적으로, 즉 좋은 지역성을 가지도록 프로그램을 작성해야 한다.
다음은 코드가 캐시 친화적이게 만들기 위해 사용할 수 있는 기본적인 방법들이다.
- 공통적인 경우를 빠르게 동작하도록 만들어라
프로그램들은 대개 대부분의 시간을 몇 개의 핵심 함수들에서 소모한다. 이 함수들은 대부분의 시간을 몇 개의 루프에서 보낸다. 그래서 핵심 함수들의 내부 루프에 집중하고 나머지는 무시한다. - 각 내부 루프의 캐시 미스 수를 최소화하라
Load와 Store 연산의 총수가 같다는 등의 다른 것들이 동일하다면 우수한 미스 비율을 갖는 루프들이 더 빨리 동작한다.
이를 다음의 실제 코드와 함께 이해해보자.
int sumvec(int v[n])
{
int i, sum = 0;
for (i = 0; i < n; i++)
sum += v[i];
return sum;
}해당 함수가 캐시 친화적인지 여부를 따지기 앞서서, 먼저 지역변수 i와 sum에 대해서 루프 본체는 좋은 시간 지역성을 갖는다는 점에 주목해야 한다. 사실 이들은 지역변수이기 때문에 어느정도의 최적화 컴파일러라면 이들을 레지스터 파일, 즉 메모리 계층 구조의 최상위 계층에 이들을 캐싱할 것이다.
이제 벡터 v에 대한 stride-1 참조에 대해 생각해보자. 일반적으로, 만일 어떤 캐시가 B 블록의 크기를 갖는다면, stride-k 참조 패턴(이때 k는 워드 수)은 루프 반복 실행당 min[1, (wordsize x k) / B]의 평균 미스 횟수를 나타낸다. 이는 k = 1인 경우 최소 값을 가지며, 그래서 v에 대해 stride-1 참조는 실제로 캐시 친화적이다.
예를 들어 v가 블록 단위로 정렬되어 잇으며 워드들은 4 바이트, 캐시 블록은 4 워드이고, 처음에 캐시는 cold cache(비어 있는 상태)라고 가정하자. 그러면 캐시 구성과는 상관없이 v에 대한 참조는 다음과 같은 적중과 미스 패턴을 갖는다.

요약하자면 sumvec 함수는 캐시 친화적인 코드를 작성하는 것에 관해 두 가지 중요한 점들을 보여준다.
- 지역 변수들에 대한 반복적인 참조는 좋으며, 그 이유는 컴파일러가 이들을 레지스터 파일에 캐싱할 수 있기 때문이다. (시간 지역성)
- Stride-1 참조 패턴은 좋으며, 그 이유는 메모리 계층 구조의 모든 레벨에서 데이터를 연속적인 블록들로 저장하기 때문이다. (공간 지역성)
공간 지역성은 특히 다차원 배열에 대해 연산을 수행하는 프로그램에서 중요하다. 예를 들어, 아래 코드의 sumarrayrows 함수에 대해서 생각해보자. 이 함수는 이차원 배열의 원소들을 행우선 순서로 더하는 함수이다.
int sumarrayrows(int a[m][n])
{
int i, j, sum = 0;
for (i = 0; i < m; i++) {
for (j = 0; j < n; j++)
sum += a[i][j];
}
return sum;
}C가 배열들을 행 우선 순서로 저장하므로, 이 함수의 내부 루프는 sumvec과 동일한 바람직한 stride-1 접근 패턴을 가진다. 예를 들어 sumvec에서와 같이 캐시에 관해서 동일한 가정을 한다고 하자. 그러면 배열 a에 대한 참조들은 다음과 같은 적중과 미스 패턴을 가진다.

그러나 만일 루프 실행 순서를 열 우선 순서로 변경할 경우 캐시 패턴에 문제가 발생한다.
int sumarraycols(int a[m][n])
{
int i, j, sum = 0;
for (j = 0; j < m; i++) {
for (i = 0; i < n; j++)
sum += a[i][j];
}
return sum;
}
이 경우에 행 대신에 열 우선으로 배열을 탐색하고 있다. 만일 운이 좋아서 전체 배열이 캐시에 모두 들어간다면 같은 미스 비율로 1/4를 갖게 될 것이다. 그러나 만일 배열의 크기가 캐시보다 더 크다면, 각각의 모든 a[i][j]에 대한 접근은 미스가 된다.
'CS' 카테고리의 다른 글
| 시간 지역성을 위한 캐시 재배치 (0) | 2022.12.01 |
|---|---|
| 공간 지역성을 높이기 위한 루프 재배치 (2) | 2022.12.01 |
| 캐시 성능 지표 (0) | 2022.11.29 |
| 실제 캐시 계층 구조의 해부 (0) | 2022.11.29 |
| Write 관련 캐시 이슈 (0) | 2022.11.29 |
Miss Rate
프로그램 또는 프로그램의 일부를 실행하는 동안 미스하는 메모리를 참조하는 비율. misses / references로 계산된다.
Hit rate
적중한 메모리 참조의 비율. 1 - miss rate로 계산된다.
Hit Time
캐시 집합의 선택, 라인 식별,워드 선택을 모두 고려하여 캐시에 있는 워드를 CPU로 전달하는데 걸리는 시간. (L1 캐시의 경우 몇 클럭 사이클 단위를 갖는다. 직전의 i7 아키텍쳐에서는 4 사이클이라고 명시되어 있다.)
Miss Penalty
캐시 미스로 인하여 추가적으로 요구되는 시간. L2로부터 L1 미스를 서비스하는데 걸리는 비용은 10 사이클 정도이다. L3에서는 40 사이클, 메인 메모리에서는 100 사이클이다.
캐시 메모리의 비용과 성능의 절충 과정을 최적화하는 것은 실제적인 벤치마크 코드와 함께 광범위한 시뮬레이션을 요구하는 까다로운 문제이며, 이는 해당 글의 범위를 넘어선다.
논의해볼 만한 내용
앞서 여러 캐시의 성능을 측정하는 여러 지표들을 살펴봤지만, 그 중 가장 많이 사용되는 지표는 miss rate이다. 이 경우 가장 많이 비교되는 지표는 hit rate인데, 두 지표로 도출되는 결과에 어떤 차이가 있는지를 위주로 살펴보고자 한다.
먼저, 설명의 편의를 위해 다음의 시나리오를 가정해보자.
- Hit time: 1 cycle
- Miss penalty: 100 cycle
이때 Hit rate가 99%인 캐시 A와 Hit rate가 97%인 캐시 B가 있다고 하자.
97 %의 적중률을 갖는 캐시 A는 평균적인 Access time으로 1 사이클 + 0.03 * 100 사이클을 갖는다. 계산해보면 4 사이클이 도출된다.
99 %의 적중률을 갖는 캐시 B는 평균적인 Access time으로 1 사이클 + 0.01 * 100 사이클을 갖는다. 계산해보면 2 사이클이 도출된다.
결과적으로 99%의 적중률을 가졌던 캐시 A가 97%의 캐시 B보다 2배에 달하는 성능을 보여준다. 이는 hit의 경우 사실상 전체적인 Access time에 그리 영향을 미치지 않으나, 계산에 너무 크게 반영을 했기 때문이고, 반대로 miss의 경우에는 Access time 계산에서 대부분을 차지하지만 충분히 반영되지 못했기 때문이다.
해당 결과로부터 Hit rate로 표현된 지표가 직관적이지 않음을 캐치할 수 있다. 때문에 Hit rate보다는 Miss rate가 주요한 지표로서 사용되게 된다.
'CS' 카테고리의 다른 글
| 공간 지역성을 높이기 위한 루프 재배치 (2) | 2022.12.01 |
|---|---|
| 캐시 친화적 코드 작성하기 (0) | 2022.11.29 |
| 실제 캐시 계층 구조의 해부 (0) | 2022.11.29 |
| Write 관련 캐시 이슈 (0) | 2022.11.29 |
| Set Associative Cache (집합결합성 캐시) (0) | 2022.11.28 |
지금까지 캐시가 오직 프로그램 데이터만을 보관한다고 가정해 왔다. 그러나 사실 캐시는 데이터 뿐만 아니라 인스트럭션들도 저장할 수 있다. 인스트럭션을 저장하는 캐시는 i-cache라고 한다. 반대로 프로그램 데이터만을 보관하는 캐시는 d-cache라고 한다. 현대 프로세서들은 분리된 i-cache와 d-cache를 가지고 있다. 여기에는 여러가지 이유가 있다.
두 개의 별도의 캐시가 있으면 프로세서는 인스트럭션 워드와 데이터 워드를 동시에 읽을 수 있다. i-cache는 보통 읽기만 허용되며 따라서 좀 더 단순하다. 이 두 캐시는 종종 다른 접근 패턴에 대해 최적화되며 블록 크기, 결합도, 용량 등에 있어서 서로 다른 값을 갖는다. 또한 분리된 캐시를 가지기 때문에 데이터 접근이 인스트럭션 접근과 충돌 미스를 발생시키지 않으며 그 반대도 마찬가지이다. 대신 수용할 수 있는 용량은 줄어들었기에 용량 미스의 가능성은 잠재적으로 증가한다.

위 그림은 인텔 i7 프로세서에 대한 캐시 계층 구조를 나타낸다. 각 CPU 칩은 4 개의 코어를 가지고 있다. 각 코어는 자체적인 L1 i-cache, L1 d-cache, L2 통합 캐시를 가지고 있다.
그리고 모든 코어들은 하나의 L3 통합 캐시를 서로 공유한다. 한 가지 흥미로운 점은 이 계층 구조의 특징은 모든 SRAM 캐시 메모리들이CPU 칩 내에 들어 있다는 점이다.
'CS' 카테고리의 다른 글
| 캐시 친화적 코드 작성하기 (0) | 2022.11.29 |
|---|---|
| 캐시 성능 지표 (0) | 2022.11.29 |
| Write 관련 캐시 이슈 (0) | 2022.11.29 |
| Set Associative Cache (집합결합성 캐시) (0) | 2022.11.28 |
| Directed Mapped Cache (직접매핑 캐시) (0) | 2022.11.28 |
앞에서 살펴본 것처럼 읽기에 관한 캐시의 동작은 단순하다.
먼저 원하는 워드 w의 사본을 캐시에서 찾는다. 만일 hit이 발생하면 w를 즉시 리턴한다. 만일 미스가 발생하면, 메모리 계층 구조의 다음 하위 레벨에서 w를 포함하고 있는 블록을 선입(이 경우 유효한 라인 하나를 희생해야 할 수도 있다)해서 이 블록을 같은 캐시 라인에 저장하고 w를 리턴한다.
쓰기는 상황이 좀더 복잡하다. 이미 캐시에 들어 있는 (쓰기 적중write hit) 워드 w에 새로운 데이터를 쓰려고(Write) 한다고 가정하자.
특정 레벨에 위치한 캐시의 w에 대한 자신의 사본이 갱신되었다면, 계층구조의 다음 하위 레벨에 있는 w의 사본도 갱신이 되어야 한다.
Write-through라고 알려진 가장 간단한 방법은 업데이트가 발생하는 즉시, 캐시의 변경과 함께 w의 캐시 블록 전체를 다음 하위 레벨로 써주는 것이다. 간단하기는 하지만 Write-through 방법은 매 쓰기 작업마다 하위 레벨로의 버스 트래픽을 발생시킨다는 단점이 있다. 이 경우에는 데이터에 업데이트가 발생하면 모든 저장장치로 전파되기 때문에 항상 모든 레벨에서 최신 데이터에 접근할 수 있게 된다. (write data immediately to memory)
Write-back이라고 알려진 또 다른 방법은 갱신을 가능한 한 지연시켜서, 이 블록이 블록 교체 알고리즘에 의해 캐시에서 축출될 때에만 갱신된 블록을 하위레벨에 써준다. 지역성으로 인해 write-back은 버스 트래픽을 상당히 줄일 수 있지만, 좀더 복잡하다는 단점이 있다. 이 경우에는 각 저장 장치에 위치한 데이터들이 최신 상태의 데이터인지 알 수가 없다. 때문에 캐시는 캐시 블록이 수정되었는지 여부를 나타내는 dirty bit를 각 라인마다 추가로 유지하여야 한다는 단점이 있다.. (check dirty-bit and defer the write until replacement)
또 한가지 이슈는 쓰기 미스write miss들을 어떻게 다루는지이다. 쓰기 미스를 짧게 설명하자면 다음과 같다.
캐시에 쓰려고 할 때 블록을 쓰려는 전체 메모리 주소(A)가 있을 것이다. 캐시를 사용하기 앞서서 먼저 메모리 주소에서 캐시 인덱스를 계산하고 이는 캐시 집합의 위치를 알려주는 용도로 사용된다. 그 다음으로는 해당 메모리 주소의 Tag bits를 계산한다. Tag bit는 해당 블록을 식별할 수 있는 일종의 ID로서 활용된다.
여기서부터는 읽기 동작과 동일하다. 캐시 인덱스를 통해 특정 캐시 집합에 접근한 이후, Tag bits와 Valid bit를 활용하여 쓰고자 하는 블록의 태그와 캐시의 태그가 일치하는지 여부를 Valid bit와 함께 판단한다. 만약 이때, Tag bits가 맞지 않거나 Valid bit가 0이 된다면 '쓰기 미스'가 발생했다고 볼 수 있다.
쓰기 미스를 다루는 첫 번째 방법은 Write-allocate이다. 해당 방법은 해당 블록을 다음 하위 레벨에서 캐시로 가져오고 난 이후 캐시 블록을 갱신한다. Write-allocate는 쓰기 공간의 지역성을 활용하지만, 모든 미스들은 다음 하위 레벨에서 캐시로의 블록 전송을 발생시키기 때문에 연속된 캐시 갱신을 위해 버스 트래픽이 발생한다.
쓰기 미스를 다루는 두 번째 방법은 No-write-allocate이다. 해당 방법에서는 캐시를 통과하고 워드를 직접 다음 하위 레벨 저장 장치에 써준다. Write-through 캐시는 전형적인 no-write-allocate라고 볼 수 있다. Write back 캐시는 대개 write-allocate 방식이다.
어느 정도 수준의 캐시 친화적 프로그램을 작성하려는 프로그래머들에게는 write back && write allocate 조합을 추천한다. 이렇게 제안하는 이유는 다음과 같다.
규칙으로 , 메모리 계층 구조의 하위 레벨이 있는 캐시는 더 긴 전송 시간 때문에 write through 대신에 write-back을 사용할 가능성이 좀더 높다. 예를 들어 가상 메모리(swap을 활용하는) 시스템은 write back을 사용한다. 그러나 로직의 밀도가 증가함에 따라 write-back의 증가된 복잡도는 이전보다 작은 장애물이 되어, 현대의 시스템에서는 모든 수준에서 Write-back && Write-allocate를 볼 수 있다.
'CS' 카테고리의 다른 글
| 캐시 성능 지표 (0) | 2022.11.29 |
|---|---|
| 실제 캐시 계층 구조의 해부 (0) | 2022.11.29 |
| Set Associative Cache (집합결합성 캐시) (0) | 2022.11.28 |
| Directed Mapped Cache (직접매핑 캐시) (0) | 2022.11.28 |
| 기본 cache memory 구조 (0) | 2022.11.28 |
직접매핑 캐시의 충돌 미스 문제는 각 집합이 정확히 하나의 라인만을 갖는다는 제한에서 오는 것이다(즉 E = 1). 집합 결여성 캐시는 이 제한을 완화해서 각 집합이 하나 이상의 캐시 라인을 갖는다. 1 < E < C / B인 캐시는 E-way 집합결합성 캐시라고 부른다.
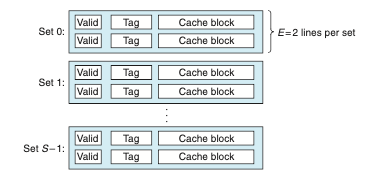
집합결합성 캐시에서 집합의 선택
캐시 집합을 선택하는 과정은 직접매핑 캐시와 동일하며, 집합 인덱스 비트 s는 집합을 나타내게 된다.

집합 결합성 캐시에서 라인 매칭과 워드 선택
라인 매칭은 직접매핑 캐시보다 집합 결합성 캐시에서 더 복잡한데, 그 이유는 요청한 워드가 집합에 있는지 결정하기 위해서 여러 개의 라인들의 태그와 유효비트를 조사해야 하기 때문이다. 보통의 메모리는 값들의 배열로, 주소를 입력으로 받아서 해당 주소에 저장된 값을 리턴해준다. 결합성 메모리는 반대로 (key, value) 쌍의 배열로, 키를 입력으로 받아서 (key, value) 쌍들 중에서 입력 키와 매칭되는 쌍에 있는 값을 리턴한다. 그래서 집합결합성 캐시의 각 집합을 "키가 태그와 유효비트가 결합된 형태이고, 블록의 내용을 값으로 가지는 하나의 작은 결합성 메모리"로 간주할 수 있다. (key = Valid bit + Tag bits, Value = block의 content)

위의 그림은 집합결합성 캐시에서 라인 매칭하는 기본 개념을 보여준다. 여기서 중요한 개념 한 가지는 집합의 모든 라인은 해당 집합에 매핑하는 어떤 메모리 블록도 다 포함할 수 있다는 것이다. 그래서 캐시 내의 태그와 주소의 내의 태그가 일치하는 유효한 라인을 찾기 위해 해당 집합의 각 라인을 탐색해야 한다. 만일 캐시가 이러한 라인을 찾아내면, 적중이 된 것이며 블록 오프셋은 이전처럼 블록 내 워드를 선택한다.
집합결합성 캐시에서 미스 발생 시 라인의 교체
만일 CPU가 요청한 워드가 해당 집합의 라인 어디에도 저장되어 있지 않다면, 미스가 발생한 것으로 캐시는 해당 워드를 포함하는 블록을 메모리에서 선입해야 한다. 그러나 일단 캐시가 그 블록을 가져오면, 어떤 라인을 교체해야할지를 결정해야 한다. 물론, 만일 비어있는 라인이 있다면 이 라인이 적절한 후보가 될 수 있겠으나 집합에 비어있는 라인이 없다면 비어 있지 않은 라인 중에서 하나를 선택해야 하며, CPU가 가까운 시간 내에 교체되어 사라져버린 라인을 참조하지 않기를 기대해야 한다.
프로그래머들이 자신의 코드에서 캐시 교체 정책에 대한 지식을 활용하는 것은 매우 어렵기 때문에, 해당 글에서는 자세한 내용을 다루지는 않을 것이다. 가장 간단한 교체 정책은 랜덤으로 교체할 라인을 선택하는 것이다. 좀더 복잡한 다른 방법들은 교체된 라인이 가까운 미래에 참조될 확률을 최소화하고자 시도하는 일환으로 지역성의 원리를 사용한다. 예를 들어 최소 빈도 사용 least-frequently-used LFU 정책은 과거의 일정 시간 구간 동안에 가장 적은 횟수로 참조된 라인을 교체한다. 최소 최근 사용 least-recently-used LRU 정책은 과거 마지막 사용 시점이 가장 오래된 라인을 교체한다. 이 정책은 모두 추가적인 시간과 하드웨어 모두를 필요한다. 그러나 우리가 메모리 계층구조를 CPU와 멀어지는 방향으로 좀더 아래로 내려가면 미스의 비용이 더욱 비싸지고, 때문에 상위 계층의 저장 장치에서 좋은 교체 전략을 통해 미스를 최소화하는 것이 중요해진다.
'CS' 카테고리의 다른 글
| 실제 캐시 계층 구조의 해부 (0) | 2022.11.29 |
|---|---|
| Write 관련 캐시 이슈 (0) | 2022.11.29 |
| Directed Mapped Cache (직접매핑 캐시) (0) | 2022.11.28 |
| 기본 cache memory 구조 (0) | 2022.11.28 |
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |