







캐시는 집합 S 당 캐시 라인의 수 E에 의해 서로 다른 클래스로 구분된다. 집합 당 정확히 1개의 라인을 갖는 경(E = 1)는 직접 매핑 캐시라고 알려져 있다. 직접매핑 캐시는 가장 이해하기 쉽고 구현하기 쉬워서 이 캐시를 사용해서 캐시가 동작하는 방법에 대한 일반적인 개념들을 설명하고자 한다.
우리에게 CPU, 레지스터 파일, L1 캐시, 메인 메모리를 갖는 시스템이 주어졌다고 하자. CPU가 메모리 워드 w를 읽는 인스트럭션을 실행할 때, 이 워드를 L1 캐시에서 요청한다. 만일 L1 캐시가 w의 복사본을 가지고 있다면 L1 캐시 적중이 되고, 캐시는 빠르게 w를 뽑아내서 CPU로 보낸다.
반대로 캐시 미스가 발생한다면 CPU는 L1 캐시가 메인 메모리로부터 w를 포함하고 있는 블록의 사본을 요청하는 동안 기다려야 한다. 요청한 블록이 메모리에서 도착하게 되면, L1 캐시는 이 블록을 자신의 캐시 라인 한 개에 저장하고 w를 추출해서 CPU로 보낸다. 캐시가 어떤 요청이 적중인지 미스인지 결정하고, 요청한 워드를 뽑아내기 위해 수행하는 작업은 다음 세 단계로 이뤄진다.
(1) 집합을 선택한다.
(2) 라인을 매칭한다.
(3) 워드를 추출한다.
직접 매핑 캐시에서 집합 선택
이 단계에서 캐시는 s개의 집합 인덱스 비트를 w 주소 중에서 뽑아낸다. 이 비트들은 집합 번호에 대응하는 비부호형 정수로 해석된다. 바꿔말하면, 만약 캐시를 집합들의 일차원 배열로 생각할 경우 집합 인덱스 비트들은 해당 배열의 인덱스를 구성한다고 생각할 수 있다.

위의 그림에서는 어떻게 집합이 선택되는지를 결정할 수 있다. 해당 그림에서는 000012의 값을 갖는 집합 인덱스 비트가 집합 1을 선택하는 정수 인덱스로 해석되는 것을 시각화하였다.
직접 매핑 캐시에서 라인 매칭
전 단계에서 집합 i를 선택했으므로, 다음 단계는 워드 w의 사본이 집합 i에 포함된 캐시 라인에 들어 있는지를 결정하는 것이다. 직접 매핑 캐시에서 집합 당 한 개의 라인만 있기 때문에, 이 작업은 쉽고 빠르게 할 수 있다. w의 사본은 유효비트가 설정되어 있고, 캐시 라인의 태그가 w의 주소에 잇는 태그와 일치하기만 한다면 사본이 해당 라인에 들어 있게 된다.

위의 그림에서는 직접 매핑 캐시에서 어떻게 라인 매칭이 작동하는지를 보여준다. 해당 예제에서는 직접 매핑 캐시를 사용하기에 각 집합 당 정확히 한 개의 라인만이 존재하게 된다.이 라인의 유효비트 valid가 1이고 이를 통해 태그와 블록의 비트들이 유효하다는 것을 알 수 있다. 캐시 라인의 태그 비트들이 주소의 태그비트들과 일치하기 때문에, 우리가 원하는 워드의 사본이 실제로 이 라인에 저장되어 있다는 것을 알 수 있다. 바꿔 말해 캐시가 적중되었다. 반면, 만일 유효 비트가 0이거나 태그가 일치하지 않는다면 캐시가 미스되었다는 응답을 받게 될 것이다.
캐시의 적중 여부는 Tag bits와 Valid bit을 보고 판단할 수 있다. (Block offset의 쓰임새는 그 이후이다)
직접 매핑에서 워드의 선택
일단 캐시 적중이 발생하면 w가 블록 내 어딘가에 있다는 것을 알게 된다. 마지막 단계는 원하는 워드가 블록 내 어디에서 시작하는지를 결정하는 것이다. 앞선 그림 2에서 나타난 것처럼, 블록 오프셋 비트는 원하는 워드의 첫 바이트 오프셋을 제공한다. 캐시를 라인들의 배열로 보는 방식을 다시 적용하면 블록을 바이트의 배열로 생각할 수 있으며, 바이트 오프셋은 배열 내 인덱스로 볼 수 있다. 예제에서 블록 오프셋 비트 1002는 사본이 블록 내 4번째 바이트에서 시작한다는 것을 나타낸다. (이때 워드의 길이는 4바이트라고 가정한다.)
미스 발생 시 라인의 교체
만일 캐시가 미스하면, 요청한 블록을 메모리 계층 구조 내 다음 레벨에서 가져와서 새 블록을 집합 인덱스 비트가 지시하는 집합의 캐시 라인 중 하나에 저장할 필요가 있다. 일반적으로 만일 이 집합이 유효한 캐시 라인들로 꽉 차 있다면, 기존 라인 중에 하나를 제거해야 한다. 각 집합이 정확히 한 개의 라인을 포함하고 있는 직접 매핑 캐시에서, 교체 정책replacement policy은 매우 단순하다.
: 현재 라인을 새롭게 선언한 라인으로 교체한다.
종합: 직접 매핑 캐시의 동작
캐시가 집합을 선택하고 라인을 식별하기 위해 사용하는 매커니즘은 상당히 간단하다. 그 이유는 하드웨어가 이들을 이들을 몇 나노초 내에 수행해야 하기 때문이다. 그러나 비트들을 이처럼 다루는 것은 사람에게 있어서는 다소 혼동을 가져올 수 있다. 실제 예제를 사용하면 이 작업을 명확하게 이해할 수 있다. 우리에게 다음과 같은 직접 매핑 캐시가 주어졌다고 하자.
(S, E, B, M) = (4, 1 , 2, 4)
다른 말로 설명하면 이 캐시는 4개의 집합, 집합 당 1개의 라인, 블록 당 2바이트, 4비트의 주소를 갖는다. 이와 별개로 각 워드는 1개의 바이트로 이뤄져 있다고 가정해보자. 물론 가정이 다소 비현실적이지만, 간단한 예제를 구성할 수 있다.

캐시에 대해서 학습할 때, 위의 그림 3에서 보인 것처럼, 전체 주소 공간을 모두 나열하고 비트들을 분리하는 것은 매우 바람직하다. 위의 그림에서 주요한 몇 가지 포인트들에 집중하여 살펴보자.
- Tag bits와 Index bits를 합치면 메모리 내의 각 블록을 유일하게 지정할 수 있게 된다. 예를 들어 블록 0는 주소 0과 1로 구성되며, 블록 1은 주소 2와 3, 블록 2는 주소 4와 5와 같은 방식이다.
- 총 8개의 메모리 블록이 있지만, 4개의 캐시 집합만 존재하므로, 여러 블록이 동일한 캐시 집합에 대응된다 (즉, 이들은 동일한 집합 인덱스를 갖는다). 예를 들어 블록 0과 4는 모두 집합 0에, 블록 1과 5는 모두 집합 1에 대응된다.
- 동일한 캐시 집합에 대응되는 블록들은 태그를 사용해서 유일하게 구별된다. 예를 들어 블록 0은 Tag bits 0, 블록 4는 Tag bits 1, 블록 1은 Tag bits 0을 가지며 블록 5는 Tag bits 1을 가진다.
CPU가 연속된 읽기 작업을 수행할 때 캐시의 동작을 시뮬레이션 해보자. 이 예제에서는 CPU가 1바이트 워드를 읽는 것을 가정한다.

초기에 캐시는 비어 있다. (즉, 각 유효비트는 0이다.)
표의 각 행은 캐시 라인을 나타낸다. 첫 번째 열은 라인이 속한 집합을 나타내지만, 이는 이해를 돕기 위해 추가적으로 붙어있을 뿐 실제 캐시에는 포함되지 않는 정보이다. 다음 4 개의 열은 실제 캐시 라인의 비트를 나타낸다.
이제 CPU가 일련의 읽기 작업을 수행할 때 어떤 일이 발생하는지를 살펴보자. (그림 3에서 계속 이어진다)
1. 주소 0에서 워드를 읽는다.
집합 0에 대한 유효비트가 0이기 때문에 이는 캐시 미스이다. 캐시는 메모리에서 블록 0을 선입해오고 (또는 그 하위 캐시로부터), 이 블록을 집합 0에 저장한다. 그리고 나서, 캐시는 m[0](메모리 0에 있는 내용)을 새로 선입한 캐시 라인의 block[0]에서 리턴해준다.

2. 주소 1에서 워드를 읽는다.
앞서 주소 0에서 워드를 읽으려던 시도로 인해 m[1]이 캐시 집합 0에 들어와 있는 상태이다. 현재 주소 1은 s index bits가 002이고 이를 통해 Set 0을 의미하는 것을 알게 된 상태이다. 이때, 유효 비트가 1이고 태그도 일치하기 때문에 사본이 존재한다는 것을 알게 된다.
결론적으로 b offset bits가 1이므로 해당하는 캐시 라인의 block[1]임을 알고 이를 리턴하게 되며 캐시 적중 상태이다. 캐시 상태의 변화는 없다.
3. 주소 13에서 워드를 읽는다.
주소 13의 s index bits는 10이다. 해당 캐시 집합에 접근하여 캐시 라인의 Valid 비트를 검사한다. 이때 유효하지 않으므로 이는 캐시 미스이다. 캐시는 해당 주소가 가져야 하는 블록 6번에 대한 데이터를 캐시 집합 2에 로드하고, 로드 이후 새 캐시 라인의 block[1]로부터 m[13]을 CPU에게 리턴하게 된다.

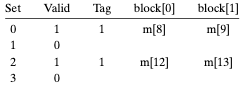
4. 주소 8에서 워드를 읽는다.
주소 8의 s index bits는 002이다. 앞서 주소 0을 읽으면서 해당 캐시 라인은 채워진 상태임을 기억하자.
해당 캐시 집합에 접근하는 경우, 먼저 유효 비트와 Tag 비트를 검사한다. 이때 유효 비트는 1이지만, 주소 8에게 기대되는 Tag 비트는 1인 것과 달리 캐시에는 0이 기록되어 있다. 이는 캐시 미스이다.
캐시는 블록 4를 메모리로부터 가져와 캐시 집합 0에 로드한다.
이때 주소 8의 b offset bits는 02이므로 새로운 캐시 라인의 block[0]을 리턴하여 CPU 혹은 상위 저장 장치 캐시에 전달한다.
5. 주소 0에서 워드를 읽는다.
이때 다시 주소 0에서 워드 데이터를 읽는다면 다시 캐시 미스가 발생한다. 그 이유는 우리가 방금 주소 8을 참조하는 동안에 블록 0을 교체했기 때문이다. 캐시에는 여전히 공간이 많이 남아있지만 동일한 집합으로 매핑하는 블록들로 번갈아서 참조를 하는 이런 종류의 미스는 충돌 미스conflict miss의 한 예가 된다.

직접 매핑 캐시에서의 충돌 미스
충돌 미스는 실제 프로그램에서 일반적인 현상이며 어려운 성능 문제를 야기한다. 직접 매핑 캐시에서 충돌 미스는 일반적으로 프로그램들이 크기가 2의 제곱인 배열에 접근할 때 발생한다. 예를 들어 두 벡터의 내적을 계산하는 함수를 생각해보자.
float dotplot(float x[8], float y[8]) {
float sum = 0.0;
for (int i = 0; i < 8; i++)
sum += x[i] * y[i];
return sum;
}이 함수는 x와 y에 대해서 좋은 공간 지역성을 지님과 동시에 많은 캐시 적중이 가능하다고 기대할 지도 모르지만, 실제로는 충돌 미스가 발생할 가능성이 존재하는 코드이다.
Float은 4 바이트이고, x가 주소 0부터 시작하여 연속적인 32 바이트에 로드되어 있으며, y는 주소 32부터 x에 이어서 곧바로 시작한다고 가정하자. 간단하게 하기 위해 한 개의 블록은 16바이트이고 (4 개의 float을 저장할 수 있는), 캐시는 두 개의 집합을 가지고, 전체 캐시 크기는 32 바이트라고 가정한다. 변수 sum이 실제로는 CPU 레지스터에 저장될 것이며, 따라서 메모리 참조는 이뤄지지 않는다고 가정한다. 이러한 가정들 하에 각 x[i]와 y[i]는 동일한 캐시 집합에 매핑될 것이다:
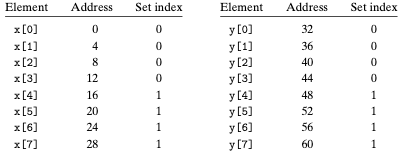
실행될 경우, 첫 번째 루프의 실행에서 x[0]을 참조하면 캐시 미스가 발생한다. 앞서 언급하였듯 한 블록의 크기는 16 바이트이므로, x[0]-x[3]을 포함하는 블록이 집합 0에 로드된다. 다음 참조는 y[0]인데 다시 미스가 되고, y[0]-y[3]을 포함하는 블록을 집합 0으로 복사하게 되는데, 이 과정에서 이전 참조에 의해 복사된 x의 값들이 지워진다. 다음 반복실행 동안에 x[1]에 대한 참조가 다시 미스가 되고, x[0]-x[3]에 해당하는 블록이 집합 0에 로드되고 y[0]-y[3] 블록은 지워진다. 따라서 우리는 충돌 미스를 갖게되며, 향후 발생하는 x와 y에 대한 모든 참조들은 블록 x와 y를 왔다갔다하며 thrash하는 충돌 미스를 발생시키게 된다. Thrashing은 캐시가 같은 집합의 캐시 블록들을 로드하고 축출하는 것을 반복하는 것을 의미한다.
다행히, thrashing은 일단 프로그래머가 무슨 일이 벌어지고 있는지를 인식한다면 수정이 그나마 용이하다. 한가지 해결책은 각 배열의 마지막에 B바이트의 패딩을 붙이는 것이다. 예를 들어 x를 float x[8]로 정의하는 대신 float x[12]로 정의한다. y가 메모리에서 x 바로 뒤에 시작한다고 가정하면 배여의 원소들이 집합에 다음과 같이 대응된다.
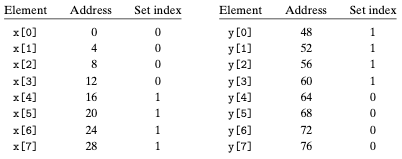
위의 그림에서는 x의 끝부분에 의도적으로 패딩을 넣어주어 x[i]와 y[i]가 서로 다른 집합에 매핑될 수 있도록 프로그래머가 조작을 가한 상황이다. 이를 통해 thrashing 충돌미스를 제거할 수 있다.
'CS' 카테고리의 다른 글
| Write 관련 캐시 이슈 (0) | 2022.11.29 |
|---|---|
| Set Associative Cache (집합결합성 캐시) (0) | 2022.11.28 |
| 기본 cache memory 구조 (0) | 2022.11.28 |
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
| Cache Memory 소개 (0) | 2022.11.28 |
각 메모리 주소가 M = 2m개의 고유한 주소를 구성하는 m비트를 갖는 컴퓨터 시스템에 대해 생각해보자. 그림에 나타낸 것처럼 이 시스템에 대한 캐시는 S = 2^s개의 Cache set들의 배열로 구성된다. 각 집합은 다시 E개의 Cache Line들로 이뤄지며, 각 라인은 B = 2^b 바이트의 데이터 블록, 해당 라인이 의미 있는 정보를 포함하고 있는지 여부를 나타내는 valid bit, 캐시 라인에 저장된 블록을 유일하게 구분할 수 있는 t = m - (b + s) 의 tag bit(현재 블록의 메모리 주소의 일부분으로 구성)로 구성된다.
일반적으로 캐시의 구성은 순서 쌍_(S, E, B, M)_으로 규정할 수 있다. 캐시의 크기 C는 모든 블록의 크기를 합하는 형태로 설명한다. 태그비트와 유효비트는 여기에 포함되지 않는다. 따라서 _C = S x E x B_로 나타낸다.
CPU가 메인 메모리 주소 A에서 하나의 워드를 읽으라는 load 인스트럭션에 의해 지시를 받을 때, CPU는 주소 A를 캐시로 보낸다.
캐시가 해당 워드의 사본을 가지고 있는지 어떻게 알 수 있을까?
캐시는 요청된 워드를 간단히 주소 비트만 조사해서 찾아낼 수 있도록 구성되어 있으며, 이런 방식은 매우 단순한 해시 함수를 사용하는 해시 테이블과 유사하다. 동작하는 방식은 다음과 같다.
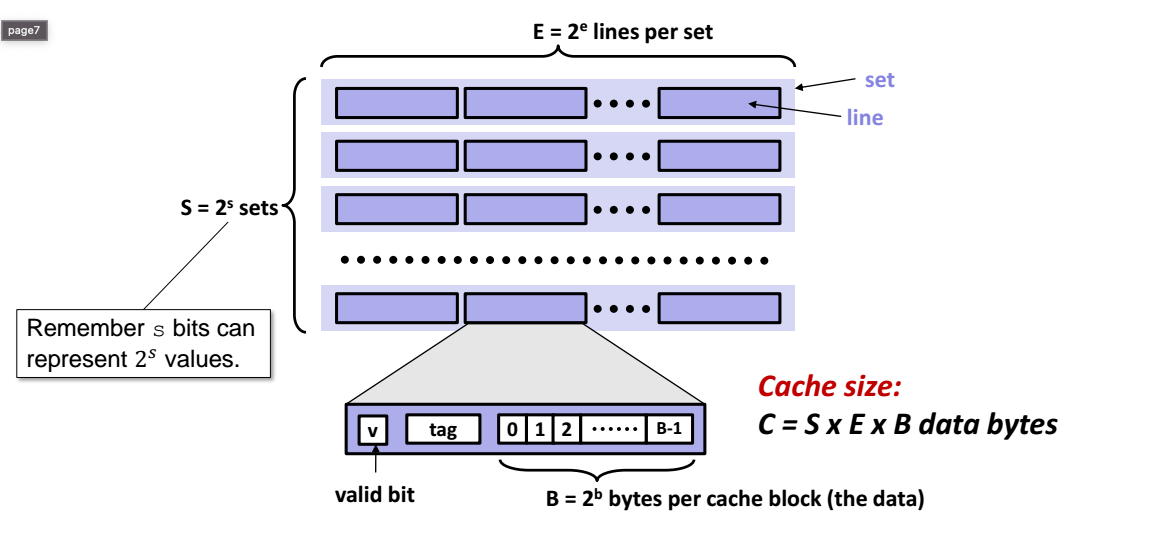
- 매개변수 S와 B는 m 주소 비트를 세 개의 그림과 같은 필드로 나눈다. A(Address)의 s 집합 인덱스 비트는 S 집합 배열의 인덱스를 구성한다. 집합 인덱스 필드를 통해 워드가 어떤 집합을 찾을지가 결정된다.
- 어떤 집합에 저장되어야 하는지를 알게 되었다면, A의 t 태그비트는 몇 번째 라인이 워드를 포함하고 있는지를 알려준다. 이때 해당하는 Cache Line의 유효비트가 1이고, 해당 줄의 태그비트가 주소 A의 태그 비트와 일치할 경우에만 해당 워드를 포함한다.
- 만약 집합 인덱스에 의해 식별된 집합 내의 태그로 라인을 찾았다면, b 블록 오프셋을 사용하면 B-바이트 데이터 내 워드의 오프셋을 알 수 있다.

'CS' 카테고리의 다른 글
| Set Associative Cache (집합결합성 캐시) (0) | 2022.11.28 |
|---|---|
| Directed Mapped Cache (직접매핑 캐시) (0) | 2022.11.28 |
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
| Cache Memory 소개 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
Cache Hit

어떤 프로그램이 레벨 k + 1로부터 특정 데이터 객체 d를 필요로 할 때, 먼저 현재 레벨 k에 저장된 블록들 중 하나에서 d를 찾는다. 만일 d가 레벨 k에서 우연히 캐시되어 있다면, 이 경우를 캐시 적중이라고 부른다. 프로그램은 d를 레벨 k에서 직접 읽으며 이는 k + 1에서 데이터를 읽는 것보다 빠르게 된다. (실제 캐시 적중이 되는 과정는 다음 글에서 자세히 다룬다. https://mydailylogs.tistory.com/31)
Cache Miss
반면, 만일 데이터 객체 d가 레벨 k에서 캐시되지 않았다면 캐시 미스가 발생한 것이다. 미스가 존재할 때, 레벨 k에서의 캐시는 레벨 k + 1에 있는 캐시로부터 d를 포함하는 블록을 가져오며, 만일 레벨 k 캐시가 이미 꽉 찬 상태라면 기존 블록에 덮어 쓰기도 한다.
이와 같이 기존 블록을 덮어 쓰는 과정은 블록을 교체하거나 축출하는 것으로 알려져 있느며 이때 축출되는 블록은 희생 블록(Victim Block)이라고 부른다. 어떤 블록을 교체할 지에 대한 결정은 캐시의 교환 정책에 의해 정해진다. 예를 들어, 랜덤 교체 정책을 사용하는 캐시는 랜덤으로 희생 블록을 선택한다. 최근에 가장 덜 사용한 (LRU) 교체 정책을 갖는 캐시는 가장 과거에 접근한 블록을 선택할 것이다.
Cache Miss의 종류
때때로 여러 종류의 캐시 미스들을 구별하는 것이 유용한 경우가 있다. 만일 레벨 k에서 캐시가 비어있다면 모든 데이터 객체를 접근하려는 시도는 미스를 유발하게 된다. 비어 있는 캐시는 종종 cold cache라고 불리우며, 이런 종류의 미스들은 강제적인 미스 또는 콜드 미스(cold miss)라고 부른다. 캐시가 반복된 메모리 접근으로 준비가 된 이후의 콜드미스는 종종 안정화 상태에서는 발생하지 않는 유동적인 이벤트이기 때문에 중요하다.
미스가 있을 때마다 레벨 k에서의 캐시는 레벨 k + 1로부터 가져온 블록을 어디에 저장할지를 결정하는 배치 정책을 구현해야만 한다. 가장 유연한 배치 정책은 레벨 k + 1로부터 가져온 모든 블록을 레벨 k의 어떤 블록에도 저장될 수 있도록 하는 것이다. 하드웨어로 구현되었고 속도가 가장 중요한 메모리 계층 구조의 높은 곳에 위치한 캐시에 대해서 이러한 정책은 대개 구현하는데 비용이 너무 많이 드는데, 이는 랜덤으로 배치한 블록들의 위치를 찾는 것이 상당한 연산을 수행하기 때문이다.
그래서 하드웨어 캐시는 일반적으로 레벨 k + 1에서 특정 블록을 레벨 k에 있는 블록의 작은 부분 집합으로 제한하는 보다 제한적인 배치 정책을 구현한다. 예를 들어, 레벨 k + 1의 블록 i가 레벨 k에 있는 블록을 (i mod 4)로 배치할지 여부를 결정해야 할 수도 있다. 우리 그림에서 볼 경우, 레벨 k + 1의 블록 0, 4, 8, 12는 블록 0에 매핑되게 될 것이고, 블록 1, 5, 9, 13은 블록 1로 매핑될 것이다.
이러한 종류의 제한적인 배치 전략은 충돌 미스(conflict miss)라고 알려진 유형으로 유도된다. 이는 계속해서 동일한 캐시 블록으로 하위 레벨의 블록들이 매핑되게 하면서, 캐시가 미스되기 때문이다. 예를 들어 만일 프로그램이 0을 요청하고 다음엔 블록 8, 다음에 또 0 그리고 다시 12를 요청한다면 이 두 개의 블록에 대한 참조는 k에 있는 캐시에서 미스하게 되고, 비록 이 캐시가 전체 네 개의 블록을 저장할 수 있다고 하더라도 계속해서 미스가 발생하게 된다.
프로그램들은 종종 일련의 단계로 실행되며 각 단계는 캐시 블록의 합리적인 상수 집합을 접근한다. 예를 들어 연속된 루프는 동일한 배열의 원소들을 반복적으로 접근할 수 있다. 이러한 블록들의 집합은 이 단계의 동작집합이라고 부른다. 동작 집합의 크기가 캐시 크기보다 더 클 때, 캐시는 용량 미스(capacity miss)라고 알려진 미스를 경험하게 된다. 다른 말로 캐시가 너무 작아서 이러한 동작 집합을 처리할 수 없는 경우이다. 캐시의 용량이 부족하여 발생하는 미스이다. 즉, 프로그램 수행 시 접근하는 데이터의 양이 캐시의 사이즈를 넘어갈 경우 발생한다. 예를들어 32k direct mapped cache를 달고 있는 컴퓨터에서 128k array data를 접근하는 경우 캐시는 array data를 모두 저장할 수 없으므로 용량 부족에 의한 캐시 미스가 발생한다.
'CS' 카테고리의 다른 글
| Directed Mapped Cache (직접매핑 캐시) (0) | 2022.11.28 |
|---|---|
| 기본 cache memory 구조 (0) | 2022.11.28 |
| Cache Memory 소개 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
| [리눅스 프로그래밍] Kernel 개요 (1) | 2022.09.23 |
Memory Hierarchy

현대의 모든 시스템에서 차용하는 메모리 계층 구조.
일반적으로 저장장치 디바이스들은 위에서 아래 수준으로 이동함에 따라 더 느려지고, 더 값싸지고, 더 커진다.
(1) 최상위(L0)에는 CPU가 한 개의 클럭 사이클 내에 접근할 수 있는 적은 수의 빠른 CPU 레지스터들이 위치한다.
(2) 그 다음은 몇 CPU 클럭 사이클 내에 접근할 수 있는 한 개 이상의 작은 것에서부터 적당한 크기의 SRAM 기반 캐시 메모리가 위치한다.
(3) 그 다음으로 수백, 수천 클럭 사이클 동안에 접근될 수 있는 DRAM 기반 메인 메모리가 따라온다.
(4) 다음은 느리지만 엄청난 크기의 지역 디스크들이 있다.
(5) 마지막으로 일부 시스템들은 네트워크로 접근할 수 있는 원격 서버 상의 추가적인 디스크를 포함하기도 한다.
메모리 계층 구조에서의 캐시
일반적으로 캐시는 보다 크고 느린 디바이스에 저장된 데이터 객체를 위한 준비 영역으로 사용하는 작고 빠른 저장 디바이스이다. 캐시를 사용하는 과정은 캐싱으로 알려져 있다.
메모리 계층 구조의 중심 개념은 각 k에 대해, 레벨 k에 있는 보다 빠르고 더 작은 저장 장치가 레벨 k + 1에 있는 더 크고 더 느린 디바이스를 위한 캐시 서비스를 제공한다는 것이다. 예를 들어 로컬 디스크는 네트워크 너머 원격 디스크로부터 가져온 파일들에 대한 캐시로 서비스하며, 메인 메모리는 로컬 디스크 상의 데이터에 대한 캐시로 서비스하는 식으로 가장 작은 캐시인 CPU 레지스터 집합에 이를 때까지 지속된다.

위의 그림은 메모리 계층 구조에서 캐싱의 일반적인 개념을 보여준다. 레벨 k + 1에서 저장장치는 블록이라고 하는 연속된 데이터 객체 볼륨으로 나뉜다. 각 블록은 유일한 주소 도는 이름을 가지며, 이들은 자신을 다른 블록과 구분해준다.
이때 블록은 가변 크기를 가지게 되는데, 예를 들어 그림 2에서의 레벨 k + 1 저장 장치는 16개의 고정크기 블록으로 나뉘며 0에서 15까지 숫자가 붙어 있다.
마찬가지로, 레벨 k에서의 저장장치는 레벨 k + 1에 있는 블록들과 같은 크기인 더 작은 집합의 블록들로 나뉜다. 레벨 k에 있는 캐시는 레벨 k + 1에서 온 쁠록들의 부분집합인 사본을 포함한다. 현재 그림에서도 4, 9, 14, 3의 사본을 가지고 있다.
데이터는 항상 레벨 k와 k + 1 사이에서 블록 크기의 전송 유닛으로 복사된다. 블록 크기가 계층 구조의 인접한 모든 쌍들 사이에서 고정되어 있는 반면, 다른 레벨의 쌍들은 서로 다른 블록 크기를 가질 수 있다. 예를 들어, L1과 L0 사이의 전송은 일반적으로 한 개의 워드 블록을 사용한다. L2와 L1 (L3와 L2, L4와 L3) 전송은 일반적으로 8에서 16 워드의 블록을 사용한다. L5와 L4 간의 전송은 수백 또는 수천 바이트를 갖는 블록을 사용한다. 일반적으로 계층 구조에서 더 낮은 곳에 위치한 디바이스들은 더 긴 접근 시간을 가지게 되며, 접근 시간을 줄이고자 하는 일환으로 더 큰 블록 크기를 사용한다.
'CS' 카테고리의 다른 글
| 기본 cache memory 구조 (0) | 2022.11.28 |
|---|---|
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
| [리눅스 프로그래밍] Kernel 개요 (1) | 2022.09.23 |
| [OS] Introduction (1) | 2022.09.23 |
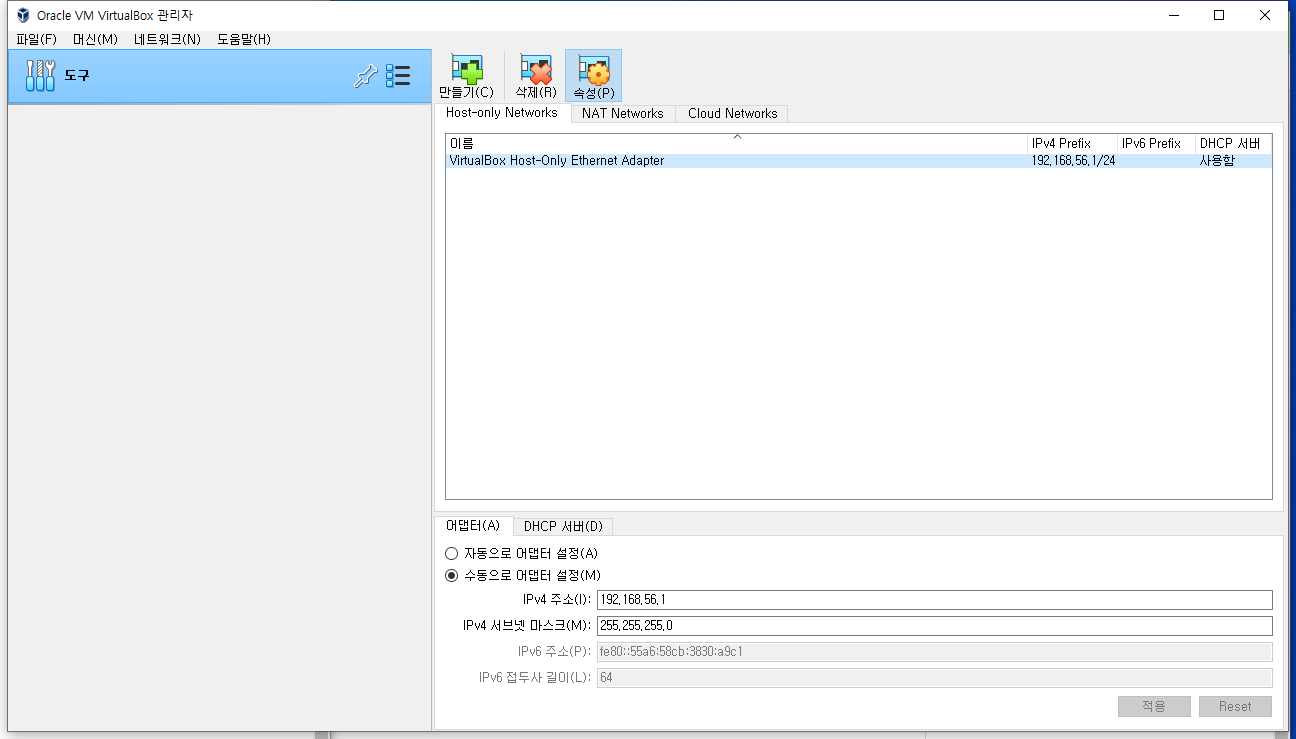
[VirtualBox, Window] 호스트 전용 네트워크 설정 오류 "Querying NetCfgInstanceId failed (0x00000002)."
문제 상황
Virtual Box를 통해 호스트 전용 네트워크를 설정하고자 함. 만들기 버튼을 눌렀더니, creating host only network interface not working 라는 메세지가 꽤나 오랜시간 뜨더니 생성이 실패함.
버전을 변경해가며 재설치를 진행했고, 혹시나 제거가 완벽하게 되지 않아서 생긴 문제인가 싶어서 로그 파일까지 다 지웠음에도 문제가 해결되지 않았음.
로그: creating host only network interface not working
문제 해결
Summary: 이더넷 네트워크 설정에서 VirtualBox NDIS6 Bridged Networking Driver를 제거.
Step 1: 현재 실행 중인 Virtual Box를 종료
...
Step 2: 기존에 사용하던 Virtual Box를 제거
Step 3: 설정 > 네트워크 및 인터넷 > 어뎁터 옵션 변경 으로 이동
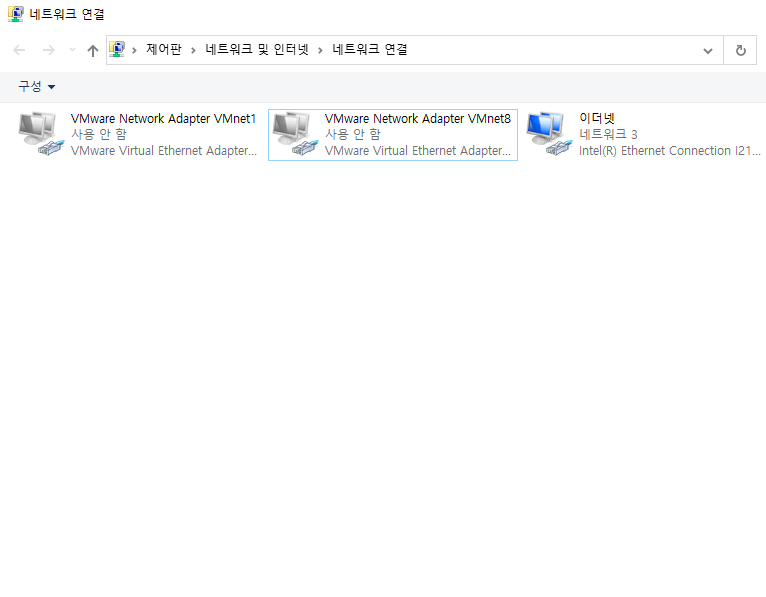
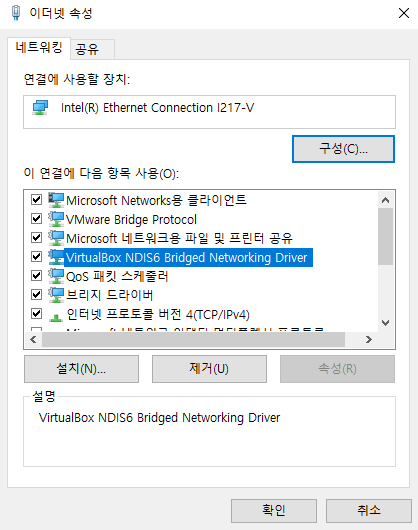
Step 4: 마우스 우클릭 후 속성으로 진입, VirtualBox NDIS6 Bridged Networking Driver를 제거
(Virtual Box가 제거되지 않은 경우 해당 항목의 삭제가 정상적으로 되지 않음)
Step 5: Virtual Box 재설치
원하는 버전으로 재설치
Step 6: 별도의 작업 없이도 VirtualBox Host-Only Ethernet Adaptor가 정상적으로 추가되었다면 성공
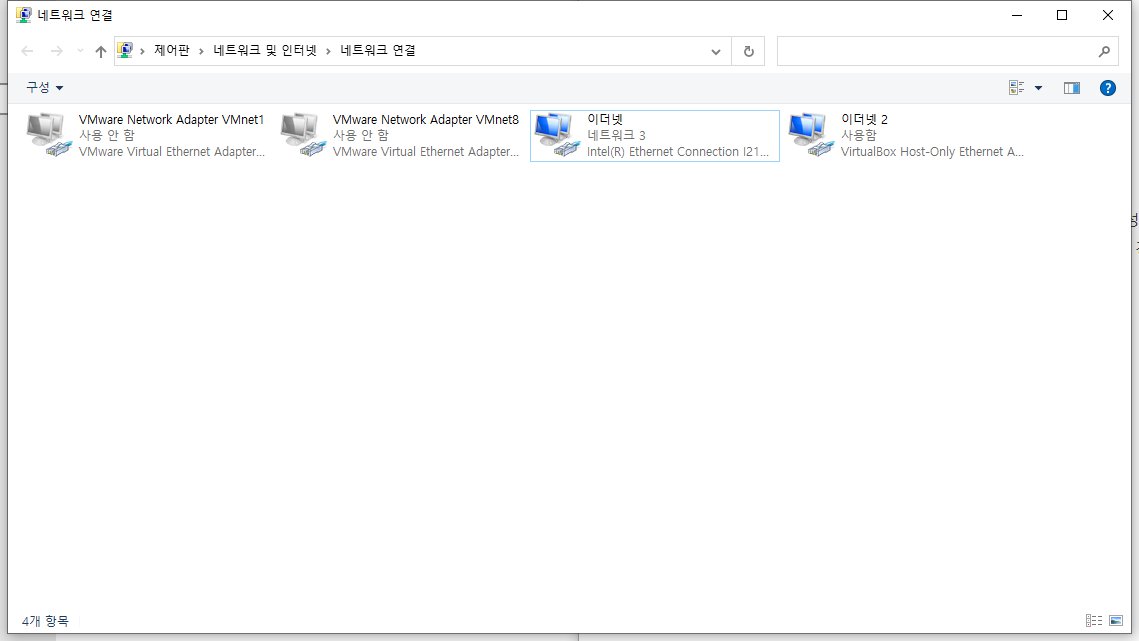
Virtual Box 내부에서도 확인 가능
'etc > errors' 카테고리의 다른 글
| git push시 계속해서 인증을 요구하는 경우 (0) | 2023.04.09 |
|---|---|
| 스크립트를 통한 ssh 접속 (0) | 2023.04.07 |
| SSH를 통한 Root 로그인 불가 시 해결 방법 (0) | 2023.04.07 |
| Git 충돌날 때 사용가능한 간단한 대처방법 (0) | 2023.03.26 |
스파크 소개
스파크는 통합 컴퓨팅 엔진으로서 클러스터 환경에서 데이터를 병렬적으로 처리하는 라이브러리 집합입니다. 스파크는 파이썬, 자바, 스칼라, R을 지원하며 단일 노트북 환경에서 수천 대의 서버로 구성된 클러스터에 이르기까지 다양한 환경에서 실행할 수 있습니다. 이러한 특성을 활용하여 스칼라를 통해 빅데이터를 용이하게 처리하는 동시에 엄청난 규모의 클러스터로 확장시켜 나갈 수 있습니다.
스파크는 원래 UCLA, Berkeley에서 개발되었으며 이후 Apache Software Foundation에 기부되었습니다. 또한 2014년 2월에 최상위 Apache 프로젝트가 되었고, 지금까지 수천 명의 엔지니어가 Spark에 기여하여 현재는 빅데이터 플랫폼을 구성하는 주요한 오픈소스로 자리잡았습니다.
Apache Spark는 Scala, Python, R 및 Java를 지원하는 프레임워크라고 할 수 있습니다. 이때 스파크는 언어에 따라 다양한 구현이 있습니다.
- Spark - Scala 및 Java용 기본 인터페이스
- PySpark - Spark용 Python 인터페이스
- SparklyR - Spark용 R 인터페이스
스파크 특징
- 인-메모리 연산
- 병렬화를 통한 분산 처리
- 다양한 클러스터 관리자 (Spark, Yarn, Mesos) 지원
- 내결함성
- 불변성 (RDD)
- Lazy Evalution을 통해 계산 효율성 증대
- Cache와 Persistence를 통한 효율적인 데이터 가공
- ANSI SQL을 지원
스파크 장점
- Spark는 범용 오픈소스로서 인메모리 연산, 내결함성 등의 특징과 함께 분산 프로세싱 엔진을 통해 데이터를 효율적으로 처리한다.
- Spark 내부에서 실행되는 애플리케이션은 전통적인 방식의 애플리케이션보다 약 100배 빠르다.
- Data Ingestion pipeline 구성 시에 Spark를 활용한다면 많은 장점을 얻을 수 있다.
- HDFS, AWS S3, Databricks DBFS, Azure Blob Storage 등과 같은 다양한 소스로부터 들어온 데이터를 처리할 수 있다.
- Kafka 등을 활용한 실시간 데이터 처리 프로세스에서도 활용이 가능하다.
- Spark Streaming을 통해서 파일 시스템으로부터 파일 stream을 구성할 수도 있고, 소켓으로부터도 stream을 구성할 수 있다.
- Spark는 자체적으로 ML과 그래프 관련 라이브러리들을 내장한다.
💡 Spark의 내결함성(Fault Tolerance)을 가능하게 하는 강력한 기능으로 RDD가 있습니다. 이는 이후 RDD를 다루며 다시 소개하도록 하겠습니다. https://hevodata.com/learn/spark-fault-tolerance/#t2
💡 내결함성: 구성 요소 중 일부가 실패하거나 그 안에 하나 이상의 결함이 있는 경우에도 시스템이 계속 제대로 작동하는 기능
스파크의 철학
스파크는 빅데이터 애플리케이션 개발에 필요한 통합 플랫폼을 제공하자라는 핵심 목표를 가지고 있습니다. 여기서 말하는 통합이란 간단한 데이터처리에서 SQL 처리, 머신러닝 그리고 스트리밍 데이터 처리에 이르기까지 다양한 데이터 분석 작업을 Spark라는 단일 엔진과 이를 통해 제공되는 API로 수행할 수 있도록 하는 것을 의미합니다.
때문에 스파크를 활용하게 되면 일관성있는 조합형 API를 제공하게 되므로 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있습니다. 조합형 API 만으로 문제를 해결할 수 없다면, 직접 스파크 기반의 라이브러리를 통해 문제를 해결할 수도 있습니다.
스파크의 API는 서로 다른 라이브러리의 기능을 조합하여 기존 라이브러리를 사용하는 것보다 더 나은 성능을 제공하게 됩니다. 예를 들어 SQL 쿼리로 데이터를 읽고 ML 라이브러리로 머신러닝 모델을 평가해야 하는 경우, 스파크 엔진은 이 두 단계를 하나로 병합하여 데이터를 한 번 조회하는 것만으로도 작업을 완료할 수 있습니다.
스파크가 있기 전에는 개발자가 직접 다양한 API와 시스템을 조합하여 애플리케이션을 작성해야 했습니다. 그러나 스파크가 발표된 이후 스파크의 통합 엔진을 통해 개발자의 번거로움이 상당부분 해소되었고, 시간이 지남에 따라 더 많은 처리 유형을 지원하기 위해 API가 지금도 늘어나고 있습니다.
컴퓨팅 엔진
스파크는 통합이라는 철학 아래에 기능의 범위를 컴퓨팅 엔진으로 제한해왔습니다. 때문에 스파크는 저장소 시스템의 데이터를 연산하는 역할을 수행할 뿐 영구 저장소의 역할을 수행하지 않습니다. 앞서 언급하였듯 다양한 저장소(Azure blob storage / S3 / Hadoop 등)를 지원합니다. 이는 스파크의 장점 중 하나로 설명할 수 있습니다. 스파크는 특정 저장소에 종속되지 않기 때문에 어떠한 저장소를 사용하더라도 문제가 되지 않습니다. 실제 비즈니스 레벨의 데이터 파이프라인의 경우 다양한 소스로부터 데이터를 처리할 수 있어야 합니다. 이 경우 스파크를 활용한다면 손쉽게 문제를 해결할 수 있습니다.
실제 사용자 API 또한 이를 고려하여 서로 다른 저장소 시스템을 구분하지 않고 유사하다고 인식하게 되며, 따라서 애플리케이션은 데이터가 저장된 위치를 고려하지 않아도 됩니다.
저장소로부터 데이터를 받은 이후 스파크에서는 연산을 빠르게 수행하기 위해 In-memory 연산을 수행합니다. 때문에 스파크 내에서는 데이터가 오래 머물지 않으며 데이터의 저장 위치에 상관 없이 온전히 처리에 집중할 수 있게 되었습니다.
이는 기존의 아파치 하둡과 같은 빅데이터 플랫폼과의 차별화 포인트가 됩니다. 하둡은 범용 서버 클러스터 환경에서 저비용 저장 장치를 사용하도록 설계된 HDFS와 mapReduce를 가지고 있으며 두 시스템은 밀접한 관계를 가지고 있습니다. 이때 하둡과 같은 구조에서는 둘 중 하나의 시스템 만을 단독으로 사용하기가 어렵습니다. 특히 하둡만을 사용한다면 다른 저장소에 위치한 데이터에 접근하는 애플리케이션을 개발하는 것이 어려워집니다. 스파크는 HDFS와도 잘 호환되며, 하둡을 사용할 수 없는 다양한 환경에서도 사용이 가능합니다.
스파크의 등장 배경
역사적으로 컴퓨터는 프로세서의 성능 향상에 따라 매년 빨라졌습니다. 그 결과 코드 수정 없이도 애플리케이션의 성능도 자연스럽게 올라가게 되었습니다. 대규모 애플리케이션은 이런 경향성과 함께 개발되어 왔으며 과거 대부분의 시스템은 단일 프로세서에서만 실행되도록 설계되었습니다.
그러나 하드웨어의 성능 향상은 2005년 경에 멈추게 되었으며(물리적인 방열 한계로 인해), 단일 프로세서의 성능을 증가시키기 보다 모든 코어가 같은 속도로 동작하는 병렬 CPU 코어를 더 많이 추가하는 방향으로 선회했습니다. 이는 곧 애플리케이션의 성능 향상을 위해서는 앞으로 병렬 처리가 필요하며 스파크와 같은 새로운 프로그래밍 모델의 세상이 도래할 것임을 암시하게 됩니다.
프로세서의 성능이 개선되진 않았으나 데이터 저장과 수집 기술은 계속 발전해왔기에 눈에 띄게 느려지지 않았으며 1TB 가량의 데이터를 저장하는데 대략 14개월마다 비용이 절반으로 줄고 있었으며, 때문에 조직 규모와 관계없이 대규모의 데이터를 저렴하게 저장할 수 있었습니다.
결과적으로 데이터의 수집 비용은 극히 저렴해졌으나 데이터는 클러스터를 거쳐야만 처리할 수 있을 정도로 거대해졌으며, 과거 프로세서의 성능 향상으로 인해 애플리케이션이 코드 한줄 변화 없이도 성능이 향상되었던 것과 달리 이제는 소프트웨어 측면에서 다양한 개선이 요구되게
스파크 구조
Apache Spark는 마스터 노드를 Driver라고 하고 슬레이브 노드를 Worker라고 합니다. 스파크 클러스터는 앞선 두 요소로 이뤄진 마스터-슬레이브 아키텍쳐에서 작동합니다. Spark 애플리케이션을 실행할 때 Spark Driver는 애플리케이션에 대한 진입점인 컨텍스트를 생성하고 실제 모든 작업은 작업자 노드에서 실행됩니다.
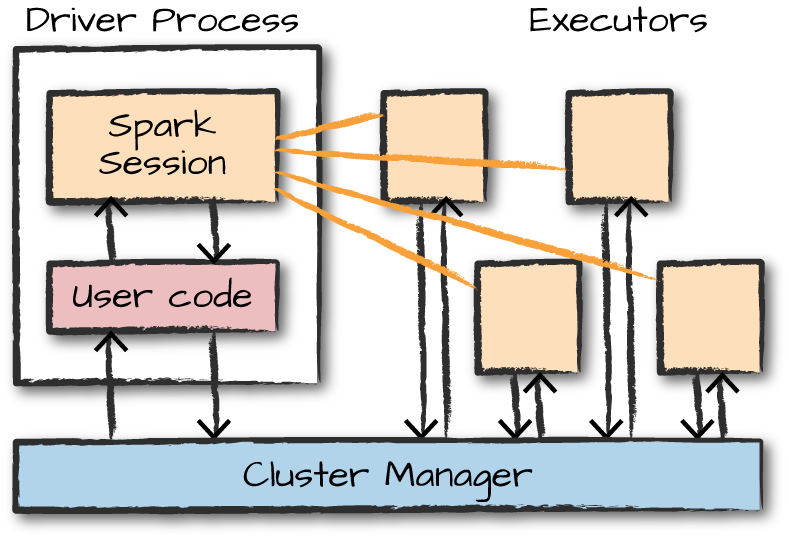
이때 Driver 노드에서 실행된 Driver 프로세스는 Worker 노드에 위치한 Executor 프로세스에 작업을 할당 및 지시하게 됩니다. Executor 프로세스 내부에는 처리해야하는 여러 작업이 있으며, 작업을 좀 더 빠르게 수행하기 위한 캐시를 가지게 됩니다.

클러스터 관리자에서는 실제 사용 가능한 자원을 파악하며, 하드웨어 자원을 관리하게 됩니다.
이어지는 이미지를 통해 스파크에서 제공하는 전체 컴포넌트와 라이브러리 구조를 확인할 수 있습니다.

클러스터 관리자 유형
앞서 특징에서 언급하였듯 스파크는 다양한 클러스터 관리자를 지원합니다. 아래는 그 목록입니다.
- Standalone - Spark에 포함된 간단한 클러스터 관리자를 통해 클러스터를 간단하게 설정할 수 있습니다.
- Apache Mesos - Hadoop MapReduce 및 Spark 애플리케이션도 실행할 수 있는 클러스터 관리자입니다.
- Hadoop YARN - Hadoop 2의 리소스 관리자입니다. 빅데이터 플랫폼을 구성할 경우 HDFS를 사용한다는 전제 하에 가장 자주 사용되는 클러스터 관리자입니다.
- Kubernetes - 컨테이너화된 애플리케이션의 배포, 확장 및 관리를 자동화하기 위한 오픈 소스 시스템입니다.
- Local - 주로 실습 환경에서 사용되는 로컬 클러스터입니다. 옵션을 통해 코어 수를 조절할 수 있습니다.
Spark shell
스파크를 설치하게 되면 spark-shell을 통해 대화형으로 작업을 수행할 수 있습니다. 쉘을 시작하려면 SPARK_HOME/bin 디렉토리로 이동하여 spark-shell2를 입력합니다. 해당 명령은 Spark를 로드하고 사용 중인 Spark 버전을 표시합니다.

기본적으로 spark-shell은 사용할 spark(SparkSession) 및 sc(SparkContext)와 같은 기본 명령어를 제공합니다.
이와 동시에 spark-shell은 Spark 컨텍스트 웹 UI를 생성하며 http://localhost:4041에서 접근 가능합니다.
Spark submit
spark-submit 명령은 옵션 및 구성 사항을 지정하여 클러스터에 Spark 또는 PySpark 애플리케이션 프로그램(또는 작업)을 실행하거나 제출하는 유틸리티입니다. 이때 제출하는 애플리케이션은 Scala, Java, Python(PySpark)와 같은 코드로 작성할 수 있습니다. 해당 유틸리티를 사용하여 다음을 수행할 수 있습니다.
- Yarn, Kubernetes, Mesos 및 Stand-alone과 같은 다양한 클러스터 관리자에 Spark 애플리케이션을 submit
- 클라이언트 또는 클라이언트 배포 모드에서 Spark 애플리케이션 submit
아래는 submit을 구성하는 예시입니다.
./bin/spark-submit \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key<=<value> \
--driver-memory <value>g \
--executor-memory <value>g \
--executor-cores <number of cores> \
--jars <comma separated dependencies>
--class <main-class> \
<application-jar> \
[application-arguments]Spark Web UI
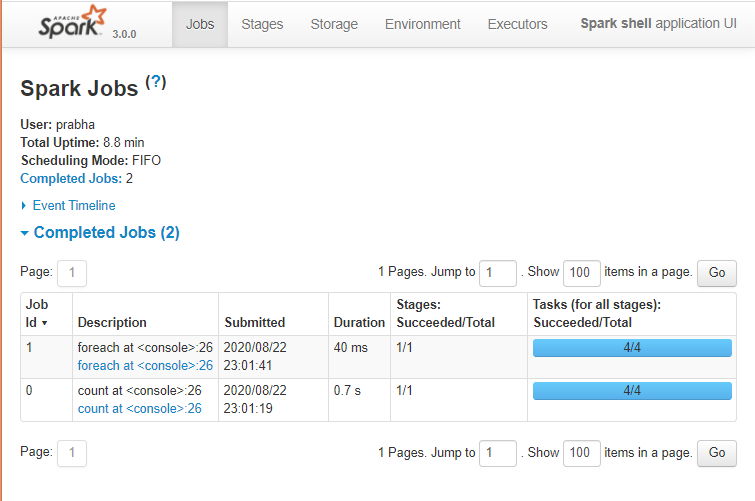
Apache Spark는 Spark 애플리케이션의 상태, Spark 클러스터의 리소스 소비 및 Spark 구성을 모니터링하기 위한 웹 UI 모음(작업, 스테이지, 테스크, 스토리지, 환경, 실행자 및 SQL)을 제공합니다. Spark Web UI를 통해 작업이 실행되는 방식을 확인할 수 있습니다. 기본적으로 http://localhost:4041에서 접근 가능합니다.
Spark History Server
Spark History Server는 spark-submit 또는 spark-shell 등을 거쳐 완료된 모든 응용 프로그램의 로그를 유지합니다. 이를 시작하기 위해서는 spark-defaults.conf에서 먼저 다음의 설정을 완료해야 합니다.
spark.eventLog.enabled true
spark.history.fs.logDirectory file:///c:/logs/path이제 다음 명령어를 실행하여 Linux 또는 Mac에서 Spark History 서버를 시작합니다. (Linux / MAC)
$SPARK_HOME/sbin/start-history-server.shWindows의 경우에는 다음 명령을 시작하여 히스토리 서버를 시작할 수 있습니다.
$SPARK_HOME/bin/spark-class.cmd org.apache.spark.deploy.history.HistoryServer기본적으로 히스토리 서버는 18080 포트에서 수신 대기 상태에 놓이며, http://localhost:18080/를 사용하여 브라우저에서 엑세스할 수 있습니다.
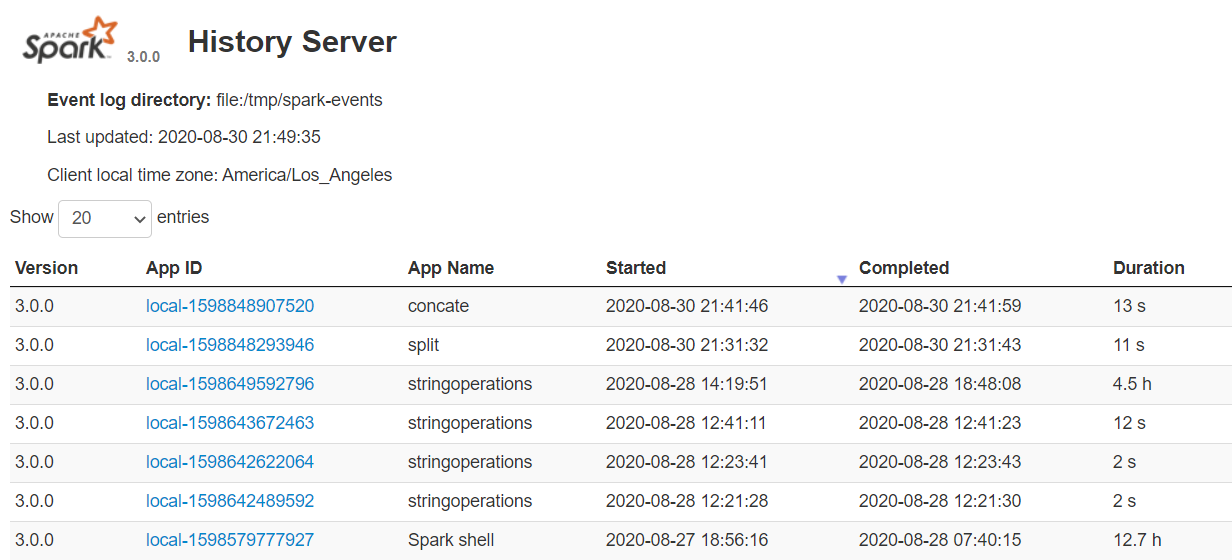
이때 각각의 App ID를 클릭하면 Spark Web UI에서 해당 애플리케이션의 세부 정보를 얻을 수 있습니다.
History Server는 이전 애플리케이션의 실행과 현재 진행 중인 실행을 교차 확인할 수 있어 Spark 성능 조정을 수행할 때 매우 유용합니다.
Spark Library(Module)
Spark는 엔진에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 서드파티 패키지 형태로 제공하는 다양한 외부 라이브러리를 지원합니다. 이때 Spark 표준 라이브러리는 사실 여러 오픈소스 프로젝트의 집합체라고 생각할 수 있습니다.
스파크가 각광을 받게 된 배경에는 스파크가 제공하는 라이브러리도 많은 영향을 끼쳤습니다. 스파크는 분산 처리 프레임 위에 Spark Streaming, SparkQL, MLlib, GraphX와 같은 라이브러리을 제공하여 실시간 수집부터 데이터 추출/전처리, 머신러닝 및 그래프 분석까지 하나의 흐름에 모든 것이 가능할 수 있도록 개발되었습니다.
여러 라이브러리 중 가장 유명한 몇 가지를 소개하자면 다음과 같습니다.
- Spark SQL: Spark Wrapper 함수에 SQL 쿼리를 넣어 추출/전처리/분석이 쉽게 가능하도록 지원
- MLlib: 머신러닝 알고리즘 제공
- Spark Streaming: 실시간 데이터 처리
- GraphX: 그래프 분석 라이브러리

다음 링크를 통해 다양한 외부 라이브러리 목록을 확인할 수 있습니다.
Spark Core
Spark Core는 분산 작업 디스패치, 스케쥴링, 기본 I/O 등의 추상화를 제공하는 Spark의 기본 라이브러리입니다.
SparkSession
버전 2.0에 도입된 SparkSession은 Spark RDD, DataFrame 및 Dataset을 프로그래밍 방식으로 사용하기 위한 Spark의 진입점이라고 생각할 수 있습니다. 즉, SparkSession 인스턴스를 생성하는 것은 RDD, DataFrame 및 Dataset을 사용하여 프로그램에 작성하게 되는 첫 번째 명령문이며, SparkSession은 아래 코드에서 볼 수 있 듯 SparkSession.builder() 패턴을 사용하여 생성됩니다.
import org.apache.spark.sql.SparkSession
val spark:SparkSession = SparkSession.builder()
.master("local[1]")
.appName("SparkByExamples.com")
.getOrCreate()SparkContext
SparkContext는 Spark 1.x (Java 용 JavaSparkContext)부터 사용할 수 있으며, 2.0에서 SparkSession을 도입하기 이전에 Spark 및 PySpark에 대한 진입점으로 사용되었습니다. SparkContext의 생성은 RDD로 프로그램을 만들고 Spark Cluster에 프로그램을 연결하는 첫 번째 단계였습니다. 앞서 spark-shell에서 sc 명령어를 통해 확인할 수 있었던 객체가 바로 SparkContext입니다.
Spark 2.x 버전 부터는 SparkSession을 통해 진입점을 생성하기 시작하면서 SparkSession을 생성하면 SparkContext 객체가 기본적으로 생성되었습니다.
💡 JVM 1개 당 SparkContext를 1개만 생성할 수 있는 것과 달리, SparkSession은 여러개의 객체를 생성할 수 있다는 점이 주요한 차이점입니다.
Spark Session과 스파크 언어 API와의 관계
스파크의 언어 API를 활용하면 다양한 프로그래밍 언어로 스파크 코드를 실행할 수 있습니다. 스파크는 모든 언어에 맞는 몇몇 핵심 개념을 제공하며 이러한 핵심 개념은 클러스터 머신에서 실행되는 스파크 코드로 변환됩니다. 구조적 API만으로 작성된 코드는 언어에 상관없이 유사한 성능을 발휘합니다. 다음 목록은 언어별 요약 정보입니다.
- 스칼라: 스파크는 스칼라로 개발되어 있으며 스칼라가 스파크의 기본 언어입니다.
- 자바: 스파크가 스칼라로 개발되어 있지만, 스파크 창시자들은 자바를 이용해서 스파크 코드를 작성할 수 있도록 심혈을 기울였습니다.
- 파이썬: 파이썬은 스칼라가 지원하는 거의 모든 구조를 지원합니다.
- SQL: 스파크는 ANSI SQL:2003 표준 중 일부를 제공합니다. 분석가나 비프로그래머도 SQL을 활용하여 스파크의 강력한 빅데이터 처리 기능을 쉽게 확인할 수 있습니다.
- R: 스파크에는 일반적으로 사용하는 두 개의 R 라이브러리가 있습니다. 하나는 스파크 코어에 포함된 SparkR이고 다른 하나는 R 커뮤니티에서 파생된 sparklyr입니다.

각 언어 API는 앞서 설명한 핵심 개념을 유지하고 있습니다. 사용자는 스파크 코드를 실행하기 위해 SparkSession 객체를 진입점으로 사용할 수 있습니다. 이때 주목할만한 점은 우리가 Python이나 R로 스파크를 사용할 때 JVM 코드를 작성하지 않는다는 점입니다. 스파크는 사용자를 대신하여 파이썬이나 R로 작성한 코드를 익스큐터의 JVM에서 실행할 수 있는 코드로 변환합니다.
이는 스칼라가 저수준의 비구조적(unstructured, RDD) API와 고수준의 구조적(structured, Data Frame) API를 가지고 있기 때문입니다. 이는 이후에 다시 중점적으로 다뤄보도록 하겠습니다.
'Data Engineering' 카테고리의 다른 글
| Zookeeper의 znode (0) | 2023.05.18 |
|---|---|
| Coursera 데이터 엔지니어링 강의 목록 (0) | 2022.12.08 |
| 로그 데이터 수집 (0) | 2022.11.18 |
| [에러 노트] AWS Data Crawler로 생성된 DB의 스키마가 업데이트 되지 않는 경우 (0) | 2022.10.26 |
| [AWS Glue] Crawler를 통해 S3에서 Data Catalog로 데이터 추출 (1) | 2022.10.26 |
로그 데이터는 빅데이터 관련 기술의 혜택을 가장 많이 받은 데이터일 것이다.
IT 환경에서 가장 많이 발생하는 데이터이지만, 데이터 처리 기술이 최근처럼 발달하지 않았던 시기에는 처리 비용에 비해 가치가 낮은 데이터로 여겨졌다. (주로 mongoDB와 같은 단순 대용량 데이터를 다루는 NoSQL DBMS를 통해 관리되곤 했다)
하지만 지금은 사물 인터넷(IoT)의 급부상과 함께 그 효용성이 날로 증가하고 있다.
로그 데이터를 수집해야할 상황이라면, 수집 환경과 수집 데이터를 처리하고자 하는 시스템을 고려해 수집 기술을 선택해야 한다.
로그 데이터를 수집하기 위한 수집 기술 선택 시 고려해야할 사항은 확장성, 안정성, 유연성, 주기성이다.
로그 데이터 수집 시 고려사항
| 확장성 | 수집의 대상이 되는 시스템이 얼마나 늘어날 것인가? |
|---|---|
| 안정성 | 수집되는 데이터가 손실되지 않고 안정적으로 저장 가능한가? |
| 유연성 | 다양한 데이터의 형식과 접속 프로토콜을 지원하는가? |
| 주기성 | 수집 데이터가 실시간으로 반영돼야 하는가 혹은 배치처리를 해도 가능한가? |
대표적인 로그 수집기로서 아파치 FLUME과 Chukwa, 페이스북에서 스트리밍 데이터를 처리하기 위해 개발된 Scribe를 들 수 있다.
주요 로그 수집 프로그램
| FLUME (아파치 톱 레벨 프로젝트) | Scribe (페이스북 오픈소스) | Chukwa (아파치 인큐베이터 프로젝트) | |
|---|---|---|---|
| 개발 주체 | 아파치 | 페이스북 | 아파치 |
| 특징 | 대용량 로그 데이터를 안정성, 가용성을 바탕으로 효율적으로 수집 | 수많은 서버로부터 실시간으로 스트리밍 로그 수집 | 하둡의 서브 프로젝트로 분산서버에서 로그 데이터를 수집ㆍ저장ㆍ분석하기 위한 솔루션 |
로그 수집 프로그램 비교
| FLUME (아파치 톱 레벨 프로젝트) | Scribe (페이스북 오픈소스) | Chukwa (아파치 인큐베이터 프로젝트) | |
|---|---|---|---|
| 수집방법 | 다양한 소스로부터 데이터를 수집해 다양한 방식으로 데이터를 전송할 수 있다. 아키텍처가 단순하고 유연하며, 확장 가능한 데이터 모델을 제공하므로 실시간 분석 애플리케이션을 쉽게 개발할 수 있다. | 클라이언트 서버의 타입에 상관없이 다양한 방식으로 로그를 읽어 들일 수 있다. | 수집된 로그 파일을 hdfs에 저장한다. |
| 처리방법 | 각종 Source, Sink 등을 제공하므로 쉽게 확장이 가능하다. | 단, Apache Thrift는 필수. Thrift 기반 Scribe API를 활용해 확장 가능하다. | hdfs의 장점을 그대로 수용했고, 실시간 분석도 가능하다. |
| 특징 | 최근 국내의 빅데이터 솔루션에서 수집 부분에 많이 채택되고 있다. | 페이스북의 자체 Scaling 작업을 위해 설계돼 현재 매일 수백 억 건의 메시지를 처리하고 있다 | 지나치게 하둡에 의존적이라는 단점이 있다. |
'Data Engineering' 카테고리의 다른 글
| Zookeeper의 znode (0) | 2023.05.18 |
|---|---|
| Coursera 데이터 엔지니어링 강의 목록 (0) | 2022.12.08 |
| Spark (0) | 2022.11.20 |
| [에러 노트] AWS Data Crawler로 생성된 DB의 스키마가 업데이트 되지 않는 경우 (0) | 2022.10.26 |
| [AWS Glue] Crawler를 통해 S3에서 Data Catalog로 데이터 추출 (1) | 2022.10.26 |
gRPC는 Google에서 개발한 RPC(Remote Procedure Call) 시스템입니다. 전송을 위해 TCP/IP 프로토콜과 HTTP 2.0 프로토콜을 사용하고 IDL(Interface Definition language)로 protocol buffer를 사용합니다.
gRPC에 대해 이해하기 위해선 다음에 대한 배경지식이 필요합니다.
RPC(Remote Communication Mechanism)
RPC(원격 프로시저 호출)는 한 프로그램이 네트워크의 세부 정보를 이해하지 않고도 네트워크 안의 다른 컴퓨터에 있는 프로그램에서 서비스를 요청하는 프로토콜입니다. RPC는 client-server 모델을 사용합니다. 클라이언트에서 서비스를 요청(function call)하면, 서버에서 서비스를 제공합니다.

HTTP 프로토콜
HTTP(Hypertext Transfer Protocol)는 웹에서 쓰이는 통신 프로토콜입니다. 프로토콜이란 상호간에 정의한 규칙을 의미합니다.
HTTP 프로토콜은 TCP/IP 프로토콜 위의 레이어(Application layer)에서 동작합니다. 각 프로토콜 별 layer 계층은 다음과 같이 간략히 표현됩니다.
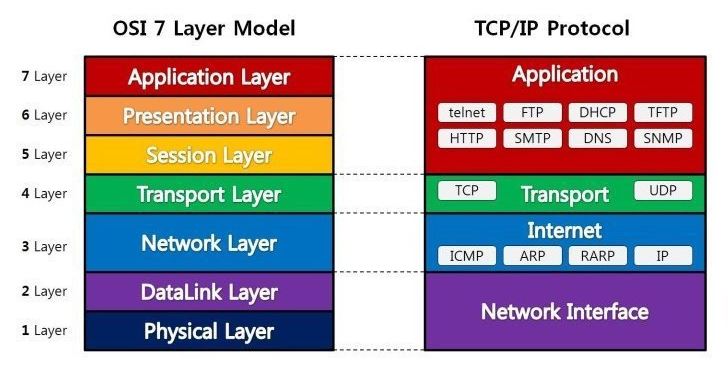
HTTP 프로토콜은 stateless 프로토콜입니다. 여기서 상태가 없다는 의미는 데이터를 주고 받기 위한 각각의 데이터 요청이 서로 독립적으로 관리된다는 의미이며, 이전 데이터 요청과 다음 데이터 요청이 서로 관련이 없다는 말입니다.
HTTP는 기본적으로 서버-클라이언트 구조를 따릅니다. 이 구조에서, HTTP 프로토콜로 데이터를 주고받기 위해서는 아래와 같이 Request를 보내고 Response를 받아야 합니다.

URL(Uniform Resource Locators)은 서버에 자원을 요청하기 위해 입력하는 영문 주소입니다.
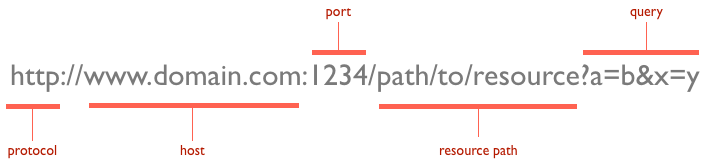
URL을 이용하면 서버에 특정 데이터를 요청할 수 있습니다. 여기서 요청하는 데이터에 특정 동작을 수행하고 싶으면 HTTP 요청 메소드를 이용합니다.
사용하는 HTTP 요청 메소드는 4개입니다.
- Get: 존재하는 자원에 대한 요청
- POST: 새로운 자원을 생성
- PUT: 존재하는 자원에대한 변경
- DELETE: 존재하는 자원에 대한 삭제
HTTP 1.1 버전
HTTP1.1은 1999년 출시 이후 지금까지 웹에서 가장 많이 사용되고있는 프로토콜입니다. HTTP1.1은 기본적으로 연결당 하나의 Request과 Response를 처리하기 때문에 동시전송 문제와 다수의 리소스를 처리하기에 속도 및 성능 이슈를 가지고 있습니다.
대표적인 HTTP 1.1의 단점은 다음과 같습니다.
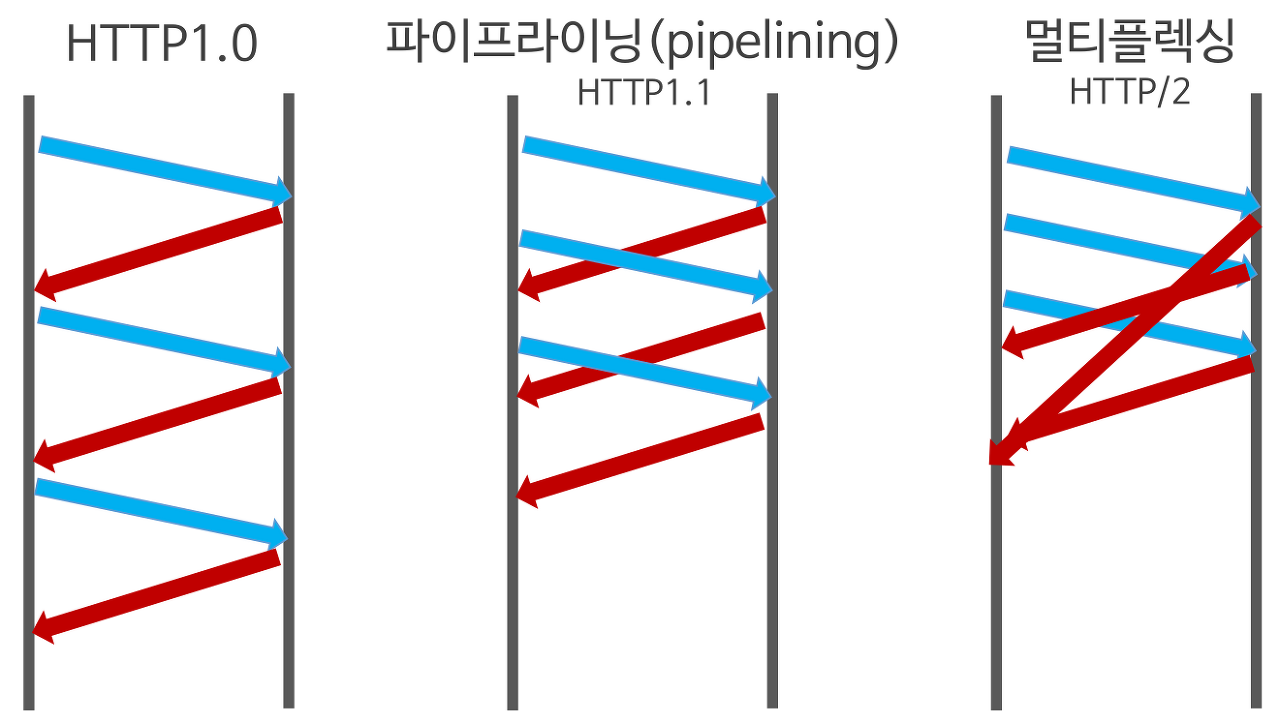
HOLB(Head Of Line Blocking) - 특정 응답 지연
HTTP/1.1은 connection당 하나의 Request를 처리하기에 속도 문제가 있었습니다. 이를 개선할 기법으로 pipelining이 제안됬는데, 이 방식은 하나의 connection을 통해 다수개의 파일을 Request/Response 받을 수 있는 기법을 말하는데, 이 기법을 통해 성능 향상 할 수 있으나 문제점이 있습니다.

만약 앞선 이미지에서 볼 수 있듯 Response가 지연되면, 아래 그림과 같이 두, 세번째 이미지는 첫번째 이미지의 응답처리가 완료되기 전까지 대기하게 됩니다. 이와 같은 현상을 HTTP의 Head Of Line Blocking(HOLB) 이라 부르며 pipelining 기법의 문제점 중 하나입니다.

RTT(Round Trip Time) 증가
HTTP1.1은 하나의 connection에 하나의 request를 처리합니다. 이로인해 하나의 connection마다 tcp 연결을 하며, 신뢰성 연결을 하는 tcp connection은 시작시 3-way handshake, 종료시 4-way handshake가 반복적으로 발생, 이로인한 오버헤드가 발생합니다.
heavy header
HTTP1.1의 header에는 많은 metadata가 저장되어 있습니다. 사용자가 방문한 웹페이지는 다수의 HTTP Request가 발생하게 되는데 이 경우 매 Request마다 중복된 header값을 전송하며, 이 중 cookie가 큰 문제입니다.
HTTP 2.0
HTTP2.0은 HTTP1.1의 프로토콜을 계승해 동일한 API면서 성능 향상에 초점을 맞췄습니다.
Multiplexed Streams
한 connection으로 동시에 여러개 메시지를 주고 받을 수 있으며, Response는 순서에 상관없이 stream으로 주고 받습니다.
Stream Prioritization
리소스간 우선순위를 설정해 클라이언트가 먼저 필요한 리소스부터 보내줍니다.
Server Push
서버는 클라이언트의 요청에대해 요청하지 않은 리소스를 마음대로 보내줄 수 있습니다.
Header Compression
Header table과 Huffman Encoding 기법(HPACK 압축방식)을 이용해 압축을 했습니다.
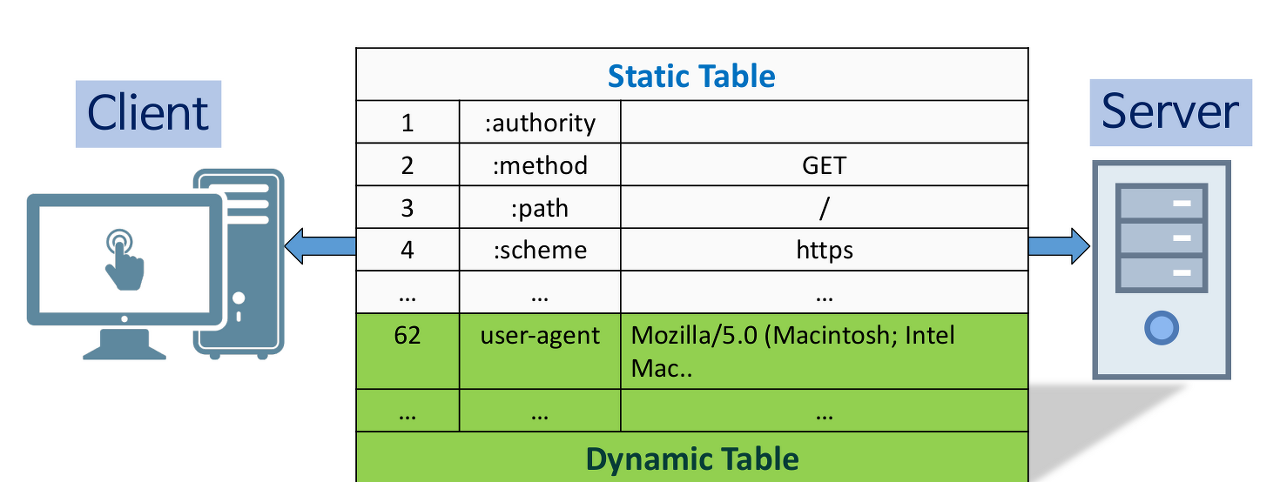
IDL(Interface Definition Language)
서버와 클라이언트가 정보를 주고 받는 규칙이 프로토콜이라면, IDL은 정보를 저장하는 규칙입니다.
대표적인 IDL로는 다음의 3가지가 존재합니다.
XML
XML(eXtensible Markup Langauge)은 어떠한 데이터를 설명하기 위해 이름을 임의로 지은 태그로 데이터를 감싸며, 태그로 사용자가 직접 데이터 구조를 정의 할 수 있습니다.
XML은 HTML처럼 데이터를 보여주는 것이 목적이아닌, 데이터를 저장하고 전달할 목적으로 만들어 졌습니다.
HTTP + XML 조합으로 많이 사용 됩니다.

JSON
JSON(JavaScript Object Notation)은 javascript의 부상으로 많이 쓰이고 있는 데이터 구조입니다. XML이 가진 읽기 불편하고 복잡하고 느린 속도 문제를 해결했습니다. 특히나 key-value로 정의된 구조 자체가 굉장히 사람에게 직관적입니다.
HTTP + RESTful API + JSON 조합으로 많이 사용됩니다.

Protocol buffers(proto)
XML의 문제점을 개선하기 위해 제안된 IDL이며, XML보다 월등한 성능을 지닙니다.
Protocol buffers는 구조화(structured)된 데이터를 직렬화(serialization)하기 위한 프로토콜로 XML보다 작고 빠르고 간단합니다. XML 스키마처럼 .proto 파일에 protocol buffer 메세지 타입을 정의합니다.
Protocol buffers는 구조화된 데이터를 직렬화하는데 있어서 XML보다 많은 장점들을 가지고 있습니다. 대표적인 장점은 다음과 같습니다.
- 간단하다
- 파일 크기가 3에서 10배 정도 작다
- 속도가 20에서 100배 정도 빠르다
- XML보다 가독성이 좋고 명시적이다
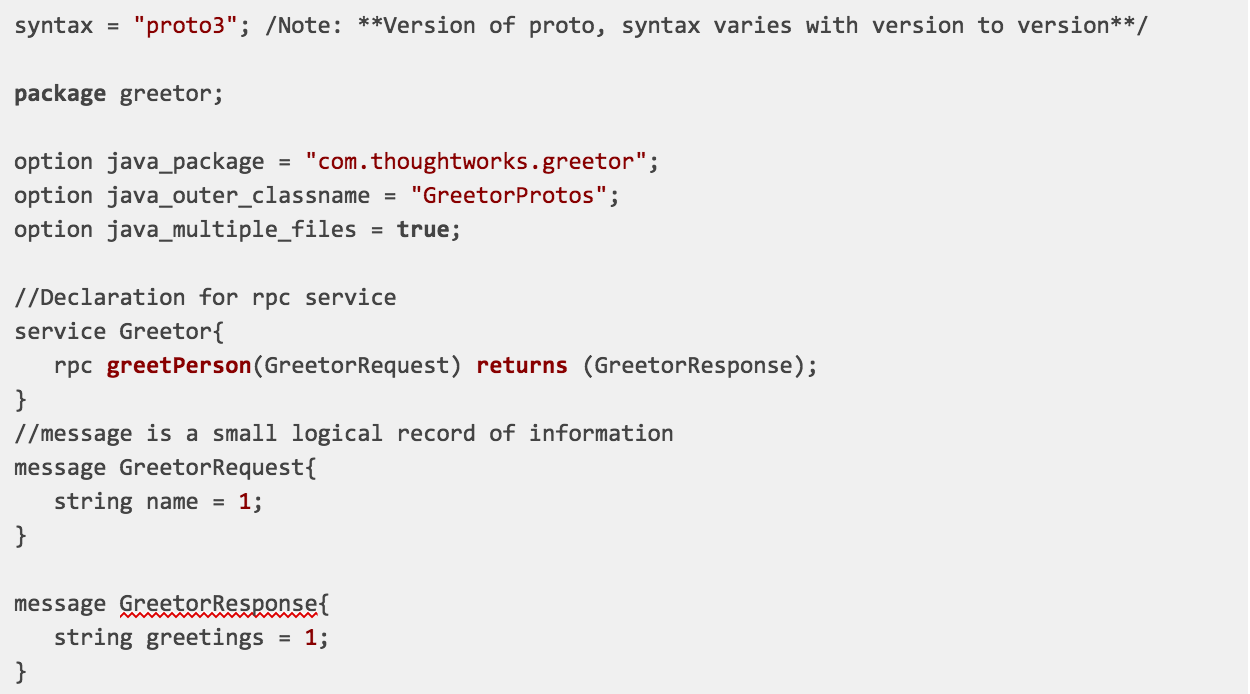
현재 proto2와 proto3가 있으며, proto3의 사용을 권장합니다.
3개 방식 비교
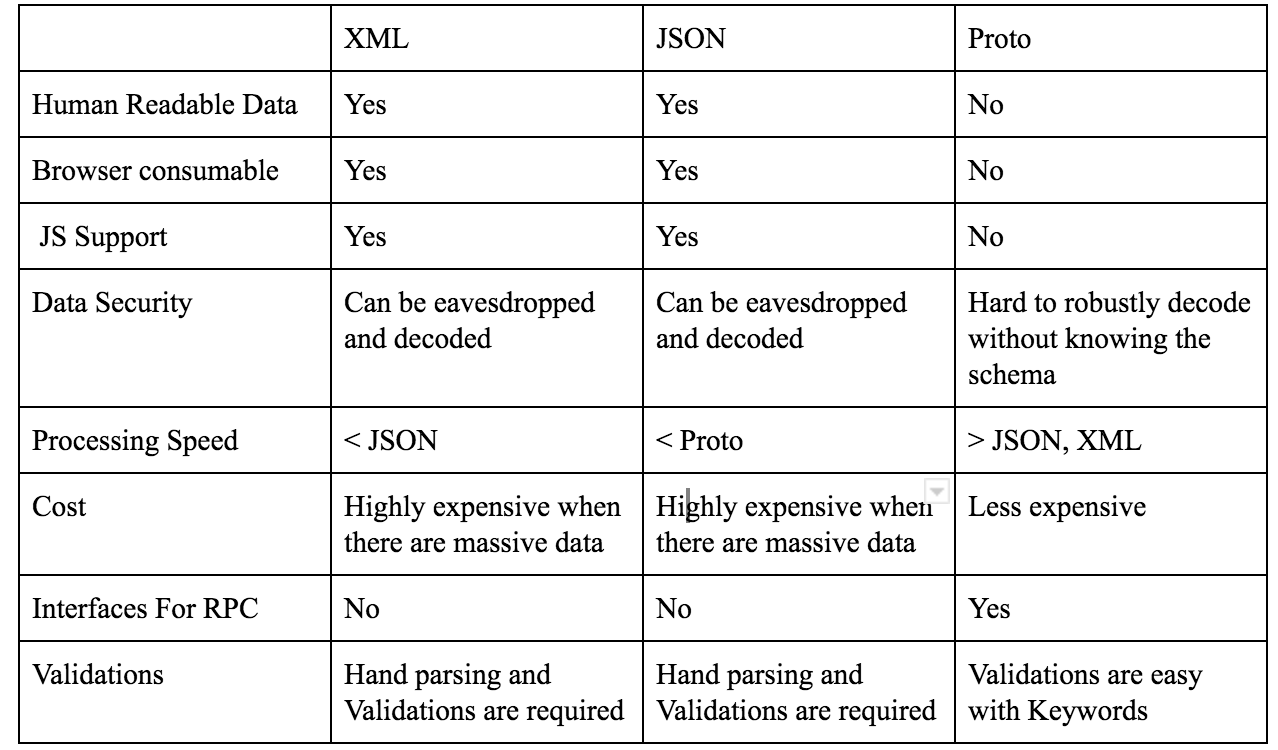
다음은 XML, JSON, Proto 세가지 방식을 비교한 표입니다.
그래서 gRPC가 뭔데?
gRPC는 구글에서 만든 RPC 플랫폼이며 protocol buffer와 RPC를 사용합니다.
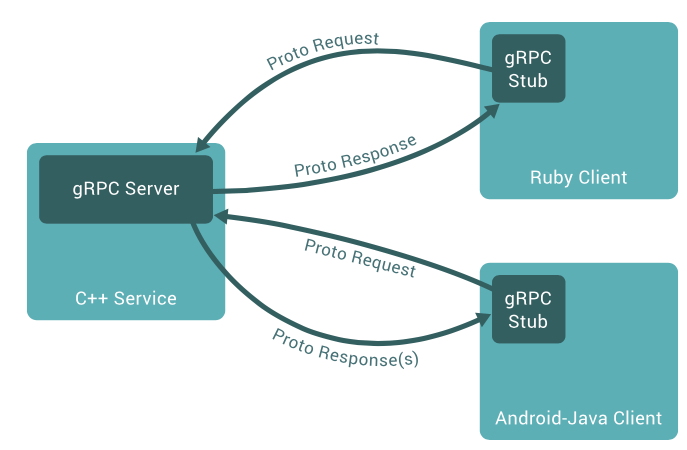
최신 버전의 IDL로 proto3를 사용합니다. Java, C ++, Python, Java Lite, Ruby, JavaScript, Objective-C 및 C#에서 사용 가능합니다.
SSL/TLS를 사용하여 서버를 인증하고 클라이언트와 서버간에 교환되는 모든 데이터를 암호화합니다. HTTP 2.0을 사용하여 성능이 뛰어나고 확장 가능한 API를 지원합니다.
gRPC에서 클라이언트 응용 프로그램을 서버에서 함수를 바로 호출 할 수 있어 분산 MSA(Micro Service Architecture)를 쉽게 구현 할 수 있습니다. 서버 측에서는 서버 인터페이스를 구현하고 gRPC 서버를 실행하여 클라이언트 호출을 처리합니다.
'Programming Language > Go' 카테고리의 다른 글
| protocol 버퍼에 대한 소개 (0) | 2022.11.15 |
|---|---|
| [go 모듈 소개 - 2. logrus] 더 자세한 로깅 모듈 (0) | 2022.11.15 |
| [go 모듈 소개 - 1. gorm] Golang을 위한 ORM 라이브러리 (0) | 2022.11.15 |