





해당 글에서는 S3에 위치한 데이터를 Glue 크롤러를 통해 S3에 위치한 CSV 파일을 Data Catalog Database로 이동시키는 것을 목표로 한다.
본격적인 글 작성에 앞서서 Glue의 Job을 생성하거나 이후 Athena를 통해 데이터 추출 작업을 용이하게 수행하기 위해서는 Glue의 Data Catalog Database를 해당 데이터의 스키마와 함께 저장해야할 필요가 있다. 물론 S3를 통해서 바로 작업이 가능한 경우도 많지만, 작업이 그리 복잡하지 않으므로 필요하다면 Data Catalog를 활용하는 것이 좋아보인다.
데이터 소개

1786373 개의 row와 34 개의 Column 값을 가지고 있으며, 약 483 MB의 크기를 가진 CSV 파일이다. 내부 데이터는 한글과 숫자, 영어가 모두 들어가 있으며 UTF-8로 인코딩이 되어 있다. 데이터의 크기가 어느정도 크기 때문에 엑셀로는 파일이 열리지 않으며, Athena를 통해 SQL 쿼리를 통해 데이터를 확인해야 한다.
Glue 소개
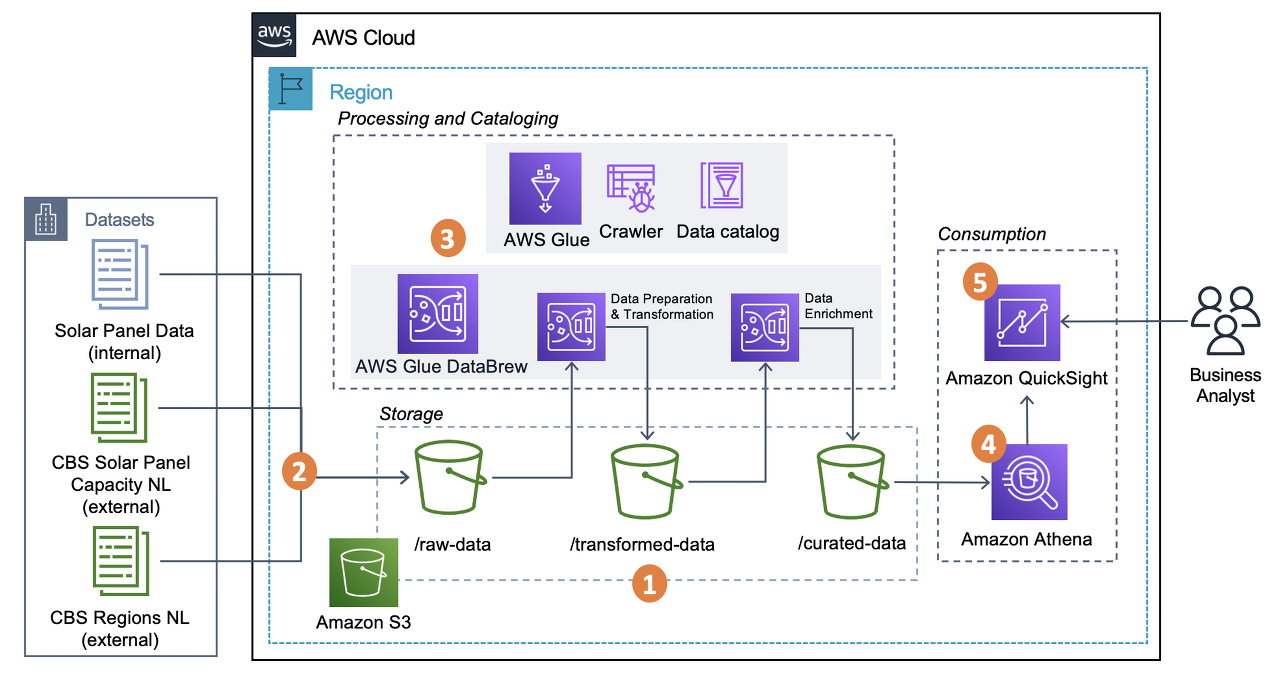
AWS 글루(Glue)는 자동 추출, 변환 및 로드(ETL) 프로세스를 통해 분석 데이터를 준비하는 서버리스 데이터 서비스이다. S3, RDS, Glue data catalog와 같은 다양한 소스로부터 원천 데이터를 받아와 해당 데이터의 변환 작업을 진행한 후, 결과물을 Load하는 식으로 프로세스가 진행된다.
Glue Data Catalog 소개
Data Catalog를 활용한다면 다양한 원천 데이터를 하나의 중앙 집중식 데이터 카탈로그로부터 관리할 수 있게 된다. 주로 Database로 관리가 이뤄지며, Crawler를 통해 해당 데이터의 메타데이터 추론과 함께 S3와 같은 다양한 원천으로부터 데이터를 추출할 수 있다.
이제 본격적으로 작업을 진행해보자.
Step 1. Data Catalog DB 생성
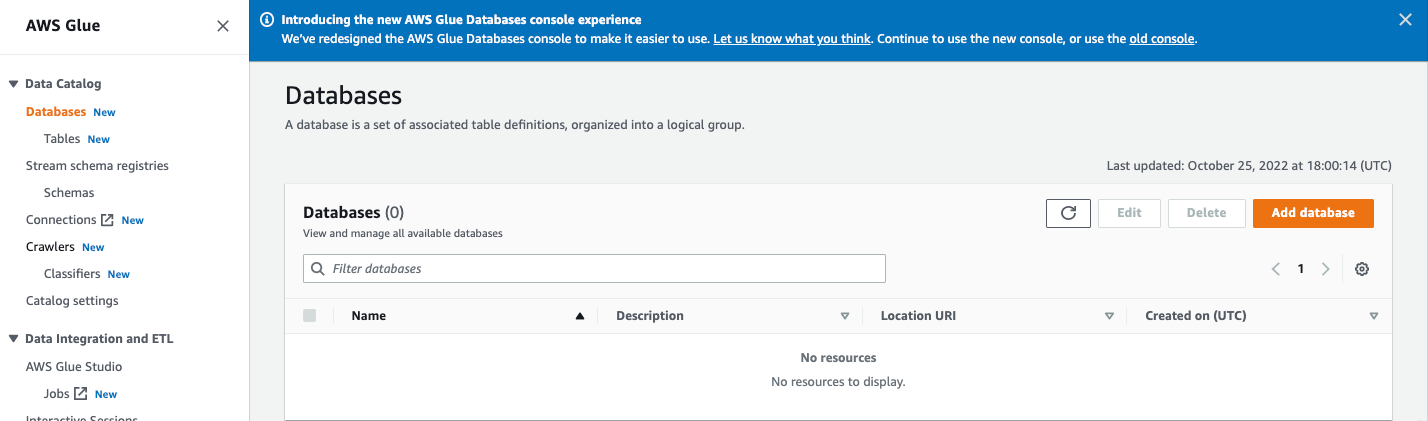
AWS 검색창에 Glue로 들어가, Data Catalog 하단의 Database로 들어간다. Add database 를 선택한다.

Name만 지정해주고, 그 외의 Location과 Desciption은 필요에 따라 작성해준다.
Step 2. Data Catalog Crawler를 사용하기 위한 권한 준비

IAM을 검색해 들어가 역할로 들어간 후 역할 만들기 선택

신뢰할 수 있는 엔터티 유형 중 AWS 서비스 선택한다. 사용 사례란에는 다른 AWS 서비스 사용 사례 중 Glue 검색 후 선택하면 된다.

이후 AdministratorAccess를 선택하여 Glue에서 모든 조작을 할 수 있는 권한을 부여한다.
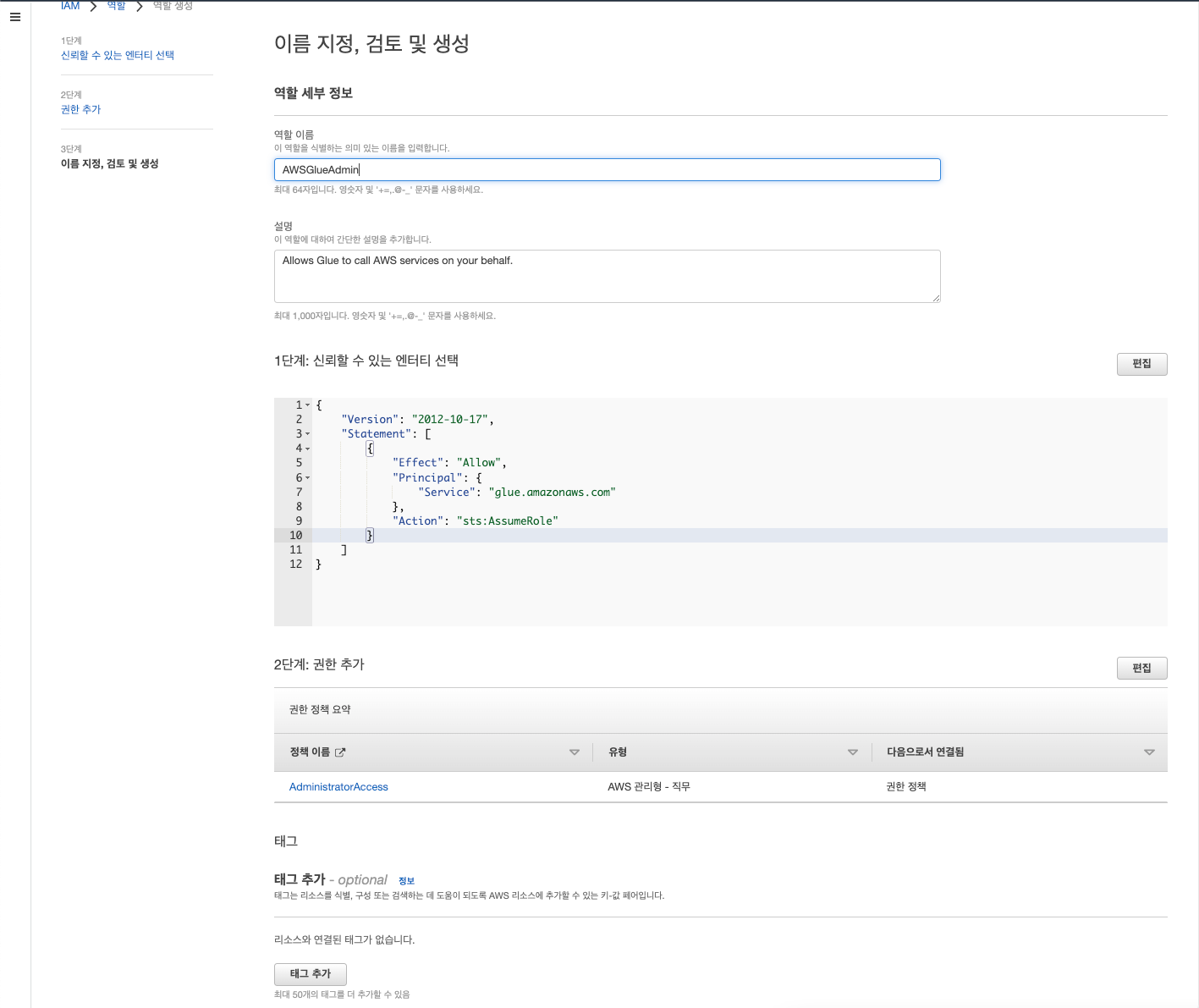
이후 이름을 작성해주며 역할을 생성한다.
정책을 새롭게 작성하며 POLP를 준수하면 베스트이겠으나 해당 글에서는 권한에 대해서는 자세히 다루지 않겠다.
Glue Data Crawler 생성
역할이 정상적으로 생성되었음을 확인했다면 다시 Glue로 돌아가 Crawlers로 들어간다.

Create Crawler를 선택하고 크롤러의 이름을 먼저 작성한다.

Step 2에서는 다양한 원천 데이터를 선택할 수 있다. 현재 목표는 하나의 원천 데이터만이 존재하므로 단순히 해당 데이터만을 추가한다.
먼저 아직 작성된 Glue Data Catalog 테이블이 존재하지 않으므로, Not yet을 선택해준다.
Data Sources의 Add a data source를 선택할 경우, Data Source, Network connection, S3 Path 등을 지정해줄 수 있다.

먼저 가져오고자 하는 데이터의 소스를 지정해준다. 앞서 소개한 데이터는 S3에 위치하고 있으므로 이를 선택해주었다.
Network connection 같은 경우에는 당장은 필요가 없으나, 필요한 경우에는 기존 VPC로부터 엔드포인트를 추가해준 다음, 새로운 connection을 생성 후 등록하는 방식으로 사용할 수 있다.
S3 Path에는 목표로 하는 데이터의 상위 폴더를 지정해준다. 해당 파일만을 지정해주는 경우 크롤러의 실행은 정상적이였으나 테이블이 생성이 되지 않음을 확인했다. 현재 목표로 하는 데이터의 S3 URL은 ecomm_fc_transformed/ecomm_fc_transformed.csv이다.
아래 크롤링 정책은 현재 달성하고자 하는 목표와 부합하므로 유지한다.

앞서 생성해주었던 역할을 부여한다. (이름이 조금 다르지만, 앞서 생성한 역할과 동일하다.)

마지막으로 맨 처음에 생성했던 Database를 선택해준다. 생성이 되지 않았다면 Add database를 통해서도 생성이 가능하다. (현재 데이터베이스에는 아무런 스키마 정보가 주어져있지 않으며 이름만 부여되어 있는 상태이다.)
이후 리뷰 후 크롤러 생성을 마무리한다.
Step 3. 크롤러 실행
크롤러가 정상적으로 생성되었다면, crawlers 초기 페이지로 다시 돌아가면, 앞서 생성한 크롤러를 확인할 수 있다. 그럼 이제 해당 크롤러를 선택하고 Run을 눌러 실행해보자.
약 3분 이상의 시간이 걸린 후, 다음과 같은 Success 메세지를 확인하면 크롤러가 정상적으로 실행되었음을 확인할 수 있다.

이후 Database의 Table에 들어가 정상적으로 크롤링 결과가 반영되었는지 확인한다.

다음과 같이 테이블이 생성이 되었다면 성공적으로 해당 작업이 마무리되었음을 알 수 있다.
'Data Engineering' 카테고리의 다른 글
| Zookeeper의 znode (0) | 2023.05.18 |
|---|---|
| Coursera 데이터 엔지니어링 강의 목록 (0) | 2022.12.08 |
| Spark (0) | 2022.11.20 |
| 로그 데이터 수집 (0) | 2022.11.18 |
| [에러 노트] AWS Data Crawler로 생성된 DB의 스키마가 업데이트 되지 않는 경우 (0) | 2022.10.26 |
컴퓨터의 커널이라고 함은 무엇을 의미할까? 학부생 1학년 시절 개발자 중에 제일 머리 똑똑한 사람은 커널 개발자라는 말을 얼핏 듣고 생긴 커널의 첫 인상은 어렵다 복잡하다였다. 사실 커널이 무엇인지도 몰랐지만, "컴퓨터의 극의에 다다른 이들만이 이해할 수 있는 영역" 정도로 받아들였던 것 같다.
운영 체제 과목을 수강하고, 커널에 대해서 어느정도는 이해하고 있다고 생각했지만 막상 다른 분야에 종사하는 사람에게 커널이란 이런 이런 역할을 하는 친구야라고 자신있게 말하기엔 여전히 굉장히 어색하다.
예를 들어 운영 체제는 커널과 같은 말인지. 커널을 접근한다는게 정확히 무슨말인지에 대해서 스스로 질문을 해봤으나 그 답이 쉽게 나오지 않는다.
해당 글에서는 커널은 무엇을 하는 친구인지, 또 운영체제와의 어떤 관계를 갖는지를 중심으로 커널을 소개하고자 한다.
Kernel이란?

kernel을 papago에 돌려보면 알맹이라는 번역 결과를 얻을 수 있다. 도대체 왜 알맹이일까를 살펴보면, Unix 구조를 보면 바로 이해가 된다. 맨 위의 application, 그리고 가장 안쪽에 알맹이로서 kernel이 존재한다.
그 외에 shell, system calls, library routines 등이 application의 요청을 받아 중요한 역할을 수행한다.
근데 여기서 알맹이라는 이해도 사실 조금 추상적이다. 그래서 Unix 운영 체제의 핵심이라고 불릴 수 있는 요소는 무엇일까?
이를 이해하기 위해서는 Unix 시스템에서 프로그램이 동작하는 과정을 살펴보아야 한다.
Unix 운영 체제에는 두 가지 mode가 존재한다.
바로 user mode와 kernel mode가 그것이다.
user mode는 일반 사용자가 프로그램을 실행하면 구동되는 모드이다. 조금만 더 쉽게 설명하자면, 우리가 크롬을 열게되면, 이때 컴퓨터는 유저 모드에서 크롬이라는 application의 실행을 처리한다. 다만 컴퓨터 리소스에 직접적으로 접근할 수 없다. 즉 일반 유저가 자유롭게 컴퓨터 자원을 접근하는 것이 Unix에선 막혀있다.
kernel mode는 일반 사용자가 직접적으로 접근할 수 없는 모드이라고 일단 간단하게 생각을 해보자.
여기까지가 간단한 설명이였고 이제 본격적으로 둘을 이해하려면 Unix에서 프로그램이 어떻게 실행되는지를 이해해야 한다.

위의 [그림 1-2]은 C로 작성된 프로그램(user application)이 실행되는 과정을 user mode와 kernel mode 두 모드를 중심으로 표현하였다.
프로그램을 클릭하여 시작한다고 생각해보자. 프로그램을 실행하려면 당연히 컴퓨팅 자원이 필요하다. 당장 생각나는 CPU, MEM, DISK와 같은 것 외에도 네트워크의 연결(소켓이라 불리는), 키보드나 모니터와 같은 주변 장치와 같은 것들도 모두 컴퓨팅 자원으로써 프로그램 실행에 기여한다.
그럼 프로그램은 어떻게 자원을 받아서 실행되는 걸까? 바로 user mode와 kernel mode의 긴밀한 연결을 통해 프로그램은 자원을 할당받는다.
앞서 언급하엿듯 user mode에서는 직접적으로 접근할 수 없다. 때문에 user는 system call을 통해 컴퓨터 리소스를 할당해달라는 요청을 system call interface(system call의 처리를 1차적으로 담당하는 친구라고 보면 된다) 보낸다. system call interface는 user mode와 kernel mode를 매개해주는 역할을 수행한다고 이해할 수 있겠다.
kernel mode에 진입하면 system call interface에서는 받은 요청을 처리하기 위해, 우선 system call vector table이라는 곳으로 요청을 매개한다. system call vector table에서는 해당 시스템 콜 코드가 어디에 위치해 있는지를 알려주는 역할을 수행한다. open이라는 시스템콜 요청이 들어오면 system call vector table에서는 해당 시스템 콜을 실행하기 위해 테이블을 마구 뒤지게 된다. 그러다 해당하는 system call을 찾으면 해당 하는 위치로 가서 해당 system call 코드를 실행한다.
최종적으로 실행 결과를 system call interface에 돌려주고, 이는 다시 user application에 전달된다.
다 쓰고나니 내용이 되게 많아보이지만 사실 핵심은 간단하다. user mode에서는 컴퓨팅 리소스에 접근할 수 없고 항상 kernel mode를 거친다는 것.
이와 관련해서는 이야기를 이만 줄이도록 하고, 시스템콜에 대한 추가적인 내용은 작성한 다른 글을 참고해보시면 좋겠다. 참고링크: [os] introduction
다시 본론으로 돌아와서, 그럼 kernel은 무엇일까? 바로 앞의 리소스를 할당해주는 주체가 바로 커널이다. 커널은 단단한 알맹이로서 전화기, 노트북, 서버 컴퓨터 가리지 않고 하드웨어의 모든 주요 기능을 제어하고 조율한다.
유저는 kernel에 직접적으로 접근하는 대신 shell과 library routine(c의 lib이라고 생각)을 통해 system call을 system call interafae에 전달하거나 아니면 곧바로 system call interface에 system call 요청을 보내는 식으로 해당 프로세스(프로그램이 실행된 상태) 실행에 필요한 자원을 요구한다.
커널의 역할
커널은 크게 총 4가지의 기능을 수행한다.
- CPU 관리: 어떤 프로세스가 CPU를 얼마나 오랫동안 점유할지를 결정
- Memory 관리: RAM 메모리를 어떻게 사용할지 또 무엇을 저장할지를 결정
- Device Driver 관련 작업: 하드웨어와 프로세스 사이에서 중재자의 역할을 수행
- System call 관련 작업: System call api를 통한 프로세스의 리소스 요청을 처리
이와 관련된 내용 전반을 운영 체제라는 교과에서 배우게 된다.
커널과 운영 체제는 같은 말일까?
결론부터 말하자면 그렇지 않다. 운영 체제는 커널을 포함하여 다른 추가적인 소프트웨어들이 내장되어 있다. 다르게 표현하자면 Kernel은 운영 체제의 주요 구성 요소 중 하나이다. 커널 위에 유틸리티 소프트웨어들과 같은 친구들이 붙게 되면 이를 비로소 OS라고 부른다.
근데 다만 OS의 대부분을 커널이 차지하기 때문에, 어떻게 보면 커널이 OS라고 볼 수도 있겠지만 엄밀하게 따지자면 커널은 OS와는 다른 개념이라고 이해해야 한다.
참고 자료
[Linux 커널이란 무엇일까요?
Linux 커널은 Linux 운영 체제(OS)의 주요 구성 요소이며 컴퓨터 하드웨어와 프로세스를 잇는 핵심 인터페이스입니다.
www.redhat.com](https://www.redhat.com/ko/topics/linux/what-is-the-linux-kernel)
'CS' 카테고리의 다른 글
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
|---|---|
| Cache Memory 소개 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
| [OS] Introduction (1) | 2022.09.23 |
| [리눅스 프로그래밍] 리눅스 계보 (2) | 2022.09.23 |
해당 글은 공룡책이라고 불리우는 Operation Systems Concepts를 기반으로 한다.
Chapter 1 Introduction
해당 챕터에서는 우리가 배우게 되는 OS가 정확히 무엇을 의미하는지를 설명함과 동시에 앞으로 배우게 될 내용들을 하나씩 가볍게 소개한다. Chapter 1의 경우 개인적으로 무겁게 마음의 준비를 하면서 보기보단 조금 내려놓고 이러이러한 내용들을 배운다 정도로만 알아도 괜찮다고 생각한다. 분명 Introduction이라고 써놨지만, 무겁게 읽다보면 Intro가 아니라 한참을 씨름하다 Chapter 1의 벽에 가로막혀 소위 시작부터 막혀버리는 불상사가 충분히 생길 수 있을 것 같다. 마음을 편하게 가지고 꾸준히 읽어 나가다보면 이후의 챕터에서 나오는 다시 등장하는 내용들이 많으니 너무 급하게 생각하지 말자.
1.1 What Operating Systems Do
세상에는 다양한 OS가 존재한다. PC하면 떠오르게 되는 WINDOW, 스타벅스 출입증과 같은 맥 OS, 쓰면 컴퓨터 엄청 잘해보이는 리눅스와 그 다양한 버전들 ... 해당 섹션의 주제는 그렇다면 우리가 OS라고 부르는 것들의 정의가 무엇이고 우리는 OS를 왜 쓰게 되는지이다. OS는 다양하다. 때문에 각각의 OS가 가지는 특성이 다르며, OS는 이를 만드는 이들과 설계하는 자들에 의해 다양한 형태로 표현된다. 때문에 모든 OS를 아우르는 공통된 정의를 말하기가 굉장히 조심스러워진다.
다만, OS라 함은 적어도 이 두 가지의 역할은 적어도 수행할 수 있어야 한다.
- 컴퓨터의 하드웨어를 제어할 수 있어야 한다.
- 프로그램의 실행을 제어할 수 있어야 한다.
동시에 OS는 프로그램이다. 때문에 우리는 OS를 다음과 같이 정의할 수 있겠다.
An operating system is a program that manages the computer hardware and also that controls the execution of programs
이때 주의해야할 용어가 있는데, 바로 execution of programs라는 표현이다. 뒤에서 다시 등장하겠지만, 우리가 프로그램을 실행한다는에는 표현에는 두 가지 해석이 가능하다.
- Execute the program
- Run the Program
해당 차이를 이해하기 위해서는 프로그램과 프로세스를 이해할 필요가 있다.
먼저, 프로그램이라고 함은 한마디로 말하자면 실행 가능한 파일을 의미한다. 핵심은 실행이 가능할 뿐, 실행 여부는 중요하지 않다는 것이다. 더 투박하게 표현하자면 일종의 실행 가능한 코드 덩어리를 우리는 프로그램이라고 부르게 된다.
프로세스는 해당 프로그램이 Execute되면 생성되는 인스턴스를 의미한다. 이게 무슨 말인고 하면, 우리가 프로그램 아이콘을 더블 클릭을 하게 되는 경우, 컴퓨터는 프로그램을 실행하고자 프로그램에 대한 정보들을 메인 메모리 상에 올리게 된다. 우리는 이를 프로그램이 Execute되었다고 표현하게 된다. 그런데 100GB 짜리 거대한 게임을 실행한다고 하자. 해당 게임이 뜨기까지는 어느정도의 딜레이가 발생한다(해당 주제에 대한 자세한 설명은 5장 Scheduling 단원에서 자세히 배운다.). 우리는 프로그램은 분명 Execute 하였지만 아직 우리가 원하는 동작이 수행된 상태는 아니다. 문제가 없다면 잠시 후에 게임창이 뜨게 되는데, 이때를 프로그램이 RUN되는 상태라고 이해할 수 있다.

즉, 다시 말하면 OS는 프로그램이며, 실행 가능한 코드 덩어리에 불과하다. 다만 코드 덩어리가 워낙 길고, 그 구조가 복잡하기 때문에 컴파일하는데만 한 세월이 걸릴 수도 있는 그런 프로그램이다. 동시에 적어도 두 가지의 행동이 가능해야 하는데, 첫 번째는 컴퓨터 하드웨어를 제어할 수 있어야하고, 두 번째 프로그램의 Execute를 제어할 수 있어야만 한다.
그렇다면 OS는 우리 컴퓨터 상에서 어디에서 위치하게 될까? 다음 그림을 살펴보자

그림 상에서 확인할 수 있듯, OS는 하드웨어와 애플리케이션 사이에 자리하고 있다. 우리가 메모장에 글을 쓰는 과정을 생각해보자. user로서 나는 키보드를 통해 메모장에 무엇인가를 적으려고 시도하였다(user -> application programs). 컴퓨터는 키보드를 인식하고 I/O 동작이 이뤄진다. 메모장이 요구한 일련의 요구사항을 효율적으로 하드웨어에게 접근할 수 있도록 OS가 이를 매개한 것이다. OS의 정의에서처럼 OS는 아래로는 하드웨어를 위로는 프로그램을 제어하는 또 다른 하나의 프로그램이다.
때문에 시스템에서 활용되는 system program과 우리가 소위 App이라고 부르는 application program 모두 직접적으로 하드웨어에 접근할 수 없으며, system call interface라는 OS에서 제공하는 API를 통해 하드웨어에 간접적으로 접근할 수 있게 된다. 이는 2장에서 더 자세하게 배우게 된다.
이를 다시금 생각해보면 OS를 다음과 같이도 정의할 수 있다.
- OS is a resource allocator (= manages the computer hardware)
- OS is a control program (= controls the execution of programs)
이때, resource라 함은 CPU, Memory Stroage, I/O Device와 같은 하드웨어를 의미한다. OS는 다양한 알고리즘을 통해 하드웨어에 대한 다른 프로그램들 요청을 잘 조율하게 된다. 컴퓨터의 자원은 무한할 수 없기에 언제나 자원의 한계라는 문제에 직면하게 된다. OS는 조율자로써 자원의 효율적인 분배를 통해 가능한한 최적의 방식을 통해 다양한 요청들과 하드웨어 간의 충돌을 효율적으로 처리한다.
또 프로그램은 에러나 시스템을 잘못 활용하는 프로그램 등을 방지하는 제어 프로그램으로서 기능한다. Segmentation fault, Bus Error 등이 그것이다. OS는 잘못된 프로그램의 버그에 대해서 적절한 에러 메세지를 통해 유효하지 않은 프로그램들에 대해서 제어자 역할을 수행한다.
또 책에는 다음과 같은 정의를 통해서도 OS를 표현할 수 있다고 한다.
A more common definition, and the one that we usually follow, is that the operating system is the one program running at all times on the computer - usually called the kernel
해석하자면, OS는 컴퓨터가 켜져있는 동안 항상 실행되는 하나의 프로그램으로, kernel이라고도 부른다는 의미이다. 이때, 걸리는 점이 있었는데 그렇다면 OS와 kernel를 같은 의미로 사용해도 되느냐이다. 결론부터 말하자면 반은 맞고 반은 틀리다.
우리가 소위 OS라고 부르는 것에는 앞서 말했던 두가지 기능이 존재한다. 1) resouce allocator, 2) control program 이 그것이다. 이 두가지 기능을 수행하는 프로그램을 우리는 Kernel이라고 부르게 된다. 다만, OS는 앞서 언급하였듯 종류가 다양하고, 각각 OS라고 정의하여 부르는 범위가 다양하다. 때문에 우리가 접하는 대부분의 상당 수의 OS는 해당 기능 외에도 추가적인 소프트웨어를 포함하는 경우가 많다. 즉, OS 중 코어가 되는 두가지 기능을 지닌 프로그램을 우리는 Kernel이라고 부르게 되며, 해당 기능 외에 추가적으로 내재되어있는 프로그램까지 우리는 OS라고 부르게 된다.
이에 대한 예시로, 안드로이드 OS를 생각해볼 수 있다. 우리가 소위 안드로이드라고 부르는 Android os를 살펴보자.

가장 하단의 Linux Kernel를 주목하자. 안드로이드는 Linux를 기저에 두는 OS이다. 그러나 안드로이드 개발자들은 평소에 개발하면서 Linux의 내부 구조에 능통하지 않아도 괜찮다. 상위 계층의 Andriod Framework가 이를 감싸주고 있기 때문이다. 우리가 안드로이드라고 부르는 OS는 가장 하단의 Linux Kernel만을 의미하지는 않게 된다. 이 외에도 그림에서 볼 수 있는 Libraries, Runtime, Framework ... 같은 주요 프로그램들이 OS 내부에 함께 존재한다. 혹시나 후에 둘의 차이가 혼동된다면 Android os 내부에 Linux Kernel이 있음을 상기해보자.
핵심은 Application 영역에서 컴퓨터의 하드웨어로의 직접적인 접근이 불가능하며, 언제나 OS 내부의 Kernel을 거쳐 Kernel이 제공하는 API를 통해서만 하드웨어와 커뮤니케이션이 가능하다는 것이다. read(), write() 함수를 C언어에서 호출하는 경우를 생각해보자. 해당 함수는 프로그램으로써 스토리지에 저장이 되어있을 것이다. 우리는 OS에서 제공하는 read / write 함수를 통해 스토리지에 접근할 수 있게된다. 또 다른 예시로 malloc() 함수를 들 수 있겠다. 일반적으로 알려져 있듯, C언어에서 힙 영역을 사용하기 위해 우리는 malloc() 함수를 사용한다. 다만, 그 자세한 내부 원리까지는 우리가 알지 못하며, 알 필요가 없다. 다만 C언어를 통한 프로그램을 작성하면서 이만큼의 데이터를 저장하기 위해, 공간을 할당해달라는 요청을 할 뿐, 그 하위의 동작은 OS가 전담한다. 즉, 일반적인 웹의 API와 그 철학을 대부분 공유한다.
그러나 해당 함수를 API라고 하진 않는다. API는 해당 함수가 호출된 이후의 일종의 약속된 신호 즉, System Call을 의미한다. 해당 챕터와 다가오는 Chapter 2에서 다시금 다루겠지만, 일반 Application program, System program 모두 OS를 거쳐 하드웨어와의 상호 작용을 하게되는데, 이때 항상 System Call 이라는 약속된 신호를 통해 커뮤니케이션을 하게 된다. 그러니까, 앞서 그림 1-2에서 살펴보았던 컴퓨터 구조도에서 OS layer와 System and Application program Layer 사이에 System call Layer가 중간을 매개한다고 생각할 수 있겠다.
1.2 Computer-System Organization
OS 는 앞서 언급하였듯이 하드웨어 부분의 다양한 부품 / 기기들과 커뮤니케이션을 하게 된다. 뿐만 아니라 각 하드웨어끼리는 서로 맡은 바 역할에 따라 수행하는 역할이 분화되어 있어, 같은 하드웨어 시스템 내에 다른 부품 / 기기들과 긴밀하게 연결되어야 한다.
해당 섹션에서는 이러한 커뮤니케이션이 어떻게 이뤄지는지 그 간단한 원리를 살펴본다.
이를 설명하기 위해 그림을 하나 가져왔다. 아래 그림은 우리가 컴퓨터 하드웨어 시스템이라고 부를 수 있는 기기들의 조합을 보여준다.

OS는 다양한 기기들이 긴밀하게 연결될 수 있도록 동작한다. 대표적인 예시로 프로그램을 Execute하는 경우가 있을 것이다. OS는 하드웨어 위에서 유저의 요청을 받아 프로그램을 Execute 해야 한다. 그러기 위해선 우선 CPU가 프로그램을 시작할 수 있도록 명령을 내려야 할 것이다. 이때 해당 프로그램의 코드는 디스크에 존재한다. 다만, 우리가 Disk에 있는 데이터를 그대로 쓸 수 없기에 이를 메모리에 올리게 된다(소위 로딩이라고 부르는 과정). 동시에 키보드나 모니터와 같은 I/O 기기로 부터 들어오고 나가는 신호들이 있을 것이다. 이러한 데이터 또한 마찬가지로 메모리에 올린 다음에야 우리가 원하는 동작을 수행할 수 있다.
이때 데이터는 bus라는 형태의 와이어를 거쳐 이동한다. 간단하게 말해서 데이터가 이동하는 통로라고 생각하면 될 것 같다. 이처럼 다양한 하드웨어가 bus라는 데이터 통로로 서로 연결되어 서로의 데이터를 교환한다.
조금만 더 깊게 들어가보자. 먼저 메모리의 중요성에 대해서 언급하고자 한다. 먼저 지르고 가자면 메모리가 중요한 이유는 CPU와 Interaction을 주고 받을 수 있는 유일한 데이터 저장소이기 때문에 그렇다. 앞서 프로그램을 Execute할 때도, 디스크는 CPU와 직접적으로 작용하는 대신 메모리에 로딩을 거쳐 해당하는 데이터를 사용하였다. I/O 기기도 마찬가지이다. 키보드에서 값이 쓰여질 때도, 모니터가 현재의 화면을 출력하고 싶을 때에도 항상 메모리를 거쳐 CPU와 상호작용을 주고 받을 수 있다. I/O의 경우에도 I/O 컨트롤러라고 하는 하드웨어 장치를 가지고 있으며, 해당 장치에도 작은 메모리 저장소를 가지고 있다. 디스크와 마찬가지로 해당 저장소 또한 CPU와 직접적으로 데이터를 주고 받을 수 없다. 오직 메모리만이 CPU와 데이터를 주고 받는다. 때문에 bus의 구조를 살펴보면 모든 bus의 중앙에 메모리가 위치하는 것을 볼 수 있다. 메모리는 일종의 데이터 교환의 핵심으로써 프로그램의 실행과 데이터 교환에 중간에서 매우 중요한 역할을 수행한다. 그래서 CPU와 I/O 기기들의 경우 mermory의 접근 권한을 얻기 위해서 서로 경쟁하게 된다고 가볍게 알아두자.
그렇다면 우리가 I/O를 수행한다고 하는 의미에 대해서 집중적으로 들어가보고자 한다. 앞서 bus를 통해 데이터가 이동한다는 사실을 잠깐 언급하였다. 그렇다면 도대체 어떤 과정을 거쳐 데이터가 이동한다는 것인지에 대해서 이야기해보자. 로딩을 하는 상황을 생각해보자. CPU는 데이터를 가져오기 위해서 최초로 I/O를 실행한다는 의미에서 I/O initiation을 I/O Device에 보낸다. 컨트롤러는 이를 인지하고 필요한 데이터를 메모리에 전송한다. 이후 데이터가 필요할 때마다 CPU는 디스크에 요청을 보내고 해당하는 데이터를 그때마다 메모리에 계속 올릴 수 있다. 이 방식은 물론 동작 자체에는 문제가 없지만, I/O 과정에 CPU가 계속해서 데이터가 필요할 때마다 데이터 요청을 보낸다는 측면에서 비효율적이다. 때문에 이러한 방식은 현재 사용되지 않는다.
I/O 기기 혹은 디스크와 메모리의 Interaction, 즉 데이터가 왔다갔다하는 것을 I/O라고 부른다.
관련해서 I/O transaction은 I/O 버스를 통해 데이터가 이동하는 것을 의미하는데, 때문에 I/O transaction은 I/O 과정에서 반드시 수행될 수 밖에 없다.

대신 대부분의 OS에서는 DMA라는 방식을 사용하여 CPU의 개입을 최소화한다. DMA의 원리는 다음과 같다. CPU는 최초의 I/O initiation을 I/O Device에 보낸다. 그리고 이에 따라 원하는 데이터를 전송한다. 여기까지는 앞선 방식과 동일하다. 다만, 이 이후로는 I/O에 CPU가 개입하지 않는다. 그러다보니 CPU는 I/O가 이뤄지는 동안 다른 작업을 수행할 수 있게 된다(execute tasks concurrenctly).
그림으로 보면 다음과 같다.

CPU는 I/O initiation을 Disk Controller에게 알린다. 이에 따라 Disk가 응답을 CPU에게 보내준다. 이어서 CPU의 요청에 따라 데이터를 메모리에 올리게 된다. 그렇다면 이제 CPU가 메모리 상에 모든 데이터가 올라왔다는 것을 알아야하지만, 해당 요청은 CPU의 개입이 더이상 이뤄지지 않았기 때문에 CPU는 이를 알 방법이 없다. 이를 해결하는 방법이 바로 Interrupt의 존재이다. Disk는 모든 데이터를 메모리에 다 올리게 되면, CPU에게 Interrupt라는 매커니즘을 통해 신호를 주게 된다. CPU는 이를 인지하고 아까 전에 Initiation으로 요청하였던 I/O 작업이 완료되었음을 확인할 수 있게 된다. 교수님께서는 해당 과정에 대해서 고등학생 과외를 하는 예시를 들어주셨는데, 과외 선생님이 문제를 20번 까지 풀라고 학생에게 지시한 다음에 본인은 다른 일을 하는 경우, 학생이 문제를 다 풀고 나서 "선생님 저 다 풀었는데요"라고 Interrupt를 통해 선생님에게 알려준다고 생각하면 쉽게 이해할 수 있다. 대표적인 Interrupt로 timer interrupt가 있다.
정리하자면,
- I/O Transaction은 버스를 통해 이뤄진다.
- 이때의 버스는 주소, 데이터, 시그널 등을 나를 수 있도록 Parallel하게 연결된 와이어의 집합이다.
- 버스는 그 위치와 용도에 따라 다양하게 분화될 수 있다.
- 시스템 버스는 CPU와 I/O bridge를 연결한다. (I/O bridge는 위의 그림에서 볼 수 있듯, 일종의 하드웨어 상에서 I/O의 중간 매개자 역할을 수행한다.)
- 메모리 버스는 I/O bridge와 메모리를 연결한다.
- I/O 버스는 다양한 기기들의 컨트롤러 위에 붙어, 해당 기기들과 I/O bridge를 연결한다.
- DMA는 기기에서 Read / Write와 같은 동작을 수행하고자 할때, 이를 CPU의 개입없이 데이터를 보내는 것을 의미한다.
- 때문에 DMA로 인해 CPU는 해당 transfer의 시작을 알릴 뿐, 이후에는 계속해서 다른 일을 수행할 수 있게 된다.
알고리즘을 살펴보자면 다음과 같다.

CPU의 입장
- 기기의 드라이버가 I/O를 시작한다. I/O 드라이버에게 신호를 보낸 상태이다. -> I/O 컨트롤러의 1번으로 진입한다.
- 신호를 보낸 이후, Interrupt를 감시하도록 check를 계속 진행한다. 이 사이에는 다른 작업이 계속해서 수행된다.
- Interrrupt를 받으면, Interrupt Handler에게 이를 처리하도록 한다.
- Interrupt Handler는 데이터를 처리하고, 적합한 동작을 처리한 후 Interrupt를 리턴한다.
- CPU는 다시 Interrupt를 받기 이전의 작업을 다시 실행한다. (엄밀히 말해서, save state, return state 모두 Handler의 역할이다)
- 이후 다시 I/O가 요구되면 1로 돌아간다.
*Interrupt Handler( = interrupt Service Routine, ISR)는 인터럽트가 들어왔을 때 수행되는 특정 기계어 코드 루틴이다. 이때 루틴은 명령어의 집합으로 이해하면 되는데, 결국에는 해당 명령어들이 위치한 코드 덩어리라고 생각하면 되겠다.
I/O 컨트롤러의 입장
- 대기 상태에 있다가 Initiation 신호를 받으면, I/O를 시작한다.
- I/O를 위한 준비를 마치고, 관련 작업을 모두 수행한 이후 CPU에게 Interrupt를 보낸다. -> CPU의 3번으로 들어간다.
현대의 OS는 Interrupt Driven이다.
현대의 OS에서는 User의 요청으로부터 시작되는 Interrupt나 운영체제상에서의 커널에 의한 시스템 Interrupt, 그 외의 Trap으로 대표되는 Exception이나 System Call에 의해서만 작업을 시작한다. 하나의 Interrupt에는 Table에 의해 제공된 하나의 ISR이 존재하게 된다.
Interrupt 가 수행되는 과정을 자세히 살펴보자.
CPU는 Interrupt가 들어오면 해당 Interrupt가 어떤 역할을 수행하는지를 알아야 한다. 이를 통해 Interrupt Vector Table을 조사하여 해당 Interrupt가 어떤 Handler와 연결되어 있는지를 알 수 있게 된다.
2장에서 더 자세히 배우겠지만, Interrupt Vector는 source는 두가지 컬럼을 반드시 갖는다. 하나는 source이고 또 다른 하나는 ISR 주소이다. source에는 이것이 어떤 Interrupt인지, ISA 주소에는 즉 해당하는 Interrupt Handler의 주소가 들어있어 Interrupt가 들어오면 적절한 서비스 루틴 코드가 실행될 수 있도록 안내한다.


결국 Interrupt Vector를 살펴봄으로써 해당 Interrupt가 위치한 source의 칼럼을 뒤진 후에, 해당 source와 같은 로우에 위치한 ISR routine의 주소를 찾게 되는 것이다.

대표적인 Interrupt로 Timer Interrupt를 들 수 있다. CPU의 수많은 동작에서 Timer Interrupt는 중요한 역할을 한다. 바로 중간 중간 딜레이를 주는 역할이다. Timer Interrupt가 들어오면 CPU는 하던 일을 멈추고 작업의 주소를 저장해놓고, Interrupt Vector를 참조하여 source가 Time Interrupt인 ISR 주소를 찾게 된다. 이를 따라서 ISR이 실행되고 Interrupt에 해당하는 코드가 실행된다. 코드가 수행된 이후 CPU는 다시 중지했던 작업의 주소를 참조하여 기존 작업을 이어서 수행한다.

해당 그림에서의 IRQ는 Interrupt ReQuest 를 의미한다.
이어서 PIC는 Programmable Interrupt Controller의 약자로 인터럽트 처리에 관련된 세부 기능을 프로그래밍할 수 있는 컨트롤러이다.
PIC에 Interrupt가 수신되면, 이를 CPU의 INTR 핀에 보낸다. PIC는 CPU가 받았다는 신호를 주는 기다리게 되고, CPU 프로세서는 해당 Interrupt를 받았다는 것을 PIC 핀에게 알린다. 이후는 앞서 여러번 언급했다 싶이, Interrupt Vector Table과 ISR(Handler Routine)을 거쳐 해당 Interrupt가 수행되게 된다.
여담으로 앞서 언급했던 주소를 왔다 갔다하는 것은 Program counter register라는 것을 통해 가능하다. 프로그램 카운터는 현재 실행 중인 명령의 주소(위치)를 포함하는 컴퓨터 프로세서의 레지스터이고, 컴퓨터 구조 MIPS의 J-type과 같은 명령어를 통해 해당 주소로 이동한다.
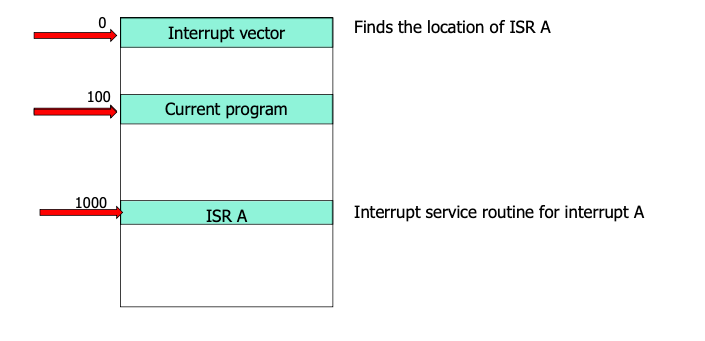
먼저, CPU가 100이라는 주소에서 프로그램을 실행하고 있다고 하자. 그러다가 Interrupt가 딱 들어온다. CPU 입장에서는 Interrupt Vector를 참고하여 해당하는 ISR 주소가 어디있는지를 찾아야 한다. 이는 0의 주소에 위치한다. 0에 가서 ISA 주소를 찾고 봤더니 해당하는 ISA 주소는 1000에 위치한다. 그래서 1000으로 Jump하게 되는데, 바로 이때 주소의 Jump는 Program counter register를 통해 가능하게 된다.
Interrupt vs Trap
Interrupt와 가장 혼동되는 개념이 Trap이다.
앞에서 봤던 Interrupt의 개념을 잘 기억하자. 한편, 이러한 신호를 소프트웨어에서도 줄 수가 있다. 이를 바로 Trap이라고 한다. 예를 들어보자. C 프로그래밍을 하다가 Bus Error, Seg fault와 같은 문제가 발생하면 CPU에게 이를 알려야한다. 이를 Exception이라고 한다. 또한 OS에서 하드웨어 자원에 접근하고자 하는 경우, 혹은 Application에서 하드웨어 자원이 요구되어 이를 접근하고자 하는 경우, System Call이 발생한다. 이와 같은 경우를 Trap이라고 명명한다.
Trap과 Interrupt를 더 명확히 구분하려면 Asynchronous와 synchronous의 개념을 이해해야 한다. 앞서 CPU가 계속해서 Interrupt가 들어오는지를 check하는 것을 떠올려보자. CPU 입장에서는 언제 Interrupt가 들어오는지를 모르기 때문에 계속해서 체크를 할 수 밖에 없다. 이것이 Asynchronous이다. 반대로 Trap의 synchronous는 다르다. Trap의 경우 프로그램이 시작된 이후 발생한다. 때문에 특정 명령을 실행한 결과로써 나오는 결과물이다. Trap의 대표적인 예시인 System Call은 2장에서 더 자세히 다루게 된다.
다음으로는 Storage structure에 대한 내용이다.
여기에서 중요하게 다루는 메모리는 역시 Main memory이다. 그 외에도 HDD, SSD와 같은 Secondary Storage가 등장한다. 그 외에도 우리가 Teriary Storage라는 대개 백업을 위한 Storage도 존재한다.

위 그림은는 Storage의 계층도를 나타낸다. 위로 올라갈 수록 CPU에 가까우서 Speed가 빨라진다. 그러나 Cost가 높아 많은 용량을 확보할 수가 없다. 때문에 모든 데이터를 레지스터와 캐시에 저장할 수 없기에 우리는 HDD나 SSD와 같은 magnetic disk, 즉 보조 기억장치를 활용하게 된다. optical disk와 magnetic tapes들의 경우 최근들어 보기가 매우 귀해졌다고 하며, 그런 것이 있구나 정도만 하고 넘어가자. 추가적으로 cache는 SRAM이라고도 부르며, main memory는 DRAM이라고도 부른다.
결국 Cost와 Performance간의 Trade-Off가 이뤄진다는 점을 이해하고 넘어가면 되겠다. 이때의 속도를 좌우하는 핵심으로써 Caching Decision(대표적으로 LRU 캐싱)이 등장하게 되는데, 이는 추후 다시 등장할 때 자세히 다루도록 하자.
1.3 Computer-System Architecture
앞선 그림 1-4에서는 하나의 CPU가 등장하여 다양한 부품 혹은 장비들과 상호작용을 이룬다. 그러나 현실의 실제 컴퓨터는 조금 다르다. CPU는 꼭 한 개일 필요는 없으며, 그 이상일 수 있다. 이러한 구조를 Multi-processing 구조라고 한다. Multi-processing의 경우 여러개의 프로세서가 서로 협력하여 작업을 수행한다. 해당 구조는 다음과 같은 장점을 갖는다.
- Increased Throughput
- Economy of scale
- Increased reliability
1. Increased Throughput의 경우에는 작업을 여러명이서 수행한다고 생각하면 당연하다. 이후 등장하는 개념인 쓰레드와 달리, 프로세서의 증가는 작업을 할 수 있는 실제 자원량의 증가를 의미한다. 다만 우리는 N개의 CPU를 추가하며 N배의 성능 향상은 실질적으로 어렵다(서로 간의 커뮤니케이션에도 오버헤드가 발생한다).
2. Economy of scale도 발생한다. 만약 CPU 내의 여러 개의 프로세스가 Shared Memory를 가지고 이를 활용할 경우, 각 데이터를 해당하는 프로세서에게 별도의 할당없이 하나의 공간에 데이터를 모두 저장한 후 이를 공유한다면, 비용이 절약되게 된다.
CPU
3.Increased reliability, CPU가 여러 개라는 점은 곧 fault tolerance가 높다는 것을 의미한다. 하나의 CPU가 실패하더라도 다른 CPU가 이를 대신 처리할 수 있기 때문이다.
Multi-processing 구조의 분류
Multi-processor는 다음과 같이 총 두 종류로 나눠진다.
- Asymmetric multiprocessing(ASMP)
- Symmetric multiprocessing(SMP)
분류의 기준은 CPU들간의 상하 관계가 존재하는지의 여부이다. 먼저 ASMP의 경우, processor(CPU)들간의 상하 관계가 존재한다. 하나의 Master processor가 나머지 Slave relationship을 조율하게 되는데, 이때 master processor는 오직 slave processor의 조율자로서 역할을 수행하며, 나머지 slave processor가 실제 작업을 수행한다.
반대로, SMP의 경우 master-slave 관계가 존재하지 않는다. 모든 processor가 slave로써 작업을 수행한다고 보면 되겠다.

메모리 접근 방식에도 두 가지가 있다.
- UMA, 메모리 엑세스 타입이 언제나 일정하다
- NUMA, 메모리 엑세스 타입이 CPU마다 다를 수 있다.
UMA는 Uniform memory access의 줄임말로, 언제나 일정한 메모리 엑세스 타입을 보장하는 메모리 접근 방식을 의미한다. NUMA는 Non-Uniform memory access의 줄임말로, 메모리 엑세스 타입이 CPU마다 상이할 수 있는, 즉 메모리의 일정한 접근이 보장되지 않는 형태의 접근 방식이다. 개인적으로 NUMA의 경우 Private storage 접근이 Common storage보다 접근이 빠를 수 밖에 없다고 생각하니 잘 와닿았다 .
Multi-core vs Multi-processing
앞서 Multi-processing를 살펴보았다. 그렇다면 Multi-processing와 Multi-core의 차이는 무엇일까?
간단하다. 단일 컴퓨터의 프로세서가 여러 개 존재하면 Multi-processing이고, 여러 개의 코어가 하나의 프로세서에 있다면 Multi-core이다.
현재 우리가 주위에서 보는 컴퓨터는 주로 Multi-core 구조를 표방한다. 왜그럴까? 정답은 Multi-process보다 Multi-core 구조가 발열과 전력 소모 측면에서 훨씬 우월하기 때문이다. single core 구조에서 10GHz를 커버하면 성능을 확 올릴 수 있다. 그럼에도 4개의 코어를 사용하는 코어에서 각각 2.5GHz를 커버한다면 훨씬 발열과 전력 문제에서 더욱 효과적이게 된다.
1.4 Operating-System Operation

Multiprogramming
관련하여 Multiprogramming이라는 개념도 등장한다. 이후 5장에서 다시 배우겠지만, CPU는 하나의 단일 작업을 수행하는 대신 여러 개의 작업을 스케쥴링하며 진행한다. 스케쥴링을 통해 CPU는 쉬지 않고 작업을 계속 연속적으로 수행할 수 있게 된다. 특정 작업에서 딜레이가 발생하면 OS는 바로 다른 작업을 수행하도록 CPU를 바쁘게 유지한다.이때 Multiprogramming은 단일 프로세서가 단일 프로세스를 처리하는 동안 다른 프로세스에도 접근하도록 하는 것을 의미한다. 즉, 작업 중인 특정 프로세스의 완료를 기다리는 것 대신, 그 동안 다른 프로세스를 처리할 수 있도록 해주는 것이다. 이는 이후에 배우게 되는 Context-switch에 기반한 개념임을 가볍게 기억하고 넘어가자.
Swapping
swapping이라는 개념도 등장한다.메모리의 경우에는 CPU 자원이 한정되어 있는 상황이기에, 효과적인 메모리 자원 할당이 요구된다. '어떤 Job을 메모리에 올려야하나', 'CPU 자원을 어디에 쓰는 것이 효율적인가?' 등 고려해야할 상황이 많다.
기존 메모리에 있는 것을 걷어내고 새로운 것을 메모리에 올릴 수도 있다. 이를 swapping이라고 한다(메모리에 올리는 것을 swap-in, 걷어내는 것을 swap-out이라고 한다). swap-in, swap out이 연속적으로 이뤄지면서 마치 사용자들은 계속해서 메모리에 Job이 계속 위치한 것처럼 느끼게 된다.
Multitasking
여기서 또 헷갈리는 용어가 등장한다. 바로 Multitasking이다. 직전의 Multi-programming이 단일 기기에서 여러 프로그램을 돌리는 것이였다면, Multitasking은 여러 CPU를 사용하는 동일한 컴퓨터에서 한 사용자가 여러 프로세스를 동시에 실행하는 것을 의미한다. 즉, 스케쥴링을 통해 다수의 작업을 번갈아가면서 수행한다. 다수의 작업을 스케쥴링을 통해 번갈아가며 수행하기 때문에 유저는 다양한 작업을 동시에 수행하는 것과 같은 느낌을 받는다. 때문에 Multitaking은 Multiprogramming을 구현하는 방식의 하나라고 이해할 수 있겠다. 이 외에도 Real-time(RTMOS), Time sharing 방식등을 통해 Multiprogramming을 구현할 수 있다.

Virtual Memory 기법

Virtual Memory는 메모리를 관리하는 방법의 하나로, 각 프로그램에 실제 메모리 주소가 아닌 가상의 메모리 주소를 주는 방식을 말한다. Virtual Memory는 실제 메모리 공간이라기보단 지금 DISK에서 참조하고 있는 주소를 의미하게 된다. 반대로 Physical Memory의 경우 실제 Memory에 쓰여있는 값을 의미한다는 점에서 두 개념의 차이가 도드라지는 것을 볼 수 있다.
Virtual Memory의 동작을 이해하기 위해서는 Swapping을 이해해야 한다. 앞서 잠깐 언급하였듯이 CPU에서는 Job Scheduling을 통해 수행하는 작업을 최대한 효율적으로 처리하기 위해 다양한 작업을 계속해서 Context-Switch하게 된다. 이때, 이 과정이 매우 빠르게 일어난다면, 유저는 마치 동시에 여러개의 작업을 수행하는 것과 같은 느낌을 받게 된다. 메모리가 사용되는 과정에서도 마찬가지이다. 우리의 메모리 자원은 한정적이다. 때문에 이를 효과적으로 수행하기 위해서 Swapping을 수행한다. swapping in이 되면 메모리에 올라온다. 다만, 메모리의 한계로 인해 모든 작업을 한 번에 swapping in 할 수는 없다. 대신 swapping in, swapping out을 매우 빠르게 수행하며 마치 여러 개의 작업을 동시에 메모리에 Load하는 것과 같은 효과를 줄 수 있다. 이때 Virtual Memory Address에서는 Swapping에 곧바로 참여할 수 있도록 Disk에 특정 부분을 가리키고 있는데 이를 Virtual Memory 기법이라고 한다.
Dual Mode operation
Dual이라는 단어에서 유추할 수 있듯이, 해당 용어는 OS가 지원하는 두 가지의 모드에 대한 내용이다. OS에서는 User mode와 Kernel mode라는 두 가지 모드를 지원한다. 구분하는 근거는 특정 시점을 딱 집었을 때, 실행하고 있는 코드의 종류를 기준으로 한다. 예를 들어, 어떤 특정 시점을 딱 잡았는데 해당 시점에서 유저의 애플리케이션 코드를 실행한다면, 해당 시점을 user mode로 판단한다. 반대로, 어떤 특정 시점을 딱 잡았는데 해당 시점이 kernel code를 실행한다면 해당 시점을 kernel mode로 판단한다. Kernel mode는 System Call이 발생하거나, Interrupt가 발생하는 경우에 진입하게 된다. 이 외에도 시스템이 부팅될 때 Kernel mode로 실행이 되어 이후 user mode로 전환된다는 점도 알아두면 좋을 것 같다.

위의 그림은 System Call이 발생한 경우, user mode에서 kernel mode로 전환되는 과정을 보여준다. 먼저, user 프로그램이 실행됨에 따라 user process가 실행된다. 그러다가 하드웨어 자원이 필요하여 system call을 하게 되는 경우, trap이 발생하여 mode bit를 1 에서 0으로 바꾸게 된다. 이후 system call에서 파생된 작업이 모두 종료가 되면 mode bit를 다시 1로 바꾸며 user mode에 복귀하게 된다.
이렇게 모드를 분리하는 이유는 간단하다. OS를 보호하기 위함이다.
OS의 특정 작업들은 기기에 치명적인 영향을 줄 수 있다. 정말로 위험한 작업들은 유저가 아닌 커널만 수행할 수 있도록 하여, OS를 잠재적인 위협으로부터 보호한다.
kernel mode에서 수행되는 대표적인 작업(Privilleged Instructions)은 다음과 같다.
- H/W access
- I/O access
- mode transition
때문에 user mode에서 Privilleged Instructions을 수행하려고 하는 경우, 접근이 차단되게 된다.
책에 잠깐 언급되는 내용으로 Intel processor의 protection rings라는 개념이 등장한다. 이론은 간단하다. 두 개의 모드로 관리되는 것을 넘어 총 4 단계로 모드를 구분하여 앞의 Dual-Mode를 더욱 세분화한다. virtual machine manager(VMM)라는 개념도 등장한다. 별건 아닌데, VMM의 경우 가상 머신을 만들고 관리할 수 있도록 CPU의 State를 변경할 수 있기에 user mode보다는 권한이 많은, kernel mode보다는 권한이 적은 것으로 책에 소개된다.
여기까지 1장의 내용을 마무리하고자 한다. 뒤에 더 많은 내용이 나오지만, 원론적인 내용이 많을 뿐 뒤에서 자세하게 다루는 내용의 개요이기에 너무 자세히 들어가지는 않고자 한다. 2장에서는 System Call에 대한 내용이 등장한다. 많은 부분을 위에서 다뤘지만, 2장에서는 이를 더 자세하게 파고 들어가보려고 한다.
'CS' 카테고리의 다른 글
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
|---|---|
| Cache Memory 소개 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
| [리눅스 프로그래밍] Kernel 개요 (1) | 2022.09.23 |
| [리눅스 프로그래밍] 리눅스 계보 (2) | 2022.09.23 |
아마 이번 글은 다소 재미없는 역사 시간이 될 거 같다. 학교에서 리눅스 프로그래밍을 배우면 가장 먼저 배우는 내용이기도 하고, 리눅스를 배운다면 적어도 UNIX와 Linux가 어떻게 다른지 한번쯤은 이해하고 넘어가자는 의미에서 글을 작성하게 되었다.
Unix 이전
1955
John McCarthy라는 할아버지가 시분할(time-sharing)에 대한 개념을 제시한다. time-sharing은 이후 호환 시분할 시스템(Compatible Time-Sharing System, CTSS)의 발전에 영향을 미치게 된다.
John MacCarthy라는 할아버지가 알고보니 상당히 대단한 사람인데, 앞선 시분할 개념을 소개한것 이외에도 무려 인공지능이라는 용어를 처음 만든 할아버지라고 한다. 최근 비즈니스 관련해서 인공지능이라는 말을 할 수 없으면 대화가 진행되지 않을 정도인데, 이를 처음 명명한 사람이라는 상당히 대단한 할아버지다. 또 언젠가 C 이전의 프로그래밍 언어라고 얼핏 들었던 LISP도 이 할아버지가 만들었다고 한다.
1962
MIT의 Computation Center에서 CTSS라는 최초의 시분할 운영체제(time-sharing operating system)를 만들어 낸다. 이후 CTSS는 MULTICS라는 발명품에 기여하게 된다.
MULTICS와 UNIX의 등장
1969 - 1971
GE, MIT, Bell Labs의 연구자들이 MULTICS라는 OS를 출시하게 된다. MULTICS는 GE-645라는 메인프레임을 위해 만들어진 OS였다. 비록 상업적으로는 성공하지 못했으나. 이후 UNIX의 탄생에 중요한 역할을 하게 된다.

이후 Ken Thompson이라는 할아버지가 GE-645 메인프레임을 계속해서 발전시켜, 여기서 실행할 수 있는 Space Travel이라는 게임을 만들게 된다.
그러나 GE 머신으로는 너무 느리고 비싸다는 점을 느끼고 벨 연구소에서 그나마 저렴한 PDP-7이라는 컴퓨터를 찾게된다.
이 PDP-7이라는 컴퓨터에서 톰슨이 리더로 Dennis Ritchie(!), Rudd Canaday과 함께 [1]계층적 파일 시스템(/ 로부터 파생되는 그 파일 시스템, 지금은 당연한 이것이 그 전에는 그렇지 않았다), [2]프로세스와 디바이스를 파일로 관리, [3]CLI(Command-line Interpreter), [4]그 외의 소규모의 유틸리티 프로그램을 모두 가진 UNIX(Uniplexed Information and Computing Service)라는 프로젝트를 시작한다. 언어는 어셈블리어. 이때의 UNIX라는 이름은 이름에서 유추하였듯 앞의 MULTICS의 언어유희이다.

이후 Brian Kernighan(!)이 추가적으로 합류하였고, 이후 1970년에 공식적으로 UNIX라는 이름을 달고 PDP-11/20이라는 머신에서 돌아가게 된다.
이후 Bell Labs의 모회사인 AT&T가 대학과 사기업들에게 UNIX를 공급하였고, 심지어 미국 정부에게도 라이센스와 함께 UNIX를 공급하게 된다.

UNIX 등장 직후의 양상
1973
앞서 UNIX를 개발했던 Ken Thompson이라는 할아버지가 B라는 매우 간단한 언어를 만든다. 바로 PDP-7에서 사용하려고 만들었는데, 문제 없이 동작은 하지만 몇몇 문제가 있었다.
이후 UNIX를 함께 만들었던 Dennis Ritchie이 함께 최초의 C compiler를 만들었고, 이를 가지고서 Ken Thompson과 Dennis Ritchie가 문제가 있던 부분을 보완하여 UNIX 커널을 다시 짜게 된다.

C로 다시 커널을 만들고 나니, 어셈블리어보다 다른 머신에 호환되는 환경으로 수정하는 작업이 비교적 쉬웠고, 이를 가지고 다른 개발자들이 다양한 베리에이션을 만들게 된다.
1974
Communications of the ACM이라는 저널에 UNIX를 발표하게 된다.
1977
UNIX가 분리된다. UC-Berkley의 Bill Joy(또 다른 전설의 등장!)가 본인들만의 버전을 발표해버리고, Berkely Software Distribution이라는 의미에서 이름을 BSD로 짓는다. 이때 되게 다양한 유틸리티들을 만들었는데, 우리가 자주 사용하는 vi, shell 같은 프로그램들도 이때 만들어졌다.

1980 - 1981
드디어 마이크로소프트가 등장한다. 마이크로소프트가 OS 비즈니스에 참여하여 UNIX를 본인들만의 버전으로 바꿔 Xenix라고 명명한다. 예전에 실리콘 벨리의 신화라는 영화에서 관련된 이야기를 접할 수 있었는데, 상당히 흥미로웠다. 이후 마이크로소프트는 IBM과 계약을 체결하고 IBM의 새로운 제품군을 위한 OS 개발 계약을 체결한다.

1982
AT&T가 UNIX System III라는 버전(SVR1, Sysyem V release 1이라고도 불린다)의 최초의 상업적인 UNIX OS를 상표에 등록한다. BSD를 만들었던 Bill Joy는 다른 동료들과 함께 Java를 만든 Sun Microsystems를 창립하고 SunOS를 만들게 된다. 이떄 SunOS라는 이름은 현재는 Solaris OS라고 명명되어 불리고 있다.
1983
4.2BSD에서 최초의 TCP/IP 소켓 API를 출시한다.
한편, 미국 법무부에서는 반독점법을 이유로 AT&T에 소송을 걸었고, 정부에 의해 찢어지게 된다. 이 과정에서 Bell 연구소 또한 상당 부분 규모가 축소된다. 이와 연관해서 AT&T 측에서는 최대한 빨리 UNIX System V를 내고자 했다고 한다.
Thompson과 Ritchie는 운영 체제 이론에 대한 개발 및 특허, UNIX의 개발의 공로를 인정받아 튜링상을 받게된다.
1984
정보기술 분야에 open system 표준을 식별, 장려하기 위한 목적으로 X/Open 컨소시엄이 설립된다.
MIMIX의 등장과 유닉스 전쟁
1985
Andrew Tanenbauum이라는 네덜란드의 교수가 Unlix와 비슷한(Unix는 아니지만!) MINIX라는 OS를 만들게 된다. 이때, MINIX는 UNIX의 주요한 특징들을 전부 담고 있어서, UNIX 코드에서 비롯된게 아닌가 하는 오해를 할 수 있는데, UNIX like이지 UNIX는 아니다. UNIX를 표방하여, 본인이 소스 코드를 짰다고 한다.
Linx의 부모 격인 MIMIX였다.
1987
AT&T와 Sun Microsystems는 X/Open과는 독립적으로 Xenix, BSD, SunOS, 기존 SysV(System V)의 특징들을 모두 합친 SVR4(System V Release 4)의 개발을 시작한다.
1988
오픈 소프트웨어 재단(Open Software Foundation)이 결성되고, Mach 커널과 BSD 운영체제를 기반으로 본인들이 변형한 UNIX를 출시한다. OSF는 UNIX의 표준을 만들자는 목적을 표방했는데, 이는 기존 UNIX 진영 쪽에서 꽤나 부담을 느꼈을 것이다.
이에 대항하여 AT&T와 썬마이크로시스템 측에서는 UNIX International이라는 협회를 설립하여 본인들이 유닉스 운영 체제의 표준을 만들겠다고 해버린다.
이를 유닉스 전쟁이라고도 한다는데, 싸움에 끼고 싶지 않았던 X/Open은 중립적인 태도를 취한다.
(유닉스 전쟁에 대한 기사 읽어보면 꽤나 재밌다.)
결론적으로 두 개의 표준이 생겨버린건데, 그러다 갑자기 평화가 찾아오고 IEEE의 POSIX(Portable Operating System Interface)와 X/Open 측의 Single Unix Specification이 양립하게 되었다고 한다.
Linux의 등장
1991
Linus Torvald의 등장. 그가 오픈 소스로써 Linux를 발표한다. 다들 알겠지만 본인 이름에 UNIX를 붙여 언어유희를 이어나간다. Linx의 탄생에는 MIMIX라는 부모가 없었다면 불가능했을지도 모른다. 학부 시절에 테넨바움의 책인 [운영체제-설계와 이론 및 MINIX에 의한 실제 장치]를 읽고 MIMIX를 가지고 놀던 Linus가 개인 컴퓨터에서도 동작하는 UNIX OS의 필요성을 느끼고 MIMIX를 기반으로 Linux를 개발했다고 한다. 여담으로 테넨바움 교수와 리누스 간의 Linux를 둘러싼 OS 논쟁도 전체적인 맥락을 알고보면 더욱 흥미로움을 느낄 수 있었다.
Linux 등장 이후의 양상
1993
AT&T가 Novell 사에 약 $210 million(2,952억 6,000만 원, 220923일 기준)의 가격으로 UNIX를 매각한다. 이후 Novell은 UNIX® 상표 및 인증 권한을 X/Open 측에 양도하게 되고, 본격적으로 Windows NT와의 경쟁에 들어가지만, 이미 Window가 시장에서 점차 높은 점유율을 보이기 시작했다.
1995
Novell이 UNIX의 전반적인 비즈니스를 모두 Santa Crus Operation(SCO)에 매각한다.
1996
X/Open 과 새로운 OSF(번역을 그대로 가져왔다)가 Open Group으로 합쳐진다.
1997
Open Group이 Single UNIX Specification(POSIX와 함께 양립했던 그 친구) Version 2를 발표한다.
1998
Open Group과 IEEE가 함께 Austin Group을 구성하고, POSIX와 Single UNIX Specification, 둘을 합치는 프로젝트를 시작한다.
2000
SCO가 UNIX 비즈니스 전체를 Caldera Systems에 매각한다. (팔리고 팔리는 UNIX...)
2001
Austin Group 이 Single UNIX Specification Version3를 출시한다.
당시 AIX, HP/UX, Mac OS X, SCO, Solaris, Tru64 UNIX, z/OS 등의 다양한 OS가 이를 따르게 된다.
2008
2008년 12월 Austin Group이 POSIX:2008(혹은 SUSv4)이라는 이름의 새로운 버전의 표준을 내게된다.
Unix-like system의 계보

열심히 읽었다면 그림을 보고 반가운 이름들을 만날 수 있을 것이다. Unix, BSD, SunOS, Xenix, System 3, System V, Solaris, Mimix, Linux까지 MacOS로 이 문서를 작성하기까지 이렇게나 많은 유닉스 기반 운영체제가 존재했었다!
참고로 MacOS는 앞서 살펴보았듯(2001), SUSv3 표준을 따르는 Unix 운영체제이다. 그러니까 MacOS는 Linux는 말할 수 없다. 유사하다 정도의 답이 가장 둘의 관계를 잘 표현할 수 있겠다.
Unix Standard의 역사
| Name | Standard | Comments |
|---|---|---|
| POSIX 1988 | IEEE Std 1003.1-1988(1988L) | First Standard |
| POSIX 1990 | IEEE Std 1003.1-1990/ISO 9945-1:1990 | Minor update of POSIX 1988 |
| POSIX 1993 | IEEE Std 1003.1b-1993/ISO (199309L) | POSIX 1990 + real time |
| POSIX 1996 | IEEE Std 1003.1-1996/ISO 9945-1:1996 (199506L) | POSIX 1993 + threads + fixes to real-time |
| XPG 3 | X/Open Portability Guide | First widely distributed X/Open guide |
| SUSV1 | Single UNIX Specification, Version 1 | POSIX 1990 + BSD + System V |
| SUSV2 | Single UNIX Specification, Version 2 | SUS1 update |
| SUSV3 | Single UNIX Specification, Version 3 (200112L) | SUS2 update |
| SUSV4 | Single UNIX Specification, Version 4 | SUS3 update |
SUS 와 POSIX 간의 차이와 최종적으로 POSIX와 SUS가 합쳐졌다는 점을 이해한다면 잘 이해했다고 할 수 있을 것 같다.
'CS' 카테고리의 다른 글
| Cache Hit, Cache Miss 개념, Cache Miss의 종류 (0) | 2022.11.28 |
|---|---|
| Cache Memory 소개 (0) | 2022.11.28 |
| Ch2. Operating-System Structures (0) | 2022.11.15 |
| [리눅스 프로그래밍] Kernel 개요 (1) | 2022.09.23 |
| [OS] Introduction (1) | 2022.09.23 |
SageMaker Data Wrangler flow

이 중에서 New data flow 선택
로딩이 끝나고 나면, 기본값으로 Source와 함께 Transform이라는 항목이 보인다.

이때 활용하는 서비스는 Sagemaker 내의 Data Wrangler인데, Data Wrangler의 경우 미니멈으로 vCPU를 16개 RAM을 64GB나 사용하기 때문에 비용 정보에 신속하게 대응할 수 있어야 하고, 혹시나 켜놓고 놔두는 불상사가 발생하지 않도록 하자.
AWS에서 제공하는 Sample 소스를 추가하였다. 데이터는 타이타닉의 탑승자에 대한 정보이다.
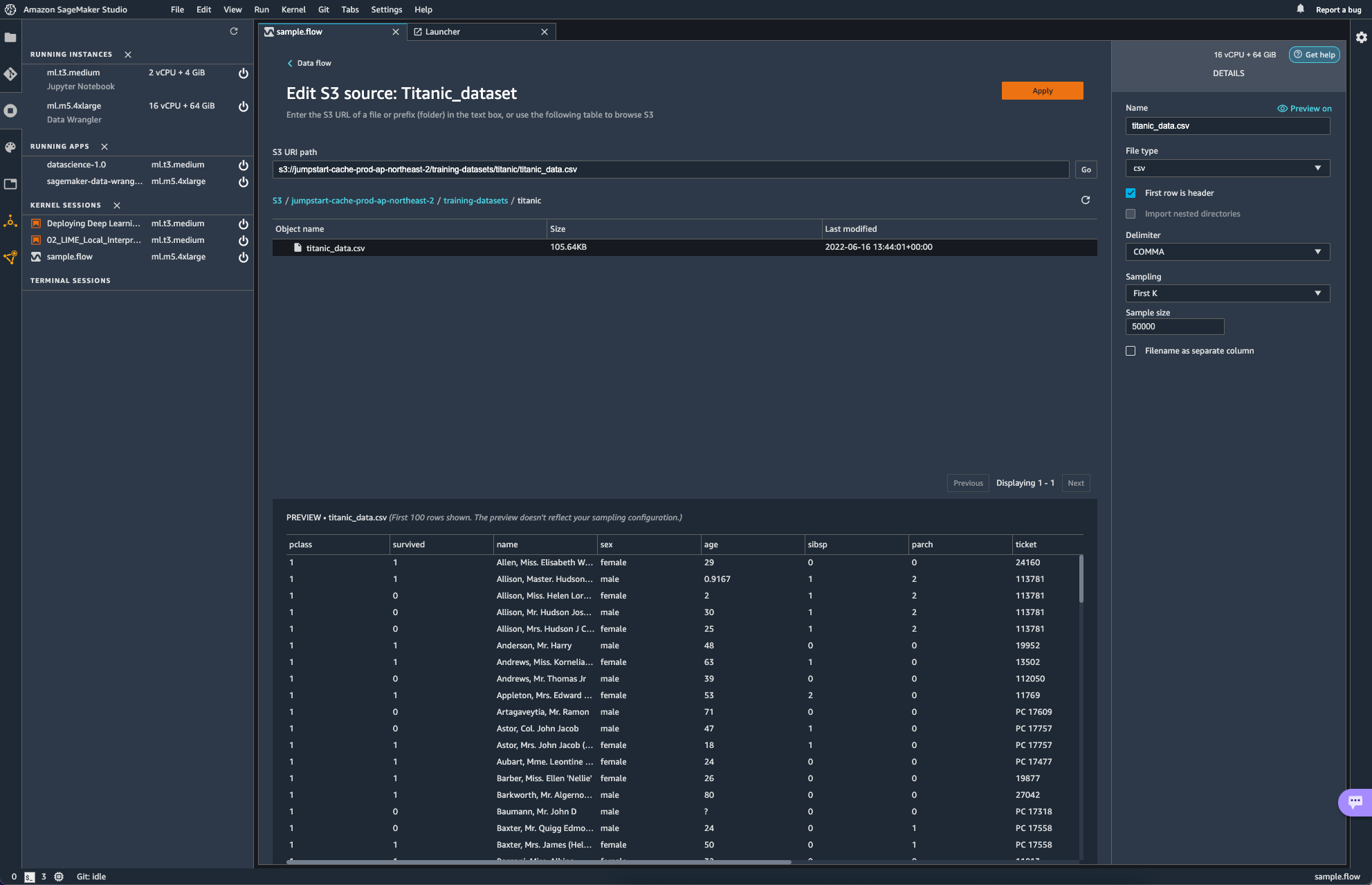
source를 edit하게 되면, 다음과 같은 화면이 보인다.
S3 URL을 통해 source를 지정하는 형식이다. Data Wrangler에서 유저는 파일 형식과, delimiter, 샘플링 방식과 크기를 지정해주게 된다.
이 외에도 쿼리 질의를 통해 데이터를 가져올 수 있는 Athena로부터도 데이터를 가져올 수 있다고 한다. snowflake로부터도 가져올 수 있다고 하는데, snowflake 사의 서비스를 아직 써본 경험이 없어 일단은 넘어가고자 한다.
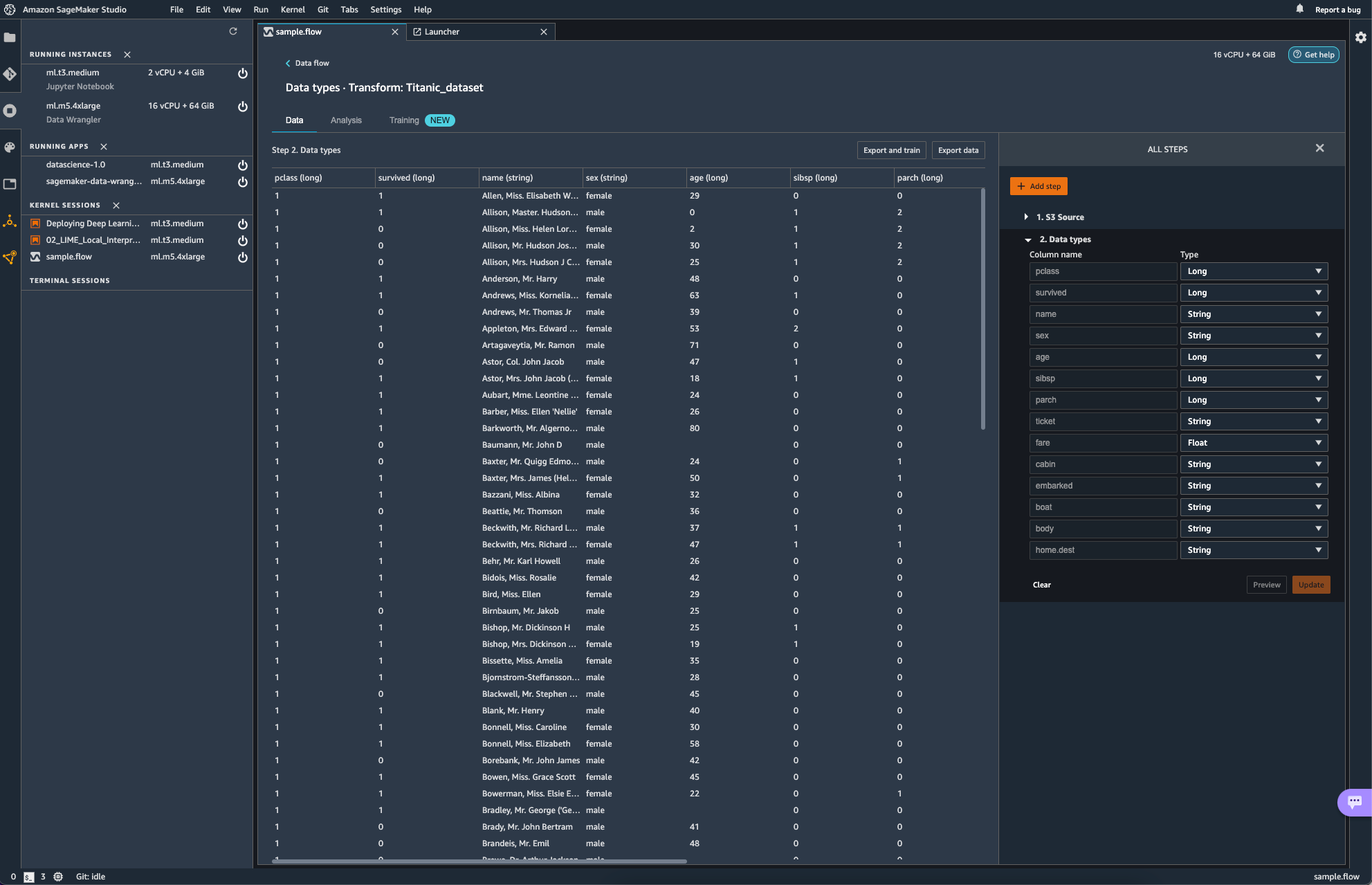
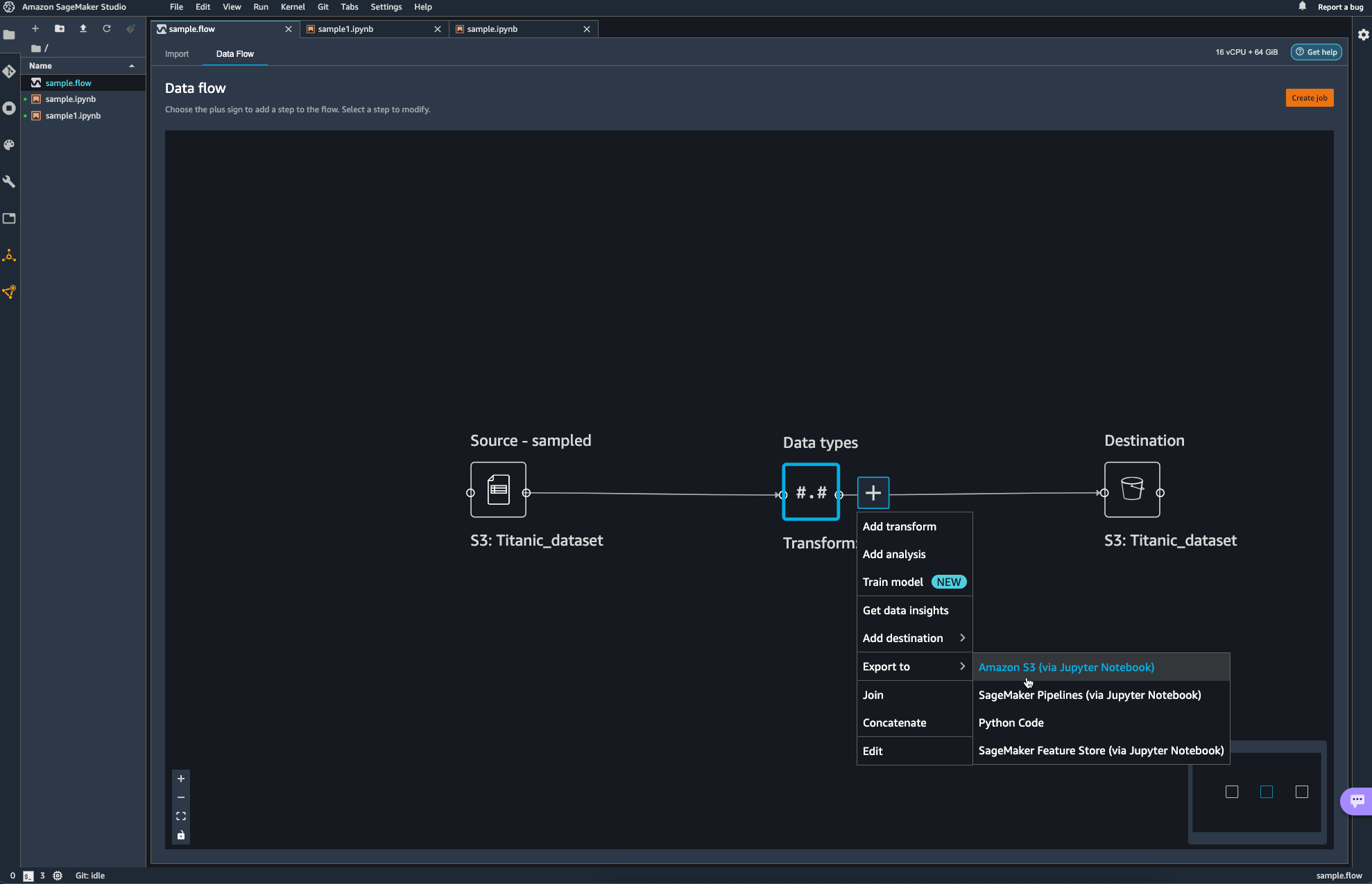
이미지 속에서는 작업은 Glue Studio에서 수행할 수 있는 ApplyMapping과 같은 역할을 수행한다. 일단은 신경 쓸 필요도 없이 자동으로 Mapping 되었다.
add step을 선택해보면 다양한 transform 작업들이 보인다. 해당하는 작업들이
transform에서는 glue studio에서 transform으로 적용할 수 있었던 항목들이 그대로 보여지는 듯 하다.
다만 이제 Glue에서 transform 했던 작업들의 성격이 ETL 측면에서의 transform의 느낌이였다면, sagemaker에서는 분석 직전에 데이터를 preprocessing하는 측면이라고 생각하면 되지 싶다.
Analysis를 통해 간단한 분석도 가능하다.
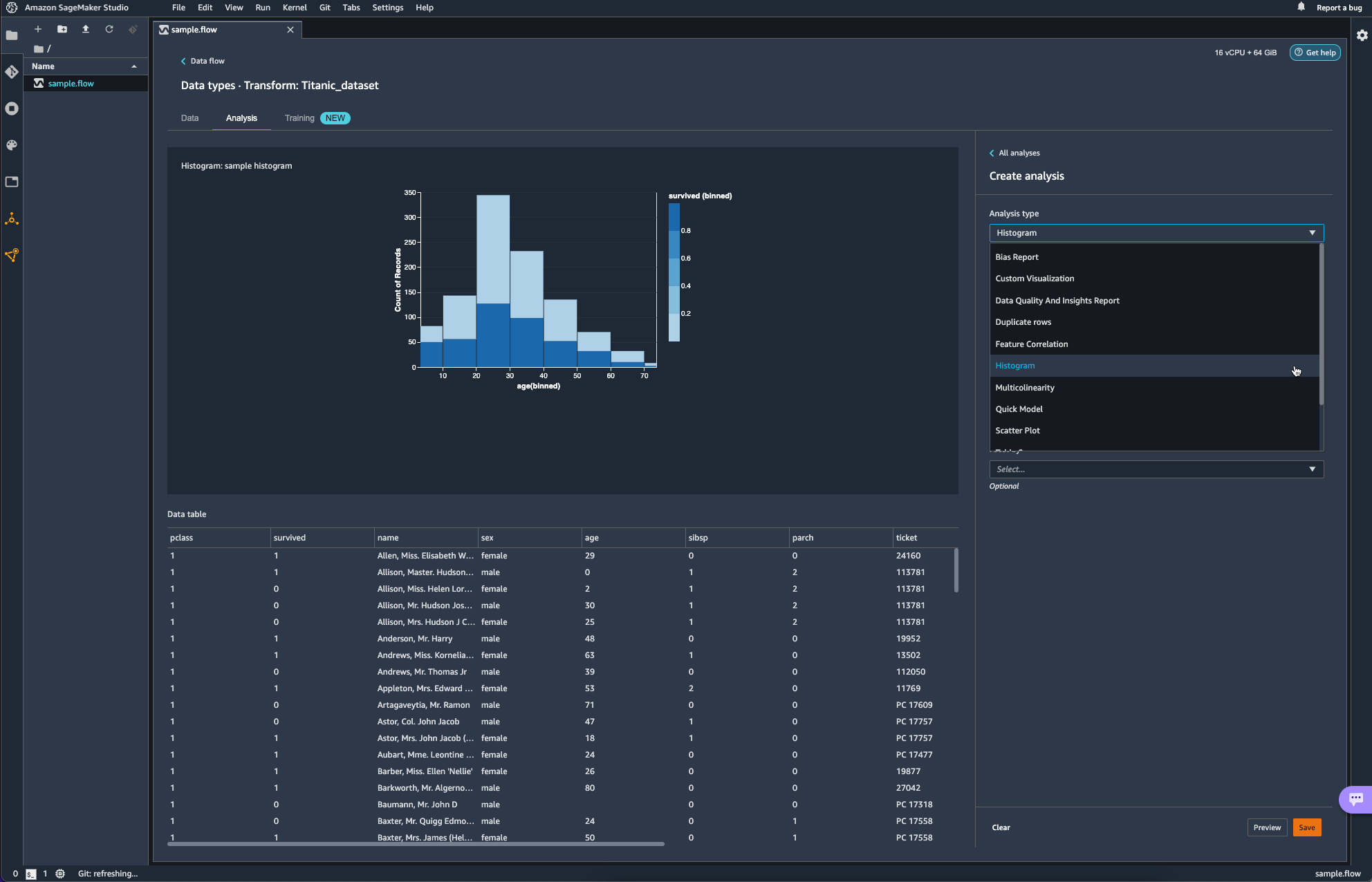
아래 항목은 Data Wrangler를 활용해 bias를 분석하는 작업이다. 타이타닉의 생존 여부(survived)를 target column으로 age에 대한 bias를 분석해보았다.
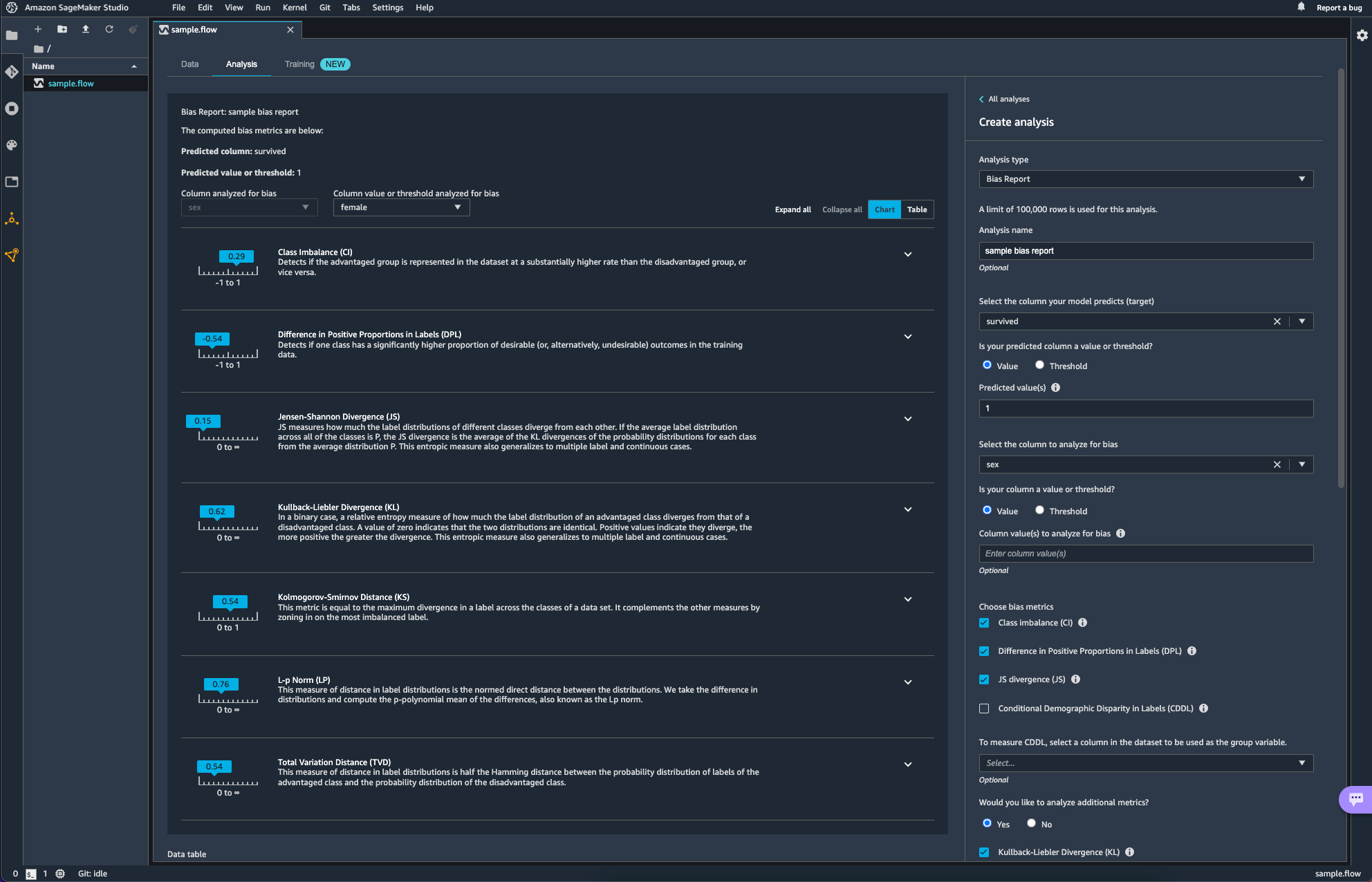
Quick Model이라는 항목도 있다. 빠르게 모델을 학습시켜 feature의 Importance를 매우 rough하게 보여주는 것 같다. 설명에도 쓰여있듯 fine tuning이나 feature selection optimization에도 활용하는 것을 추천하지는 않는다고 하니 대략적인 흐름을 잡는데에만 활용하면 될 듯하다.
위에 New라는 태그가 붙어있는 Training 항목의 경우, 사용하는 방법도 생소하고 AWS의 새로운 서비스를 활용해보려다 비용 폭탄을 맞은 경험이 있어 일단은 넘어가기로 하자. 나중에 조금 더 유명해지면 그때 가서 다시 살펴봐도 늦지 않을 듯 하다.
비용 폭탄이 발생하였던 서비스는 Canvas 라는 서비스이다. 심지어 서울 리전에는 서비스가 아직 제공되지 않아 도쿄 리전에서 실행해봤는데, codeless 한 ML/DL을 제공한다길래 눌렀더니, 아무것도 안해도 Launch App 클릭 한번에 비용이 계속 나가 3일에 대략 20만원 비스무리하게 나갔던 거 같다. 비용은 약간의 과장이 있을 수 있지만 그 비스무리하게 충격적이였다 ... ㅎ
파이프라인의 마무리 작업으로 S3 bucket에 업로드를 하며 data flow 쪽에서의 작업을 마무리하였다.
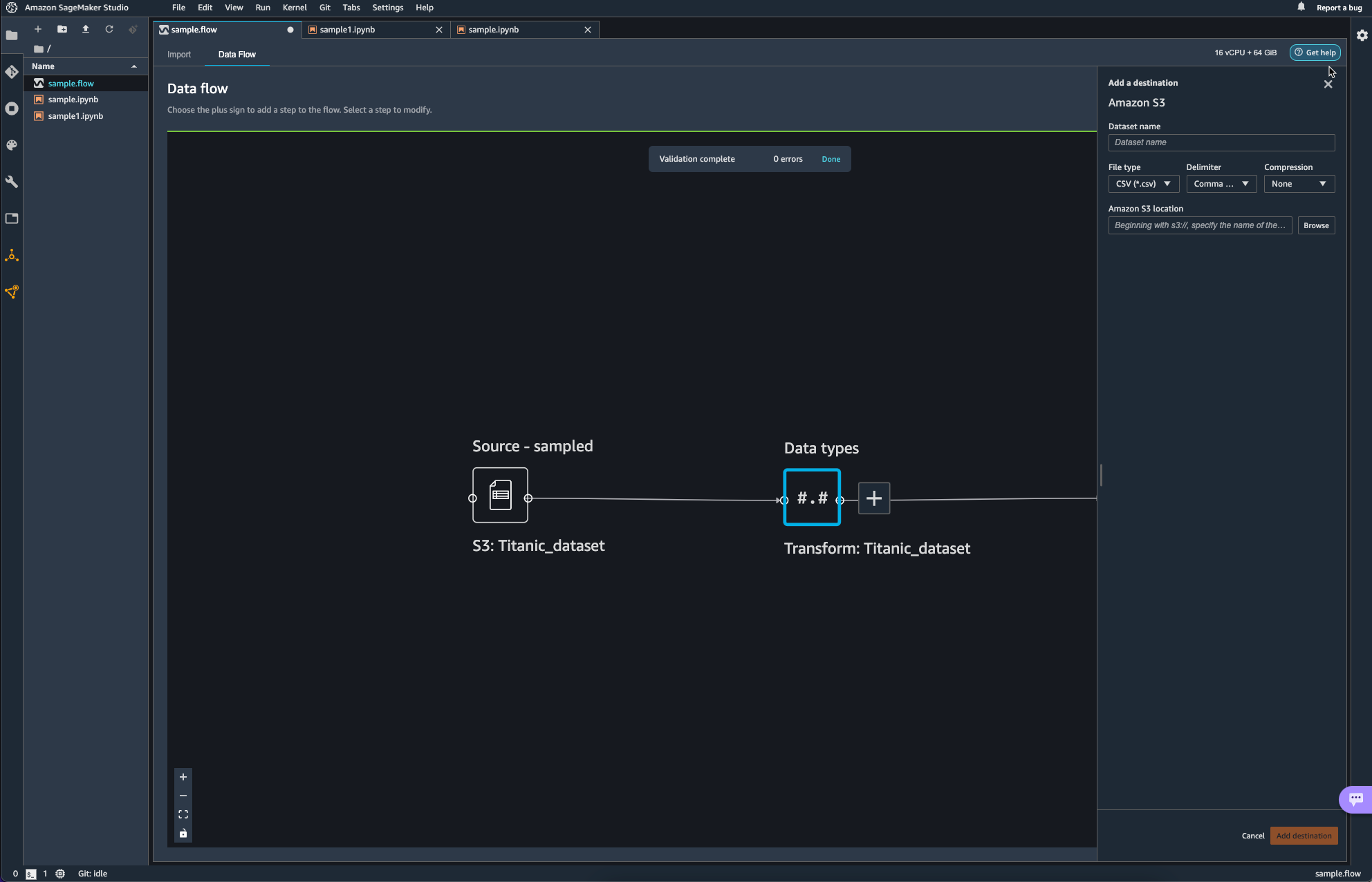
Destination이 추가된 모습이다.
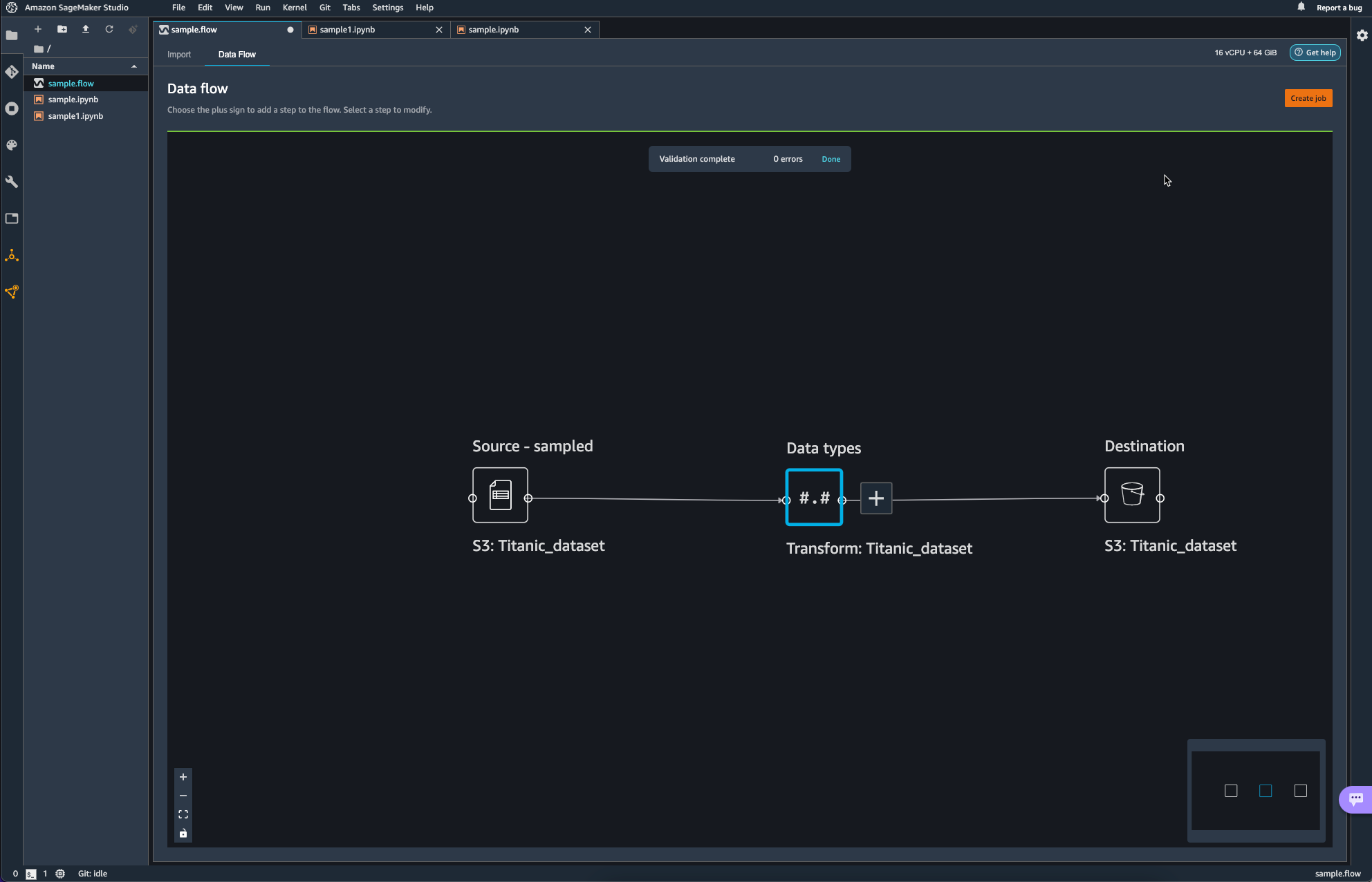
이제 Job을 생성하여 방금까지 생성하였던 Pipeline에 대해서 실제 작업이 일어나도록 해야한다.
오른쪽 상단의 Create Job을 통해 Pipeline Job을 Configure 한다.
이때 인스턴스는 여전히 ml.x5.4xlarge를 사용하는데, default는 2개를 사용하도록 되어 있다.
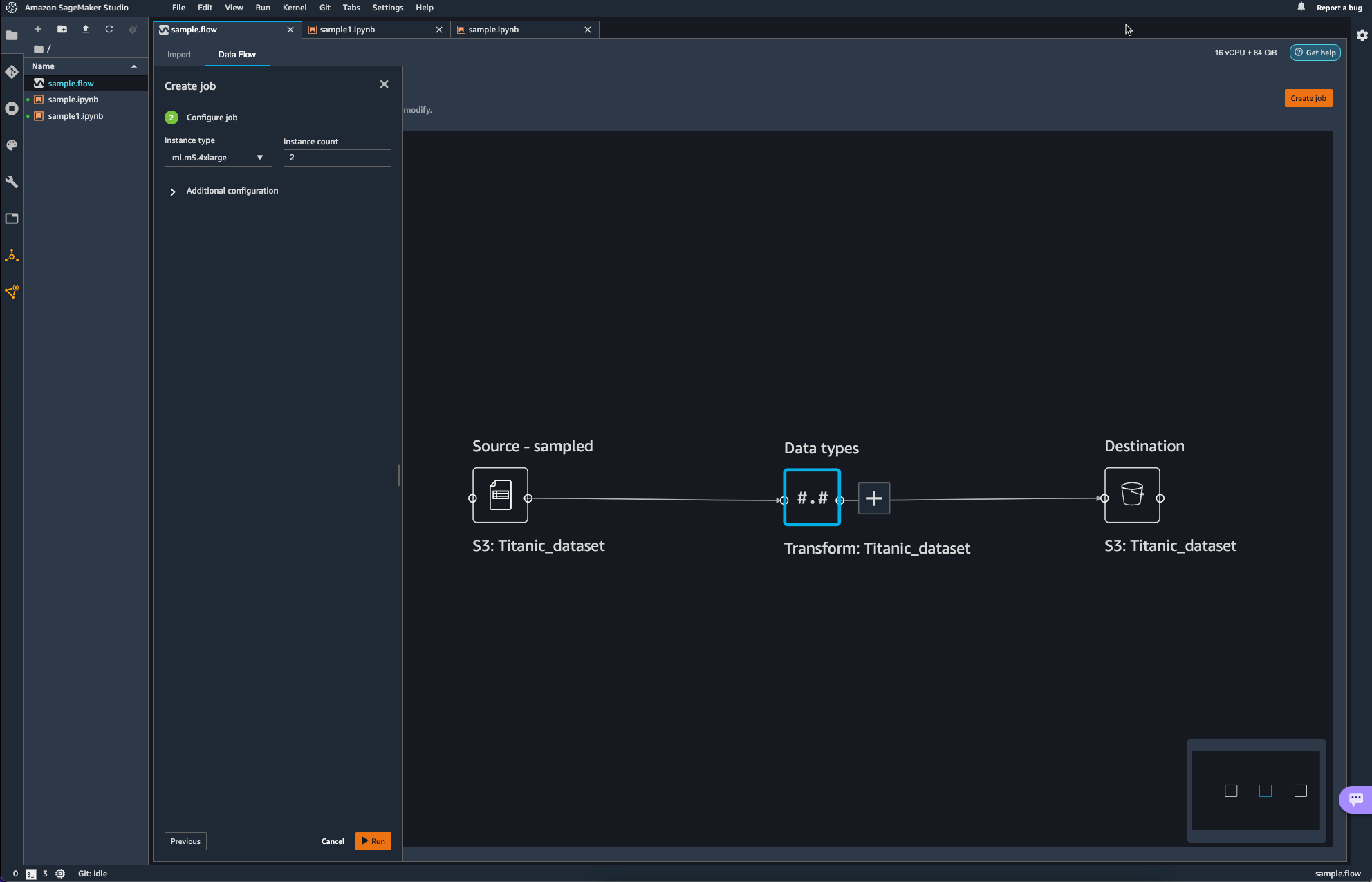
작업이 완료되면 다음과 같은 페이지를 통해 Completed를 안내받을 수 있다.
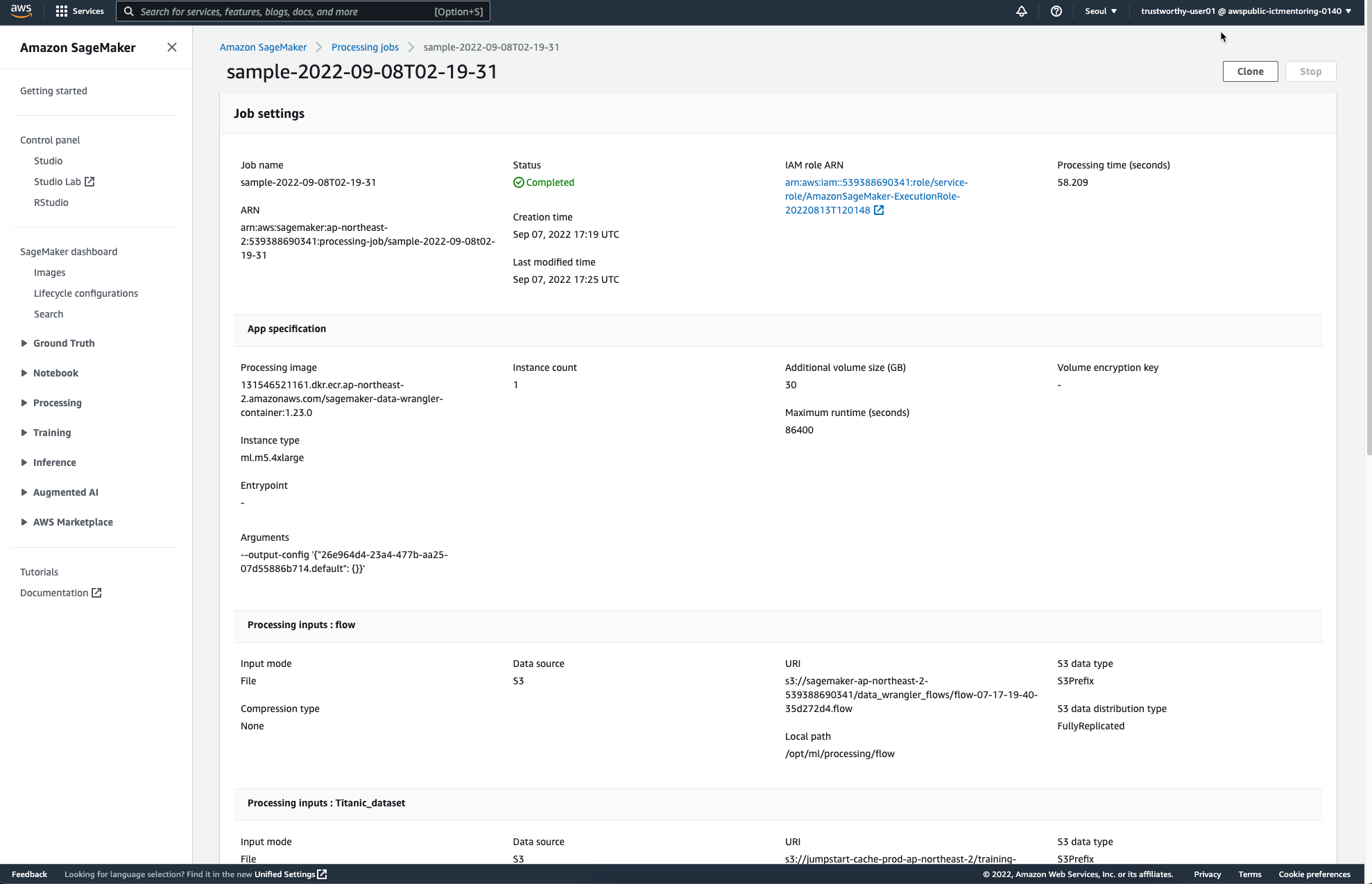
앞서 Job Configure를 통해 설정하였던 S3 Destination에는 다음과 같은 파일이 추가되었다.
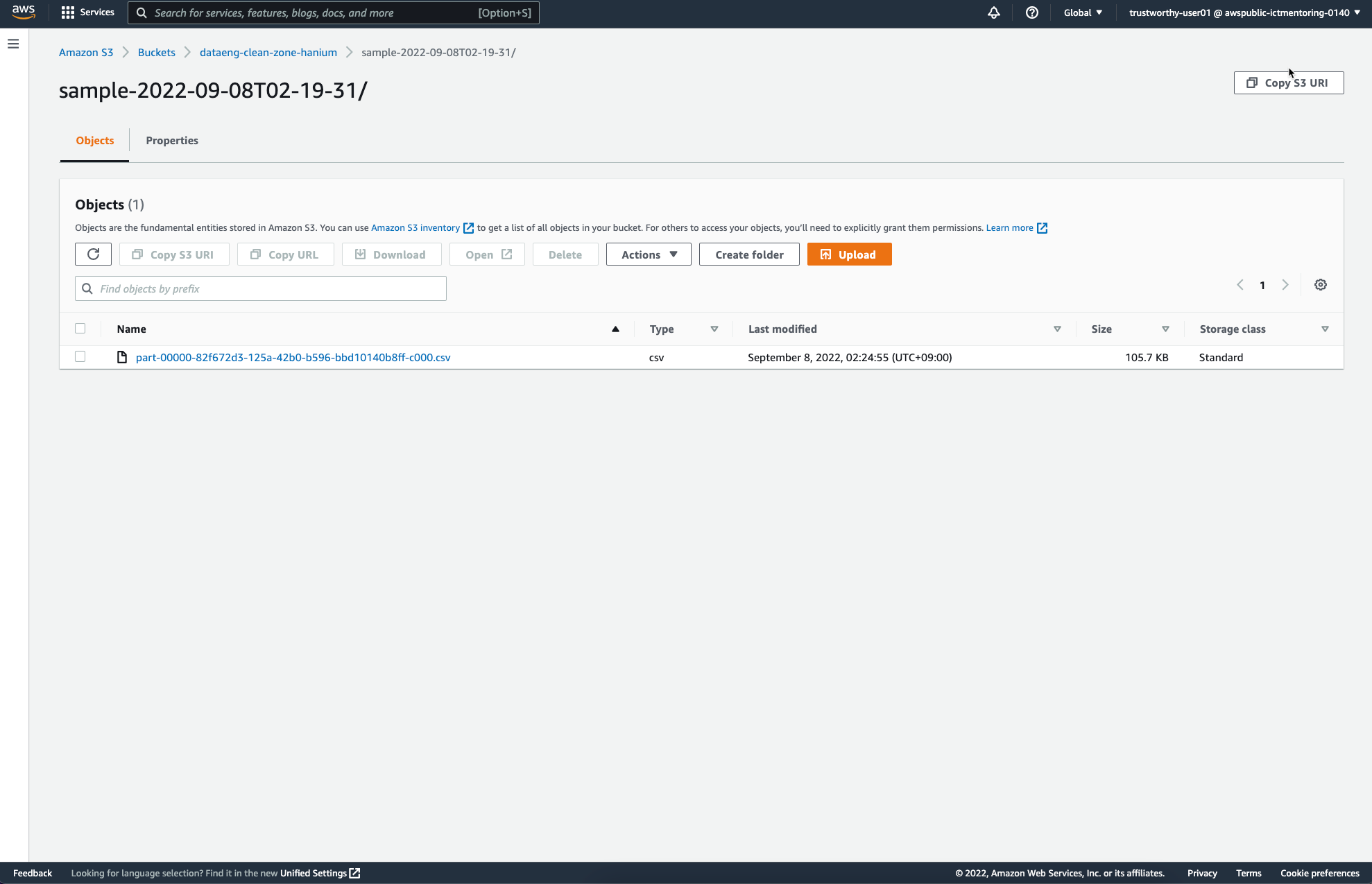
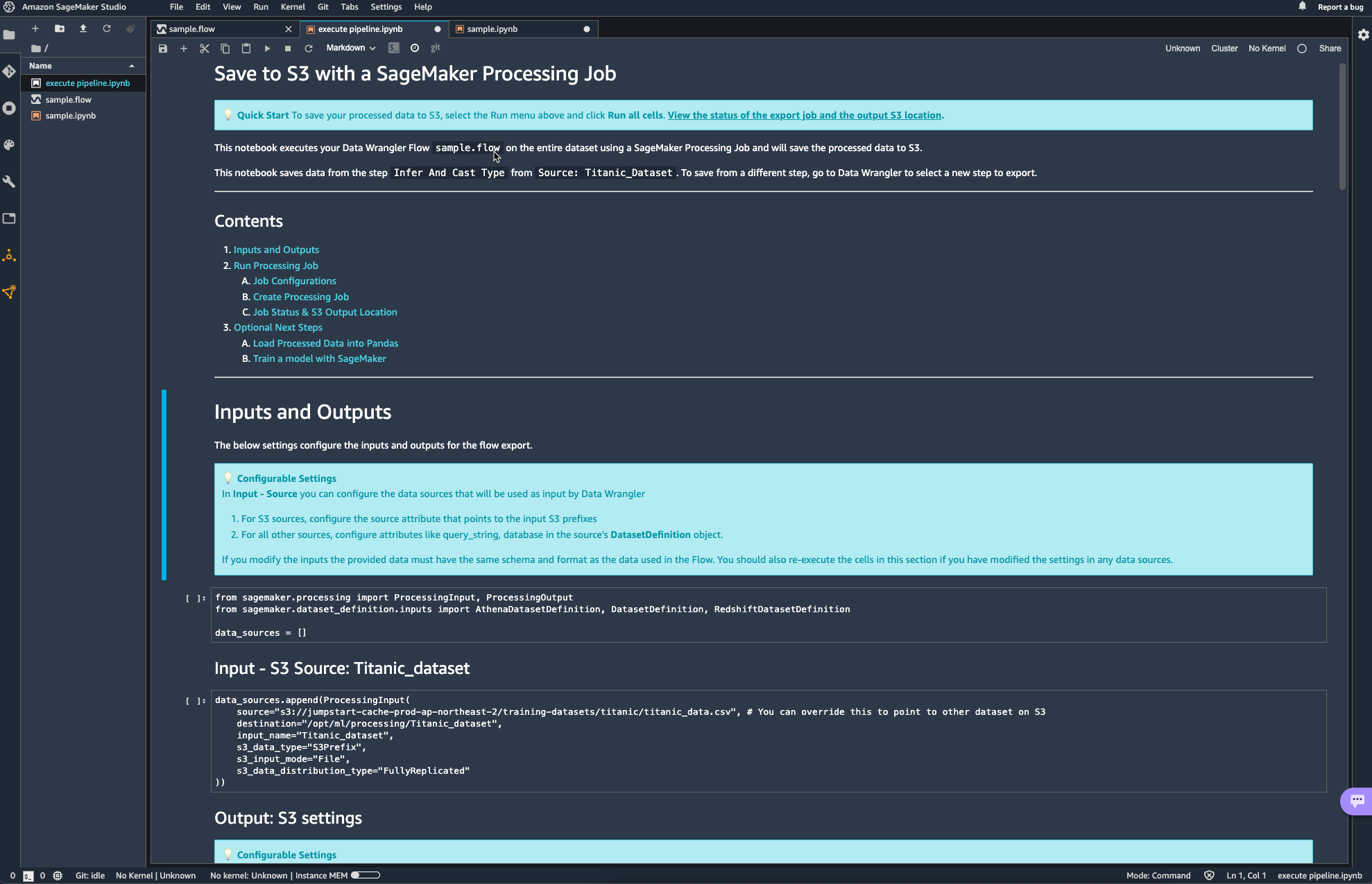
이 외에도 ipynb 노트북을 활용해서도 Data Wrangler flow를 실행할 수 있는데, 이때 자동으로 생성되는 노트북은 거의 대부분의 설정이 이미 되어있어 그냥 실행만 해도 되고, 버킷의 이름과 같은 사소한 정보들만 변경해주면 될 거 같다.
'DevOps > Cloud Service' 카테고리의 다른 글
| [Boto3] S3 bucket 생성 (0) | 2022.09.07 |
|---|---|
| [Boto3] S3 bucket 나열 (0) | 2022.09.07 |
| awscli 1.25.17 requires botocore==1.27.17, but you have botocore 1.27.66 which is incompatible. (0) | 2022.09.06 |
| [네이버 클라우드] 서버 생성 및 접근 (0) | 2022.05.28 |
import logging
import boto3
from botocore.exceptions import ClientError
- logging: 파이썬의 로깅을 위한 패키지이다.
- boto3: AWS의 파이썬 SDK이다. botocore를 사용자 관점에서 사용하기 쉽도록 추상화하였다.
- botocore: boto3의 기반이 되는 패키지이다. low-level interface라고 명시한다.
아래 함수는 bucket을 생성하는 간단한 함수이다.
def create_bucket(bucket_name, region=None):
"""Create an S3 bucket in a specified region
If a region is not specified, the bucket is created in the s3 defualt region (ap-northeast-2)
Args:
bucket_name (_type_): Bucket to create
region (_type_, optional): String region to create bucket in, e.g 'ap-northeast-2'. Defaults to None.
"""
# Create bucket
try:
if region is None:
s3_client = boto3.client('s3')
s3_client.create_bucket(Bucket=bucket_name)
except ClientError as err:
logging.error(err)
return False
return True
boto3.client('s3').create_bucket() 에는 두가지 argument가 가장 많이 활용된다.
- Bucket: 생성하고자 하는 버킷의 이름
- CreateBucketConfiguration: 버킷을 생성하고자 하는 리전 정보
Bucket의 경우, string으로 생성하고자 하는 버킷의 이름을 그대로 전달하면 된다.
CreateBucketConfiguration의 경우, 딕셔너리로 wrapping한 리전의 정보가 들어가야 한다.
이게 무슨 말이냐면, 다음과 같이 location이라는 딕셔너리를 먼저 구성하고 LocationConstraint라는 키에 region 값을 넣어주게 된다.
location = {'LocationConstraint': region}
s3_client.create_bucket(Bucket=name, CreateBucketConfiguration=location)
이때, argument 값은 항상 keyword argument로 제공되어야 한다.
location = {'LocationConstraint': region}
s3_client.create_bucket(Bucket=name, location)
----------------------------------------------
OUTPUT:
s3_client.create_bucket(Bucket=name, location) ^
SyntaxError: positional argument follows keyword argument
'DevOps > Cloud Service' 카테고리의 다른 글
| [SageMaker studio] Data Wrangler flow (0) | 2022.09.08 |
|---|---|
| [Boto3] S3 bucket 나열 (0) | 2022.09.07 |
| awscli 1.25.17 requires botocore==1.27.17, but you have botocore 1.27.66 which is incompatible. (0) | 2022.09.06 |
| [네이버 클라우드] 서버 생성 및 접근 (0) | 2022.05.28 |
헤더
import boto3리소스 가져오기
## 'ap-northeast'는 'seoul region' 을 의미한다.
s3_resource = boto3.client('s3', 'ap-northeast-2')
response = s3_resource.list_buckets()계정 내에 존재하는 버킷 리스트 출력
print("계정 내의 S3 버킷 리스트")
for bucket in response['Buckets']:
print(f'{bucket["Name"]}')Output:
계정 내의 S3 버킷 리스트
aws-glue-assets-539388690341-ap-northeast-2
dataeng-clean-zone-hanium
dataeng-landing-zone-hanium
hanium-trustworthyai-sources
itv-flights-2016
mass-shooting-athena
sagemaker-ap-northeast-1-539388690341
sagemaker-studio-539388690341-481jja1sjok
sagemaker-studio-539388690341-u2k7k0dbae
boto3.client('s3').list_buckets()를 출력해보면 다음과 같은 필드를 얻을 수 있다.
{
"ResponseMetadata": {
"RequestId": "A3P5SA28ZNXRXHTE",
"HostId": "J/+Z3CtQVjVqspi7x+KYUdscAA0uIkfFBfdHTV+Rv9gJPmzac2CZeVQVIIh8k/Pgm+bSfCpzWz4=",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"x-amz-id-2": "J/+Z3CtQVjVqspi7x+KYUdscAA0uIkfFBfdHTV+Rv9gJPmzac2CZeVQVIIh8k/Pgm+bSfCpzWz4=",
"x-amz-request-id": "A3P5SA28ZNXRXHTE",
"date": "Wed, 07 Sep 2022 12:12:00 GMT",
"content-type": "application/xml",
"transfer-encoding": "chunked",
"server": "AmazonS3"
},
"RetryAttempts": 0
},
"Buckets": [
{
"Name": "aws-glue-assets-539388690341-ap-northeast-2",
"CreationDate": "2022-07-07 03:18:43+00:00"
},
{
"Name": "dataeng-clean-zone",
"CreationDate": "2022-08-25 18:47:15+00:00"
},
{
...
"Owner": {
"ID": "f6ab8c78aba1c3a39c22ab469cvee113f2fc1c029fe123429230b0df4077d5e2d"
}
}
boto3.client('s3').list_buckets()['Buckets'] 값을 살펴보면, 다시 Name과 CreationDate로 나눠지는 모습을 확인할 수 있다.
이때, CreationDate의 시간 형식(tzinfo)는 tzutc 형식을 따른다.
2019-10-25 15:33:27.388853+0000 와 같은 형식을 tzutc time format이라고 한다.
'DevOps > Cloud Service' 카테고리의 다른 글
| [SageMaker studio] Data Wrangler flow (0) | 2022.09.08 |
|---|---|
| [Boto3] S3 bucket 생성 (0) | 2022.09.07 |
| awscli 1.25.17 requires botocore==1.27.17, but you have botocore 1.27.66 which is incompatible. (0) | 2022.09.06 |
| [네이버 클라우드] 서버 생성 및 접근 (0) | 2022.05.28 |
awscli 1.25.17 requires botocore==1.27.17, but you have botocore 1.27.66 which is incompatible.
에러 상황
$pip install botocore==1.27.17
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
boto3 1.24.66 requires botocore<1.28.0,>=1.27.66, but you have botocore 1.27.17 which is incompatible.
$pip install botocore==1.27.66
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
awscli 1.25.17 requires botocore==1.27.17, but you have botocore 1.27.66 which is incompatible.해결방법: 결국 재설치
$ pip3 install awscli --upgrade --user
$ pip3 uninstall botocore
$ pip3 uninstall botocore
$ pip3 install botocore
$ pip3 install boto3'DevOps > Cloud Service' 카테고리의 다른 글
| [SageMaker studio] Data Wrangler flow (0) | 2022.09.08 |
|---|---|
| [Boto3] S3 bucket 생성 (0) | 2022.09.07 |
| [Boto3] S3 bucket 나열 (0) | 2022.09.07 |
| [네이버 클라우드] 서버 생성 및 접근 (0) | 2022.05.28 |